k-近邻算法采用for循环调参方法
//2019.08.02下午
#机器学习算法中的超参数与模型参数
1、超参数:是指机器学习算法运行之前需要指定的参数,是指对于不同机器学习算法属性的决定参数。通常来说,人们所说的调参就是指调节超参数。
2、模型参数:是指算法在使用过程中需要学习得到的参数,即输入与输出之间映射函数中的参数,它需要通过对于训练数据集训练之后才可以得到。
3、对于KNN算法,它是没有模型参数的,它的k参数就属于典型的超参数。
4、好的超参数的选择主要取决于三个方面:
(1)领域知识
(2)经验数值
(3)实验搜索
5、K近邻算法常用的三大超参数:k、weights=("uniform","distance")以及在weights=distance的情况下p参数。



6、K近邻算法超参数调节寻找最优的方法:网络搜索方式举例如下:
#对于KNN算法寻找最佳的超参数k的值以及另外一个超参数weights=uniform/distances,以及在distance的情况下选择出最佳的超参数p的值的大小:
import numpy as np
import matplotlib.pyplot as plt #导入相应的数据可视化模块
#根据训练得到模型的准确率来进行寻找最佳超参数k肯weights
best_method=""
best_score=0.0
best_k=0
s=[] #初始定义所需要寻找的超参数
from sklearn.neighbors import KNeighborsClassifier
for method in ["uniform","distance"]:
for k in range(1,11): #采用for循环来进行寻找最优的超参数
KNN=KNeighborsClassifier(n_neighbors=k,weights=method)
KNN.fit(x_train,y_train) #进行原始数据的训练
score=KNN.score(x_test,y_test) #直接输出相应的准确度
s.append(score)
if score>best_score:
best_score=score
best_k=k
best_method=method
#数据验证
print("best_method=",best_method)
print("best_k=",best_k)
print("best_score=",best_score)
plt.figure(2)
x=[i for i in range(1,21)]
plt.plot(x,s,"r")
plt.show()
#根据训练得到模型的准确率来进行寻找最佳超参数k以及在weights=distance的情况下寻找最优的参数p
best_p=0
best_score=0.0
best_k=0
s=[] #初始化超参数
from sklearn.neighbors import KNeighborsClassifier
for k in range(1,11):
for p in range(1,6):
KNN=KNeighborsClassifier(n_neighbors=k,weights="distance",p=p)
KNN.fit(x_train,y_train) #进行原始数据的训练
score=KNN.score(x_test,y_test) #直接输出相应的准确度
s.append(score)
if score>best_score:
best_score=score #利用网络搜索方式来寻找最高准确率下的最佳超参数
best_k=k
best_p=p
#数据验证
print("best_p=",best_p)
print("best_k=",best_k)
print("best_score=",best_score)
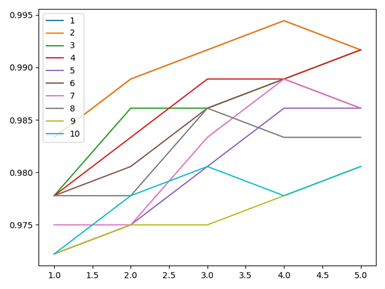
plt.figure(2)
s1=[]
x=[i for i in range(1,6)]
for i in range(1,11):
s1=s[(i*5-5):(5*i)]
plt.plot(x,s1,label=i)
plt.legend(loc=2)
plt.show()
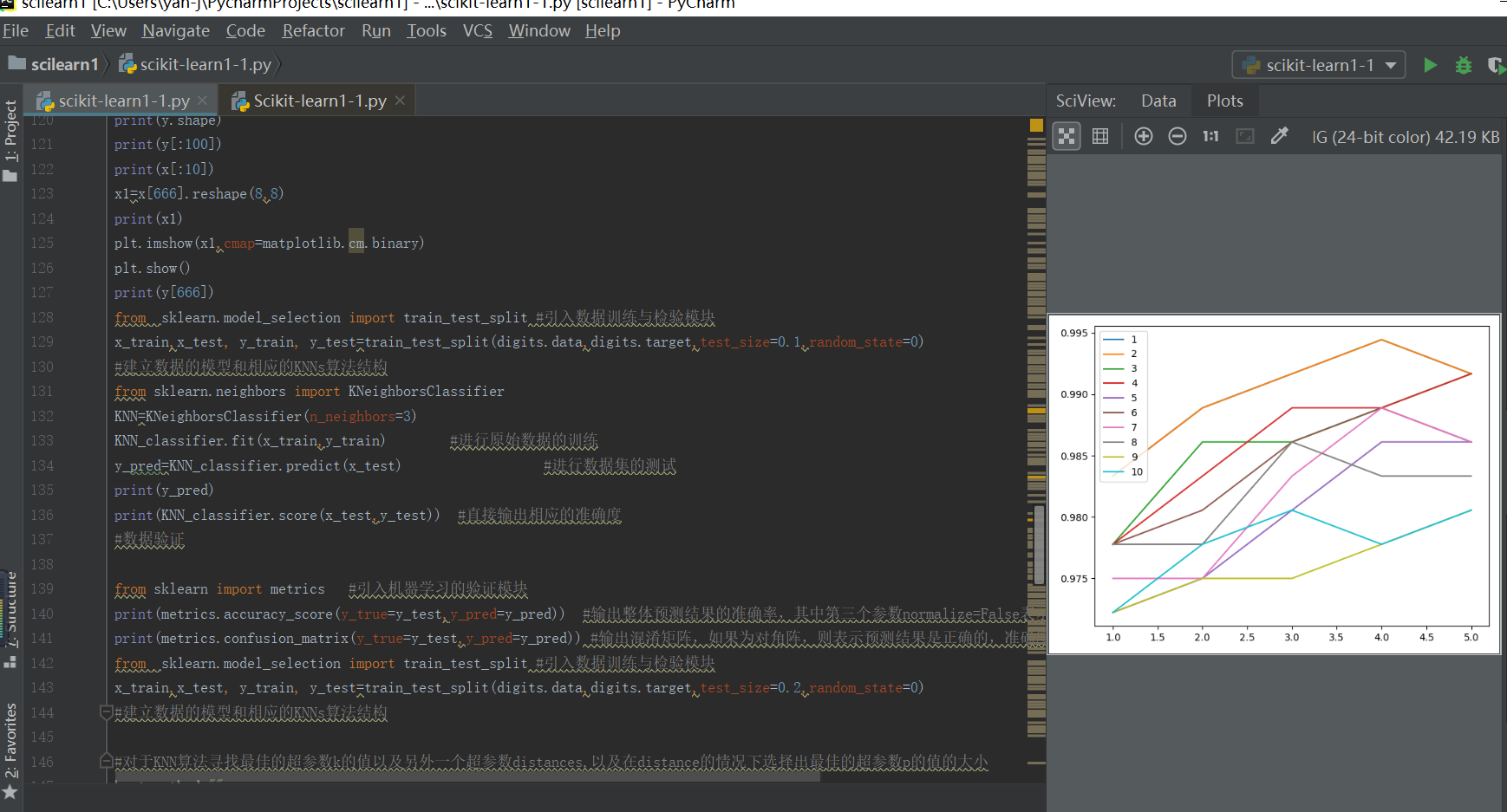
输出结果如下所示:(不同的k和p参数情况下的准确度输出结果)
k-近邻算法采用for循环调参方法的更多相关文章
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 2.在约会网站上使用k近邻算法
在约会网站上使用k近邻算法 思路步骤: 1. 收集数据:提供文本文件.2. 准备数据:使用Python解析文本文件.3. 分析数据:使用Matplotlib画二维扩散图.4. 训练算法:此步骤不适用于 ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
随机推荐
- pandas读取文件的read_csv()方法
import pandas as pd pd.read_csv(filepath_or_buffer,header,parse_dates,index_col) 返回数据类型:DataFrame:二维 ...
- iOS 10.3 以上系统实现应用内评分及开发者回复评论
在 iOS 10.3 之前,如果你要给一个应用评分,那么你需要打开 App Store,搜索应用,找到评论,点击撰写评论,然后评分.整个评分流程非常繁琐,还要忍受漫长的页面加载,导致很少有用户愿意主动 ...
- i.MX RT600之DSP调试环境搭建篇
恩智浦的i.MX RT600是跨界处理器产品,同样也是i.MX RTxxx系列的开山之作.不同于i.MX RT1xxx系列单片机,i.MX RT600 采用了双核架构,将新一代Cortex-M33内核 ...
- 到头来还是逃不开Java - Java13面向对象基础
面向对象基础 没有特殊说明,我的所有学习笔记都是从廖老师那里摘抄过来的,侵删 引言 兜兜转转到了大四,学过了C,C++,C#,Java,Python,学一门丢一门,到了最后还是要把Java捡起来.所以 ...
- ElementUI 中 el-table 获取当前选中行的index
第一种方法:将index放到row数据中 首先,给table加一个属性::row-class-name="tableRowClassName" 然后定义tableRowClassN ...
- ubuntu 18.04 上安装 docker
命令安装 docker 1.直接从 ubuntu 仓库安装,打开终端,输入: 2.启动 docker 服务 . 设置开机自启动 docker 服务 3.免 sudo 配置:
- 寒假作业---蓝桥杯---DFS
题目描述 现在小学的数学题目也不是那么好玩的. 看看这个寒假作业: 每个方块代表1~13中的某一个数字,但不能重复. 比如: 6 + 7 = 13 9 - 8 = 1 3 * 4 = 12 10 ...
- 1013 Battle Over Cities (25分) DFS | 并查集
1013 Battle Over Cities (25分) It is vitally important to have all the cities connected by highways ...
- Atom 必装插件
Atom 必装插件 转载请注明出处. https://blog.csdn.net/Nick_php/article/details/54020956 主题 atom-material-ui 字体配色 ...
- 记录下 k8s (1.14.2)使用kubeadm方式搭建和rancher搭建需要的镜像清单
kubeadm方式 之前一直用的1.12.2版本的,最近想试一下新的版本1.14.2 当然相应的组件镜像版本也需要更新了.镜像版本如下(网络插件使用flannel) k8s.gcr.io/kube-p ...