cuda基础
一:cuda编程模型
1:主机与设备
主机---CPU 设备/处理器---GPU
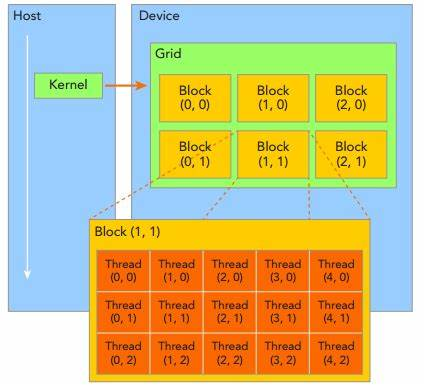
CUDA编程模型如下:
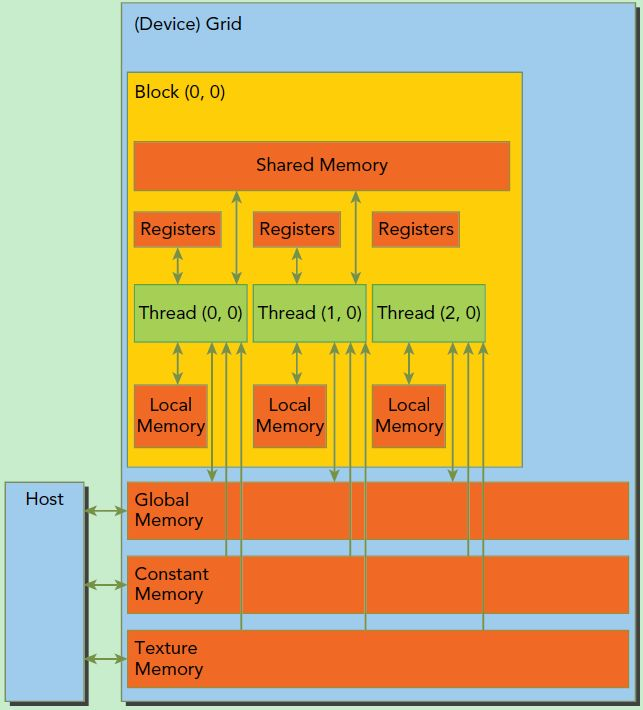
GPU多层存储空间结构如图:
2:Kernel函数的定义与调用
A:运行在GPU上,必须通过__global__函数类型限定符定义且只能在主机端代码中调用;
B:在调用时必须声明内核函数的执行参数----<<<>>>。
C:先为内核函数中用到的变量分配好足够空间再调用kernel函数
D:每个线程都有自己对应的id----由设备端的寄存器提供的内建变量保存,且是只读的。
3:线程结构
1)线程标识
dim3类型(基于uint3定义的矢量类型----由三个unsigned int组成的结构体)的内建变量threadIdx和blockIdx。
2)一维block
线程threadID----threadIdx.x.
3)二维block---(Dx,Dy)
线程threadID----threadIdx.x+threadIdx.y*Dx;
4)三维block---(Dx,Dy,Dz)
线程threadID----threadIdx.x+threadIdx.y*Dx+threadIdx.z*Dx*Dy;
4:硬件映射
1)计算单元
SM---流多处理器 SP---流处理器
A:一个SM包含8个SP,共用一块共享存储器
2)warp
线程束在采用Tesla架构的gpu中:一个线程束由32个线程组成,且其线程只和threadID有关
A:warp才是真正的执行单位
3)执行模型
SIMT---单指令多线程 SIMD---单指令多数据
4)deviceQuery实例
#include <stalib.h>
#include <stdio.h>
#include<string.h>
#include <cutil.h> int main()
{
int deviceCount;
CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount));
if( == deviceCount)
{
printf("no deice\n");
}
int dev;
for(dev = ;dev <deviceCount;dev++)
{
cudaDeviceProp deviceProp;
CUDA_SAFE_CALL(cudaGetDeviceProperties(&deviceProp,dev));
print();
}
}
5)cuda程序编写流程
A:主机端
启动CUDA,使用多卡时需加上设备号,或使用cudaSetDevice()设置
为输入数据分配空间
初始化输入数据
为GPU分配显存,用于存放输入数据
将内存中的输入数据拷贝到显存
为GPU分配显存,用于存放输出数据
调用device端的kernel进行计算,将结果写到显存中对应区域
为CPU分配内存,用于存放GPU传回来的输出数据
使用CPU对数据进行其他处理
释放内存和显存空间
退出CUDA
B:设备端
从显存读数据到GPU片内 对数据进行处理 将处理后的数据写回显存
(1)在显存全局内存分配线性空间--cudaMalloc()/cudaFree()
(2)拷贝存储器中的数据 --cudaMemcpy()
拷贝操作类型:cudaMemcpyDeiceToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToDevice
(3)网格定义
<<<Dg,Db,Ns,S>>>
Dg----grid纬度与尺寸 Db---block维度与尺寸 Ns--可分配动态共享内存大小 s--stream_t类型的可选参数
(4)设备端内建变量
gridDim blockIdx blockDim threadIdx warpSize
6)内核实例
A:与shared memory有关
__global__ void
testKernel(float* g_idata,float* g_odata)
{
//分配共享内存 将全局内存的数据写入共享内存 进行计算,将结果写入共享内存 将结果写回全局内存
extern __shared__ float sdata[];//动态分配共享内存空间--__device__ __global__函数中
//动态分配大小是执行参数中的第三个参数。当静态分配时必须指明大小 const unsigned int bid = blockIdx.x;
const unsigned int tid_in_block = threadIdx.x;
const unsigned int tid_in_grid = blockIdx.x*blockDim.x+threadIdx.x;
sdata[tid_in_block] = g_idata[tid_in_grid];
__syncthreads(); sdata[tid_in_block] *= (float)bid; __syncthreads(); g_odata[tid_in_grid] = sdata[tid_in_block];
}
cuda基础的更多相关文章
- CUDA基础介绍
一.GPU简介 1985年8月20日ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年4月ATi发布了Mach32图形卡集成了图形加速功能,1998年4月ATi ...
