基于情感词典的python情感分析
近期老师给我们安排了一个大作业,要求根据情感词典对微博语料进行情感分析。于是在网上狂找资料,看相关书籍,终于搞出了这个任务。现在做做笔记,总结一下本次的任务,同时也给遇到有同样需求的人,提供一点帮助。
1、情感分析含义
情感分析指的是对新闻报道、商品评论、电影影评等文本信息进行观点提取、主题分析、情感挖掘。情感分析常用于对某一篇新闻报道积极消极分析、淘宝商品评论情感打分、股评情感分析、电影评论情感挖掘。情感分析的内容包括:情感的持有者分析、态度持有者分析、态度类型分析(一系列类型如喜欢(like),讨厌(hate),珍视(value),渴望(desire)等;或着简单的加权极性如积极(positive),消极(negative)和中性(neutral)并可用具体的权重修饰)、态度的范围分析(包含每句话,某一段、或者全文)。因此,情感分析的目的可以分为:初级:文章的整体感情是积极/消极的;进阶:对文章的态度从1-5打分;高级:检测态度的目标,持有者和类型。
总的来说,情感分析就是对文本信息进行情感倾向挖掘。
2、情感挖掘方法
情感挖掘目前主要使用的方法是使用情感词典,对文本进行情感词匹配,汇总情感词进行评分,最后得到文本的情感倾向。本次我主要使用了两种方法进行情感分析。第一种:基于BosonNLP情感词典。该情感词典是由波森自然语言处理公司推出的一款已经做好标注的情感词典。词典中对每个情感词进行情感值评分,bosanNLP情感词典如下图所示:
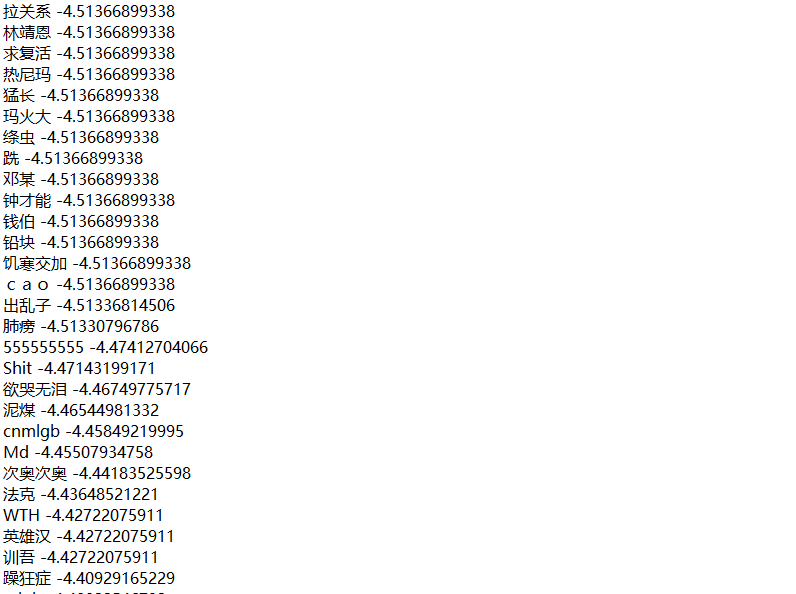
第二种,采用的是知网推出的情感词典,以及极性表进行情感分析。知网提供的情感词典共用12个文件,分为英文和中文。其中中文情感词典包括:评价、情感、主张、程度(正面、负面)的情感文本。本文将评价和情感词整合作为情感词典使用,程度词表中含有的程度词,按照等级区分,分为:most(最高)-very(很、非常)-more(更多、更)-ish(稍、一点点)-insufficiently(欠、不)-over(过多、多分、多)六个情感程度词典。
知网情感词典下载地址:- http://www.keenage.com/html/c_bulletin_2007.htm



3、原理介绍
3.1 基于BosonNLP情感分析原理
基于BosonNLP情感词典的情感分析较为简单。首先,需要对文本进行分句、分词,本文选择的分词工具为哈工大的pyltp。其次,将分词好的列表数据对应BosonNLp词典进行逐个匹配,并记录匹配到的情感词分值。最后,统计计算分值总和,如果分值大于0,表示情感倾向为积极的;如果小于0,则表示情感倾向为消极的。原理框图如下:

3.2 基于BosonNLP情感分析代码:
# -*- coding:utf-8 -*-
import pandas as pd
import jieba #基于波森情感词典计算情感值
def getscore(text):
df = pd.read_table(r"BosonNLP_dict\BosonNLP_sentiment_score.txt", sep=" ", names=['key', 'score'])
key = df['key'].values.tolist()
score = df['score'].values.tolist()
# jieba分词
segs = jieba.lcut(text,cut_all = False) #返回list
# 计算得分
score_list = [score[key.index(x)] for x in segs if(x in key)]
return sum(score_list) #读取文件
def read_txt(filename):
with open(filename,'r',encoding='utf-8')as f:
txt = f.read()
return txt
#写入文件
def write_data(filename,data):
with open(filename,'a',encoding='utf-8')as f:
f.write(data) if __name__=='__main__':
text = read_txt('test_data\微博.txt')
lists = text.split('\n') # al_senti = ['无','积极','消极','消极','中性','消极','积极','消极','积极','积极','积极',
# '无','积极','积极','中性','积极','消极','积极','消极','积极','消极','积极',
# '无','中性','消极','中性','消极','积极','消极','消极','消极','消极','积极'
# ]
al_senti = read_txt(r'test_data\人工情感标注.txt').split('\n')
i = 0
for list in lists:
if list != '':
# print(list)
sentiments = round(getscore(list),2)
#情感值为正数,表示积极;为负数表示消极
print(list)
print("情感值:",sentiments)
print('人工标注情感倾向:'+al_senti[i])
if sentiments > 0:
print("机器标注情感倾向:积极\n")
s = "机器判断情感倾向:积极\n"
else:
print('机器标注情感倾向:消极\n')
s = "机器判断情感倾向:消极"+'\n'
sentiment = '情感值:'+str(sentiments)+'\n'
al_sentiment= '人工标注情感倾向:'+al_senti[i]+'\n'
#文件写入
filename = 'result_data\BosonNLP情感分析结果.txt'
write_data(filename,'情感分析文本:')
write_data(filename,list+'\n') #写入待处理文本
write_data(filename,sentiment) #写入情感值
write_data(filename,al_sentiment) #写入机器判断情感倾向
write_data(filename,s+'\n') #写入人工标注情感
i = i+1
相关文件:
BosonNLp情感词典下载地址:https://bosonnlp.com/dev/resource
微博语料:链接:https://pan.baidu.com/s/1Pskzw7bg9qTnXD_QKF-4sg 提取码:15bu
输出结果:

3.3 基于知网情感词典的情感挖掘原理
基于知网情感词典的情感分析原理分为以下几步:
1、首先,需要对文本分句,分句,得到分词分句后的文本语料,并将结果与哈工大的停用词表比对,去除停用词;
2、其次,对每一句话进行情感分析,分析的方法主要为:判断这段话中的情感词数目,含有积极词,则积极词数目加1,含有消极词,则消极词数目加1。并且再统计的过程中还需要判断该情感词前面是否存在程度副词,如果存在,则需要根据程度副词的种类赋予不同的权重,乘以情感词数。如果句尾存在?!等符号,则情感词数目增加一定值,因为!与?这类的标点往往表示情感情绪的加强,因此需要进行一定处理。
3、接着统计计算整段话的情感值(积极词值-消极词值),得到该段文本的情感倾向。
4、最后,统计每一段的情感值,相加得到文章的情感值。
整体流程框图如下:

3.4 基于知网情感词典的情感分析代码:
import pyltp
from pyltp import Segmentor
from pyltp import SentenceSplitter
from pyltp import Postagger
import numpy as np #读取文件,文件读取函数
def read_file(filename):
with open(filename, 'r',encoding='utf-8')as f:
text = f.read()
#返回list类型数据
text = text.split('\n')
return text #将数据写入文件中
def write_data(filename,data):
with open(filename,'a',encoding='utf-8')as f:
f.write(str(data)) #文本分句
def cut_sentence(text):
sentences = SentenceSplitter.split(text)
sentence_list = [ w for w in sentences]
return sentence_list #文本分词
def tokenize(sentence):
#加载模型
segmentor = Segmentor() # 初始化实例
# 加载模型
segmentor.load(r'E:\tool\python\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data\cws.model')
# 产生分词,segment分词函数
words = segmentor.segment(sentence)
words = list(words)
# 释放模型
segmentor.release()
return words #词性标注
def postagger(words):
# 初始化实例
postagger = Postagger()
# 加载模型
postagger.load(r'E:\tool\python\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data\pos.model')
# 词性标注
postags = postagger.postag(words)
# 释放模型
postagger.release()
#返回list
postags = [i for i in postags]
return postags # 分词,词性标注,词和词性构成一个元组
def intergrad_word(words,postags):
#拉链算法,两两匹配
pos_list = zip(words,postags)
pos_list = [ w for w in pos_list]
return pos_list #去停用词函数
def del_stopwords(words):
# 读取停用词表
stopwords = read_file(r"test_data\stopwords.txt")
# 去除停用词后的句子
new_words = []
for word in words:
if word not in stopwords:
new_words.append(word)
return new_words # 获取六种权值的词,根据要求返回list,这个函数是为了配合Django的views下的函数使用
def weighted_value(request):
result_dict = []
if request == "one":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\most.txt")
elif request == "two":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\very.txt")
elif request == "three":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\more.txt")
elif request == "four":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\ish.txt")
elif request == "five":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\insufficiently.txt")
elif request == "six":
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\degree_dict\inverse.txt")
elif request == 'posdict':
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\emotion_dict\pos_all_dict.txt")
elif request == 'negdict':
result_dict = read_file(r"E:\学习笔记\NLP学习\NLP code\情感分析3\emotion_dict\neg_all_dict.txt")
else:
pass
return result_dict print("reading sentiment dict .......")
#读取情感词典
posdict = weighted_value('posdict')
negdict = weighted_value('negdict')
# 读取程度副词词典
# 权值为2
mostdict = weighted_value('one')
# 权值为1.75
verydict = weighted_value('two')
# 权值为1.50
moredict = weighted_value('three')
# 权值为1.25
ishdict = weighted_value('four')
# 权值为0.25
insufficientdict = weighted_value('five')
# 权值为-1
inversedict = weighted_value('six') #程度副词处理,对不同的程度副词给予不同的权重
def match_adverb(word,sentiment_value):
#最高级权重为
if word in mostdict:
sentiment_value *= 8
#比较级权重
elif word in verydict:
sentiment_value *= 6
#比较级权重
elif word in moredict:
sentiment_value *= 4
#轻微程度词权重
elif word in ishdict:
sentiment_value *= 2
#相对程度词权重
elif word in insufficientdict:
sentiment_value *= 0.5
#否定词权重
elif word in inversedict:
sentiment_value *= -1
else:
sentiment_value *= 1
return sentiment_value #对每一条微博打分
def single_sentiment_score(text_sent):
sentiment_scores = []
#对单条微博分句
sentences = cut_sentence(text_sent)
for sent in sentences:
#查看分句结果
# print('分句:',sent)
#分词
words = tokenize(sent)
seg_words = del_stopwords(words)
#i,s 记录情感词和程度词出现的位置
i = 0 #记录扫描到的词位子
s = 0 #记录情感词的位置
poscount = 0 #记录积极情感词数目
negcount = 0 #记录消极情感词数目
#逐个查找情感词
for word in seg_words:
#如果为积极词
if word in posdict:
poscount += 1 #情感词数目加1
#在情感词前面寻找程度副词
for w in seg_words[s:i]:
poscount = match_adverb(w,poscount)
s = i+1 #记录情感词位置
# 如果是消极情感词
elif word in negdict:
negcount +=1
for w in seg_words[s:i]:
negcount = match_adverb(w,negcount)
s = i+1
#如果结尾为感叹号或者问号,表示句子结束,并且倒序查找感叹号前的情感词,权重+4
elif word =='!' or word =='!' or word =='?' or word == '?':
for w2 in seg_words[::-1]:
#如果为积极词,poscount+2
if w2 in posdict:
poscount += 4
break
#如果是消极词,negcount+2
elif w2 in negdict:
negcount += 4
break
i += 1 #定位情感词的位置
#计算情感值
sentiment_score = poscount - negcount
sentiment_scores.append(sentiment_score)
#查看每一句的情感值
# print('分句分值:',sentiment_score)
sentiment_sum = 0
for s in sentiment_scores:
#计算出一条微博的总得分
sentiment_sum +=s
return sentiment_sum # 分析test_data.txt 中的所有微博,返回一个列表,列表中元素为(分值,微博)元组
def run_score(contents):
# 待处理数据
scores_list = []
for content in contents:
if content !='':
score = single_sentiment_score(content) # 对每条微博调用函数求得打分
scores_list.append((score, content)) # 形成(分数,微博)元组
return scores_list #主程序
if __name__ == '__main__':
print('Processing........')
#测试
# sentence = '要怎么说呢! 我需要的恋爱不是现在的样子, 希望是能互相鼓励的勉励, 你现在的样子让我觉得很困惑。 你到底能不能陪我一直走下去, 你是否有决心?是否你看不惯我?你是可以随意的生活,但是我的未来我耽误不起!'
# sentence = '转有用吗?这个事本来就是要全社会共同努力的,公交公司有没有培训到位?公交车上地铁站内有没有放足够的宣传标语?我现在转一下微博,没有多大的意义。'
sentences = read_file(r'test_data\微博.txt')
scores = run_score(sentences)
#人工标注情感词典
man_sentiment = read_file(r'test_data\人工情感标注.txt')
al_sentiment = []
for score in scores:
print('情感分值:',score[0])
if score[0] < 0:
print('情感倾向:消极')
s = '消极'
elif score[0] == 0:
print('情感倾向:中性')
s = '中性'
else:
print('情感倾向:积极')
s = '积极'
al_sentiment.append(s)
print('情感分析文本:',score[1])
i = 0
#写入文件中
filename = r'result_data\result_data.txt'
for score in scores:
write_data(filename, '情感分析文本:{}'.format(str(score[1]))+'\n') #写入情感分析文本
write_data(filename,'情感分值:{}'.format(str(score[0]))+'\n') #写入情感分值
write_data(filename,'人工标注情感:{}'.format(str(man_sentiment[i]))+'\n') #写入人工标注情感
write_data(filename, '机器情感标注:{}'.format(str(al_sentiment[i]))+'\n') #写入机器情感标注
write_data(filename,'\n')
i +=1
print('succeed.......')
输出结果:

4、小结
本次的情感分析程序完成简单的情感倾向判断,准确率上基于BosonNLP的情感分析较低,其情感分析准确率为:56.67%;而基于知网情感词典的情感分析准确率达到90%,效果上还是不错的。但是,这两个程序都还只是情感分析简单使用,并未涉及到更深奥的算法,如果想要更加精确,或者再更大样本中获得更高精度,这两个情感分析模型还是不够的。但是用来练习学习还是不错的选择。要想更深入的理解和弄得情感分析,还需要继续学习。
PS:需要基于知网情感词典的情感分析词典数据,可以在评论中留下你的邮箱,我发给你。
基于情感词典的python情感分析的更多相关文章
- Python 文本挖掘:使用情感词典进行情感分析(算法及程序设计)
出处:http://www.ithao123.cn/content-242299.html 情感分析就是分析一句话说得是很主观还是客观描述,分析这句话表达的是积极的情绪还是消极的情绪. 原理 比如 ...
