AI 领域与概述
概述
数据分析行业主要的职业发展。
- 业务:业务分析师、数据产品经理、产品总监
- 技术:算法师、架构师、研发经理、研发总监
- 美工:BI工程师
人工智能,是数据分析的子集。人工智能主要包括
- 语音识别
- 自然语言处理
- 图像处理
- 专家系统
语音识别
语音转化为文字。技术已经相对成熟。
自然语言处理
对文本进行分析。主要有:
- 基于词
- 中文分词
- 关键词提取
- 命名实体识别
- 词性标注
- 句子
- 指代消解
- 依存句法
- 段落。意图识别
- 篇章。文本分类、聚类
词-中文分词
分词用的库:Jieba, SnowNLP, PKUseg, THULAC, HanLP, FoolNLTK, LTP, CoreNLP
如,jieba:
import jieba
text='小明硕士毕业于中国科学院计算所,后在日本京都大学深造'
seg_list=jieba.cut(text,cut_all=False)
print("Precise Mode:"+"/".join(seg_list))
seg_list=jieba.cut(text,cut_all=True)
print("cut all Mode:"+"/".join(seg_list))
seg_list=jieba.cut_for_search(text) #搜索引擎模式
print("Search Mode:"+"/".join(seg_list))
输出:
Precise Mode:小明/硕士/毕业/于/中国科学院/计算所/,/后/在/日本京都大学/深造
cut all Mode:小/明/硕士/毕业/于/中国/中国科学院/科学/科学院/学院/计算/计算所///后/在/日本/日本京都大学/京都/京都大学/大学/深造
Search Mode:小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
词-关键词提取
TOPN, TF-IDF
TF-IDF是TF(词频)和IDF(Inverse document frequency)逆向文件频率。
TF是一个词出现次数,除以总词数。如
英国在一文中出现3词,总次数是100,那么起TF就是0.03.IDF是总文件数,除以包含这词的文件数,取log10。如
英国在1000篇文章中出现,总文章数是10 000 000, 其IDF就是4。两者相乘,就是TF-IDF
# from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
txt1='水仙花 多少钱'
txt2='白玫瑰 多少钱'
txt3='向日葵 多少钱'
corpus = [txt1,txt2,txt3]
vectorizer=CountVectorizer()
transformer=TfidfTransformer()
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))
word=vectorizer.get_feature_names()
weight=tfidf.toarray()
for i in range(len(weight)):
print('——————这里输出第',i,u"类文本的词语tf-idf权重——————")
for j in range(len(word)):
print(word[j],weight[i][j])
结果是:
——————这里输出第 0 类文本的词语tf-idf权重——————
向日葵 0.0
多少钱 0.5085423203783267
水仙花 0.8610369959439764
白玫瑰 0.0
——————这里输出第 1 类文本的词语tf-idf权重——————
向日葵 0.0
多少钱 0.5085423203783267
水仙花 0.0
白玫瑰 0.8610369959439764
——————这里输出第 2 类文本的词语tf-idf权重——————
向日葵 0.8610369959439764
多少钱 0.5085423203783267
水仙花 0.0
白玫瑰 0.0
其中vectorizer的作用是把句子向量化。
| 向日葵 | 多少钱 | 水仙花 | 白玫瑰 | |
|---|---|---|---|---|
| 句子1 | 0 | 1 | 1 | 0 |
| 句子2 | 0 | 1 | 0 | 1 |
| 句子3 | 1 | 1 | 0 | 0 |
这样可供TfidfTransformer 计算。
词-命名实体识别
粘合:人名吗、地名、机构名、品牌名等
例如:我今年在三里屯买了个苹果。
三里屯、苹果
使用隐马尔科夫模型。
HMM隐马尔科夫模型
HMM的论文:http://www.cs.ubc.ca/~murphyk/Bayes/rabiner.pdf
包括:
- OBS 显现层
- STATES 隐含层
- Start_p 初始概率
- Trans_p 转移概率
- Emit_p 发射概率
目前该模型在scikit已经停用。http://scikit-learn.sourceforge.net/stable/modules/hmm.html
例子:一个北京的朋友,每天根据天气(下雨、晴天),决定当天的活动(散步、购物、清理房间),他在朋友圈里发了一条信息:我前天在公园散步,昨天购物,今天清理房间了!根据他的消息推断北京三天的天气。
这个例子中,
- OBS:散步、购物、清理
- STATES:下雨、晴天
- startp:P(下雨),P(晴天)
- transp:之前下雨,下次下雨、晴天。之前晴天,下次下雨、晴天的概率。
- emitp:下雨、晴天情况下,OBS的三个概率。
HMM:
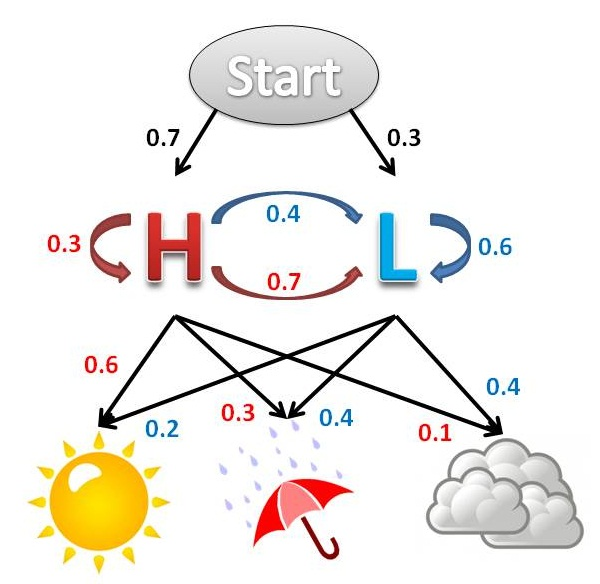
维比特算法
句-指代消解
例子:我今天在三里屯买了一个苹果,那个苹果很好吃。
那个指代。
句-依存句法
我 买了 苹果
今天 在 三里屯 很好吃
段、文-意图识别
垃圾邮件。文本分类、聚类。
图像处理
待填坑
专家系统
底层知识图谱。
Natrural Langugage processing with python
哪个领域->目录形式->目录下机器能计算的规则。
知识图谱包括:
- 实体:具有可区别、独立存在的事物。动物、数据库、程序中的对象
- 属性:实体的特征:姓名、身高、体重
- 属性值:描述特征的数值:张三、180, Key-value
- 关系:连接两个实体
如何用知识图谱,解决无监督分类。
- 从文本中提取哪些信息
- 提取的信息该如何排列
每个行业、公司的图谱不同。
数据预处理(文本)
- repalce
- 正则
- 批量字符串替换
- 批量正则字符串替换
replace
infile = open(r'./data/a1.txt','r',encoding='utf-8').read()
new_infile = infile.replace("坐席","AAA")
outfile=open(r'./data/a1.txt','w+',encoding='utf-8')
outfile.write(str(new_infile))
outfile.close
r 读 w 写覆盖 a 写追加
read() 按字符读。readlines() 按行读
图像识别。对图像进行分析
专家系统。底层知识图谱集合
一、
svm, 逻辑回归区别和联系?
- 联系:擅长二分类
- 区别: SVM找到一条线划分数据集中最近的两点。逻辑回归是,一根线到两侧全局点的距离最大。
二、
HMM隐马尔科夫模型是做什么的?
- 做词语粘合
AI 领域与概述的更多相关文章
- 社群公会GangSDK:程序员入行AI领域需要哪些技能?
作为一名Android开发工程师,身边总有些同行很焦虑,看着人工智能越来越火,总是担心Android要不行了,所以,我们需要转行么?Android还能走多久?其实,无论是对于Android还是iOS开 ...
- 2018年终总结之AI领域开源框架汇总
2018年终总结之AI领域开源框架汇总 [稍显活跃的第一季度] 2018.3.04——OpenAI公布 “后见之明经验复现(Hindsight Experience Reply, HER)”的开源算法 ...
- 高盛为什么认为中国AI领域将超越美国?
不久前,高盛发布的名为<中国在人工智能领域崛起>的研究报告,报告中,高盛认为中国已经成为AI领域的主要竞争者,中国政府建设“智慧型经济”和“智慧社会”的目标将有可能推动中国未来GDP的增长 ...
- 2019年最值得关注的AI领域技术突破及未来展望
选自venturebeat 翻译:魔王.一鸣 前言 AI 领域最杰出的头脑如何总结 2019 年技术进展,又如何预测 2020 年发展趋势呢?本文介绍了 Soumith Chintala.Celest ...
- AI领域有什么职业?怎样才能在AI领域找到工作?
AI领域是一个很吃香的行业,在这个行业中,很多人都是高薪的,而且有些学生为了以后能够接触到这个行业,都在大学的时候,学习这个专业,那么大家知道AI领域有什么职业吗?下面我们就来给大家讲解一下. 1.算 ...
- 最新SCI影响因子发布!Nature屠榜,AI领域Top 1000期刊盘点
[导读]2018年度SCI期刊影响因子最新发布,Nature.Science.Cell三大神刊排名前列.新智元摘取其中有关人工智能.机器学习.计算机视觉.机器人学等领域的期刊并做简要介绍,希望对读者选 ...
- AI学习--机器学习概述
学习框架 01-人工智能概述 机器学习.人工智能与深度学习的关系 达特茅斯会议-人工智能的起点 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来(人工神经网络) 从图上可以看出,人 ...
- 为什么在AI领域网络安全更重要?先睹为快~
AI迎来了改变世界的新机遇,同时也迎来了新的网络安全问题,只要是联网的系统就会有漏洞爆出~ 随着大数据的应用,人工智能逐渐走入千家万户并显示出巨大的市场空间,从机器人客服.自动驾驶汽车到无人机等,全都 ...
- 获 Linux 支持的开源指令集 RISC-V 投身存储和 AI 领域
EETimes 消息,WD 宣布将在 RISC-V 处理器上实现标准化,并投资了一家初创公司 Esperanto Technologies —— 该公司主要采用开源指令集架构设计高级 SoC 和核心. ...
随机推荐
- js数据类型 判断
1. js数据类型(两种数据类型) 基本数据类型:null undefined number boolean symbol string 引用数据类型: array object null: 空对象 ...
- 实训30 延时中断组织块0B20仿真
实训30 延时中断组织块的仿真试验 问题1 系统功能块SFC中提供了一些查询中断状态字的指令,举例说明 例如 SF34 "QRY_DINT" 用来查询 "延时中断&q ...
- P1053 住房空置率
P1053 住房空置率 转跳点:
- 洛谷 P2426 删数
题目传送门 解题思路: 区间DP,f[i][j]表示区间i~j可获得的最大值,因为本题的所有区间是可以直接一次性把自己全删掉的,所以所有区间初始化为被一次性删除的值,然后枚举断点,跑区间DP. AC代 ...
- 洛谷[Luogu] 普及村总结
总结 简单的模拟 交叉模拟 排序 排序EX
- 九十七、SAP中ALV事件之十,通过REUSE_ALV_COMMENTARY_WRITE函数来显示ALV的标题
一.SE37查看REUSE_ALV_COMMENTARY_WRITE函数 二.查看一下导入 三.我们点击SLIS_T_LISTHEADER,来看一下类型 四.我们再看一下,这个info是60长度的字符 ...
- JQuery 多属性选择节点
JQuery 1.6.0+以后用prop()代替attr(); 多属性选择节点 $("input[type=checkbox][name='first2'][value='first4']& ...
- 三、ReactJS、jsx、 Component 特性
reactjs特性: 基于组件(Component)化思考 用 JSX 进行声明式(Declarative)UI 设计 使用 Virtual DOM Component PropType 错误校对机制 ...
- css 径向渐变
.example { width: 150px; height: 80px; background: -webkit-radial-gradient(red, green, blue); /* Saf ...
- UVA - 11806 Cheerleaders (容斥原理)
题意:在N*M个方格中放K个点,要求第一行,第一列,最后一行,最后一列必须放,问有多少种方法. 分析: 1.集合A,B,C,D分别代表第一行,第一列,最后一行,最后一列放. 则这四行必须放=随便放C[ ...