- 【CUDA 基础】6.5 流回调
title: [CUDA 基础]6.5 流回调 categories: - CUDA - Freshman tags: - 流回调 toc: true date: 2018-06-20 21:56:1 ...
- 【CUDA 基础】6.3 重叠内和执行和数据传输
title: [CUDA 基础]6.3 重叠内和执行和数据传输 categories: - CUDA - Freshman tags: - 深度优先 - 广度优先 toc: true date: 20 ...
- 【CUDA 基础】6.1 流和事件概述
title: [CUDA 基础]6.1 流和事件概述 categories: - CUDA - Freshman tags: - 流 - 事件 toc: true date: 2018-06-10 2 ...
- 【CUDA 基础】6.2 并发内核执行
title: [CUDA 基础]6.2 并发内核执行 categories: - CUDA - Freshman tags: - 流 - 事件 - 深度优先 - 广度优先 - 硬件工作队列 - 默认流 ...
- 【CUDA 基础】6.0 流和并发
title: [CUDA 基础]6.0 流和并发 categories: - CUDA - Freshman tags: - 流 - 事件 - 网格级并行 - 同步机制 - NVVP toc: tru ...
- 【CUDA 基础】5.6 线程束洗牌指令
title: [CUDA 基础]5.6 线程束洗牌指令 categories: - CUDA - Freshman tags: - 线程束洗牌指令 toc: true date: 2018-06-06 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- 【CUDA 基础】5.2 共享内存的数据布局
title: [CUDA 基础]5.2 共享内存的数据布局 categories: - CUDA - Freshman tags: - 行主序 - 列主序 toc: true date: 2018-0 ...
随机推荐
- (Python基础教程之十三)Python中使用httplib2 – HTTP GET和POST示例
Python基础教程 在SublimeEditor中配置Python环境 Python代码中添加注释 Python中的变量的使用 Python中的数据类型 Python中的关键字 Python字符串操 ...
- abp(net core)+easyui+efcore实现仓储管理系统——入库管理之十二(四十八)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- 科技感满满,华为云DevCloud推出网页暗黑模式
近期,华为云DevCloud推出了暗黑模式,让用户在网页端也可以体验到桌面级应用才有的特性. 深色模式(Dark Mode),俗称暗黑模式.是近2年以来用户呼声最高的功能之一,一些国外顶级厂商都将 ...
- TCP三次握手的seq和ack号的【正确】理解
1 理论知识 先上一张图,TCP/IP详解第18章的这张图描述了一个正常的三次握手和四次挥手的状态迁移,以及seq.ack序号的变化. 基本状态看图就能了解,本文主要围绕序号的变化进行讲解. 1)se ...
- 如何分析和提高(C/C++)程序的编译速度?
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://www.cnblogs.com/lihuidashen/p/129354 ...
- Linux 下批量杀死进程
ps aux|grep python|grep -v grep|cut -c 9-15|xargs kill -15 管道符“|”用来隔开两个命令,管道符左边命令的输出会作为管道符右边命令的输入.下面 ...
- WordPress获取某个分类关联的标签
我在WordPress后台某篇文章的编辑页面,给这篇文章选择了分类:WordPress,接着同时选择了标签:php.主题制作,这时分类(WordPress)就与标签(php.主题制作)建立了关联,利用 ...
- WordPress美化百度分享默认图标
因代码中使用了Font Awesome字体图标,如果你的主题没有加载字体图标,可以到WP后台--插件--安装插件页面搜索:Font Awesome 4 Menus 安装并启用,才能显示替换后的图标. ...
- 已解决[Authentication failed for token submission,Illegal hexadecimal charcter s at index 1]
在初次学习使用shiro框架的时候碰到了这个问题,具体报错情况如下: [org.apache.shiro.authc.AbstractAuthenticator] - Authentication f ...
- [PHP学习教程 - 网络]003.获得当前访问的页面URL(Current Request URL)
引言:获取当前请求的URL路径,自动判断协议(HTTP or HTTPS). 一句话的事情,下面直接上高清无MSK的精妙代码! 功能函数 获得当前请求的页面路径(URL)地址 语法:$url = ge ...