- 详解基于朴素贝叶斯的情感分析及 Python 实现
相对于「 基于词典的分析 」,「 基于机器学习 」的就不需要大量标注的词典,但是需要大量标记的数据,比如: 还是下面这句话,如果它的标签是: 服务质量 - 中 (共有三个级别,好.中.差) ╮(╯-╰ ...
- 【Python情感分析】用python情感分析李子柒频道视频热门评论
一.事件背景 今天是2021.12.2日,距离李子柒断更已经4个多月了,这是我在YouTube李子柒油管频道上,观看李子柒2021年7月14日上传的最后一条视频,我录制了视频下方的来自全世界各国网友的 ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
- 基于flask的可视化动漫分析网站【python入门必学】
课程设计项目名称:基于flask的可视化动漫分析网站,如果你在学习Python的过程中,往往因为没有好的教程或者没人指导从而导致自己容易放弃,为此我建了个Python交流.裙 :一久武其而而流一思(数 ...
- (4.2)基于LingPipe的文本基本极性分析【demo】
酒店评论情感分析系统(四)—— 基于LingPipe的文本基本极性分析[demo] (Positive (favorable) vs. Negative (unfavorable)) 这篇文章为Lin ...
- Python股票分析系列——基础股票数据操作(二).p4
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第4部分.在本教程中,我们将基于Adj Close列创建烛台/ OHLC图,这将允许我介绍重新采 ...
- 语法设计——基于LL(1)文法的预测分析表法
实验二.语法设计--基于LL(1)文法的预测分析表法 一.实验目的 通过实验教学,加深学生对所学的关于编译的理论知识的理解,增强学生对所学知识的综合应用能力,并通过实践达到对所学的知识进行验证.通过对 ...
- 分享一个基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具
soar-web 基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具,支持 soar 配置的添加.修改.复制,多配置切换,配置的导出.导入与导入功能. 环境需求 python3.xF ...
随机推荐
- Ajax 简述与基础语法
目录 Ajax 1. 原生 JS 实现 Ajax 2. 使用 Ajax 实现异步通信 a. Ajax 的基础语法 b. 用 Ajax 传递数据 i. 传递字符串数据 ii. 传递 JSON 数据 3. ...
- cd命令使用
- 编写高质量Python程序(四)库
本系列文章为<编写高质量代码--改善Python程序的91个建议>的精华汇总. 按需选择 sort() 或者 sorted() Python 中常用的排序函数有 sort() 和 sort ...
- Numpy学习-(1)
记录我学习Numpy过程 1. 介绍 (1)NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库 ...
- Jmeter工具 组件简单认识
JMETER 所有的组件(元素)都是基于测试计划的,先有测试计划然后才有 JMETER 组件 JMETER 核心组件1.JMETER中的 Threads 类似与线程数,每一个线程数代表一个虚拟用户:测 ...
- HBase Filter 过滤器概述
abc 过滤器介绍 HBase过滤器是一套为完成一些较高级的需求所提供的API接口. 过滤器也被称为下推判断器(push-down predicates),支持把数据过滤标准从客户端下推到服务器,带有 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第九周作业
<Linux内核原理与分析>第九周作业 一.本周内容概述: 阐释linux操作系统的整体构架 理解linux系统的一般执行过程和进程调度的时机 理解linux系统的中断和进程上下文切换 二 ...
- Zabbix CPU utilization监控参数
工作中查看Zabbix linux 监控项的时候对linux 监控的cpu使用的各个参数没怎么明白,特意查看了下资料 Zabbix linux模板下的CPU utilization是自带的监控Linu ...
- JVM原理与深度调优(三)
jvm垃圾收集算法 1.引用计数算法每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收.此方法简单,无法解决对象相互循环引用的问题.还有一个问题是如何解决精准计 ...
- 标准库shelve
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ...