cuda基础
一:cuda编程模型
1:主机与设备
主机---CPU 设备/处理器---GPU
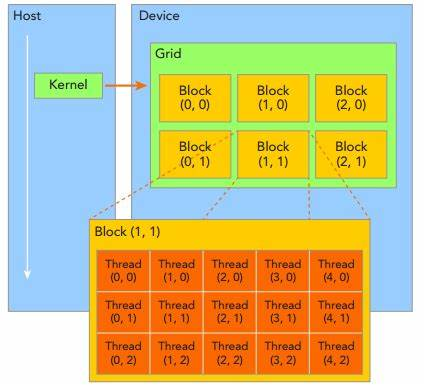
CUDA编程模型如下:
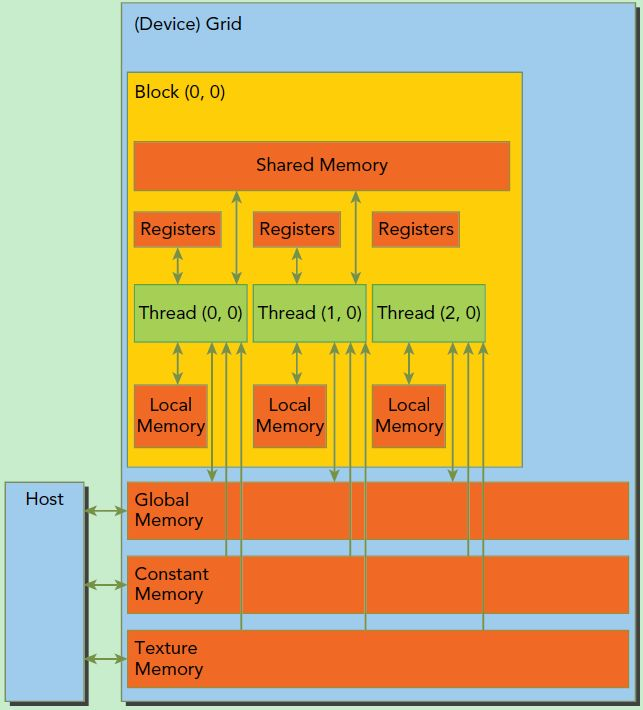
GPU多层存储空间结构如图:
2:Kernel函数的定义与调用
A:运行在GPU上,必须通过__global__函数类型限定符定义且只能在主机端代码中调用;
B:在调用时必须声明内核函数的执行参数----<<<>>>。
C:先为内核函数中用到的变量分配好足够空间再调用kernel函数
D:每个线程都有自己对应的id----由设备端的寄存器提供的内建变量保存,且是只读的。
3:线程结构
1)线程标识
dim3类型(基于uint3定义的矢量类型----由三个unsigned int组成的结构体)的内建变量threadIdx和blockIdx。
2)一维block
线程threadID----threadIdx.x.
3)二维block---(Dx,Dy)
线程threadID----threadIdx.x+threadIdx.y*Dx;
4)三维block---(Dx,Dy,Dz)
线程threadID----threadIdx.x+threadIdx.y*Dx+threadIdx.z*Dx*Dy;
4:硬件映射
1)计算单元
SM---流多处理器 SP---流处理器
A:一个SM包含8个SP,共用一块共享存储器
2)warp
线程束在采用Tesla架构的gpu中:一个线程束由32个线程组成,且其线程只和threadID有关
A:warp才是真正的执行单位
3)执行模型
SIMT---单指令多线程 SIMD---单指令多数据
4)deviceQuery实例
#include <stalib.h>
#include <stdio.h>
#include<string.h>
#include <cutil.h> int main()
{
int deviceCount;
CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount));
if( == deviceCount)
{
printf("no deice\n");
}
int dev;
for(dev = ;dev <deviceCount;dev++)
{
cudaDeviceProp deviceProp;
CUDA_SAFE_CALL(cudaGetDeviceProperties(&deviceProp,dev));
print();
}
}
5)cuda程序编写流程
A:主机端
启动CUDA,使用多卡时需加上设备号,或使用cudaSetDevice()设置
为输入数据分配空间
初始化输入数据
为GPU分配显存,用于存放输入数据
将内存中的输入数据拷贝到显存
为GPU分配显存,用于存放输出数据
调用device端的kernel进行计算,将结果写到显存中对应区域
为CPU分配内存,用于存放GPU传回来的输出数据
使用CPU对数据进行其他处理
释放内存和显存空间
退出CUDA
B:设备端
从显存读数据到GPU片内 对数据进行处理 将处理后的数据写回显存
(1)在显存全局内存分配线性空间--cudaMalloc()/cudaFree()
(2)拷贝存储器中的数据 --cudaMemcpy()
拷贝操作类型:cudaMemcpyDeiceToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToDevice
(3)网格定义
<<<Dg,Db,Ns,S>>>
Dg----grid纬度与尺寸 Db---block维度与尺寸 Ns--可分配动态共享内存大小 s--stream_t类型的可选参数
(4)设备端内建变量
gridDim blockIdx blockDim threadIdx warpSize
6)内核实例
A:与shared memory有关
__global__ void
testKernel(float* g_idata,float* g_odata)
{
//分配共享内存 将全局内存的数据写入共享内存 进行计算,将结果写入共享内存 将结果写回全局内存
extern __shared__ float sdata[];//动态分配共享内存空间--__device__ __global__函数中
//动态分配大小是执行参数中的第三个参数。当静态分配时必须指明大小 const unsigned int bid = blockIdx.x;
const unsigned int tid_in_block = threadIdx.x;
const unsigned int tid_in_grid = blockIdx.x*blockDim.x+threadIdx.x;
sdata[tid_in_block] = g_idata[tid_in_grid];
__syncthreads(); sdata[tid_in_block] *= (float)bid; __syncthreads(); g_odata[tid_in_grid] = sdata[tid_in_block];
}
cuda基础的更多相关文章
- CUDA基础介绍
一.GPU简介 1985年8月20日ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年4月ATi发布了Mach32图形卡集成了图形加速功能,1998年4月ATi ...
- 【CUDA 基础】6.5 流回调
title: [CUDA 基础]6.5 流回调 categories: - CUDA - Freshman tags: - 流回调 toc: true date: 2018-06-20 21:56:1 ...
- 【CUDA 基础】6.3 重叠内和执行和数据传输
title: [CUDA 基础]6.3 重叠内和执行和数据传输 categories: - CUDA - Freshman tags: - 深度优先 - 广度优先 toc: true date: 20 ...
- 【CUDA 基础】6.1 流和事件概述
title: [CUDA 基础]6.1 流和事件概述 categories: - CUDA - Freshman tags: - 流 - 事件 toc: true date: 2018-06-10 2 ...
- 【CUDA 基础】6.2 并发内核执行
title: [CUDA 基础]6.2 并发内核执行 categories: - CUDA - Freshman tags: - 流 - 事件 - 深度优先 - 广度优先 - 硬件工作队列 - 默认流 ...
- 【CUDA 基础】6.0 流和并发
title: [CUDA 基础]6.0 流和并发 categories: - CUDA - Freshman tags: - 流 - 事件 - 网格级并行 - 同步机制 - NVVP toc: tru ...
- 【CUDA 基础】5.6 线程束洗牌指令
title: [CUDA 基础]5.6 线程束洗牌指令 categories: - CUDA - Freshman tags: - 线程束洗牌指令 toc: true date: 2018-06-06 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- 【CUDA 基础】5.2 共享内存的数据布局
title: [CUDA 基础]5.2 共享内存的数据布局 categories: - CUDA - Freshman tags: - 行主序 - 列主序 toc: true date: 2018-0 ...
随机推荐
- JavaWeb学习之JSP(二) JSP标签
JSP常用标签 什么是JSP标签 JSP标签,有的地方也叫做JSP动作,在JSP中编写大量的java代码会使JSP页面显得杂乱无章,看起来非常不舒服,因此JSP提供了一些类似html的标签,通过这些标 ...
- 【前端背景UI】鼠标磁性动态蜘蛛网背景源码
<div style="float:right;" id="hub_iframe"></div> <script type=&qu ...
- python机器学习(三)分类算法-朴素贝叶斯
一.概率基础 概率定义:概率定义为一件事情发生的可能性,例如,随机抛硬币,正面朝上的概率. 联合概率:包含多个条件,且所有条件同时成立的概率,记作:
- Java创建线程的方式
Java中线程的创建有四i种方式: 1. 通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中 2. 通过实现Runnable接口,实例化Thread类 3.应用程序 ...
- 你 MySQL 中重复数据多吗,教你一招优雅的处理掉它们!
在需要保证数据唯一性的场景中,个人觉得任何使用程序逻辑的重复校验都是不可靠的,这时只能在数据存储层做唯一性校验.MySQL 中以唯一键保证数据的唯一性,那么若新插入重复数据时,我们可以让 MySQL ...
- Django数据库表初始化缓存清除
新建的django项目中没有应用app01??? models中也没有UserInfo表???? 但在migrate是却一直报错!!!!! 产生此种现象的原因: 之前的项目中肯定是用到过应用app01 ...
- import * as x from 'xx' 和 import x from 'xx'
普通xx.js文件 //不可变的依赖模拟数据 module.exports=[ { id: "d52dccfc-656d-11e8-b153-7cd30ad3aa7a", regi ...
- C:习题2
C 语言中的数据类型主要有哪些? C 语言为什么要规定对所有用到的变量“先定义后使用”?这样做有什么好处? 1. 编译系统会根据定义为变量分配内存空间,分配空间的大小与数据类型有关 2. 系统可以根据 ...
- poj2914无向图的最小割
http://blog.csdn.net/vsooda/article/details/7397449 //算法理论 http://www.cnblogs.com/ylfdrib/archive/20 ...
- EL表达式用法---查询博客
jsp脚本:<%=request.getAttribute(name)%>EL表达式替代上面的脚本:${requestScope.name} 使用EL最主要的作用是获得四大域中的数据,格式 ...