python生成数据后,快速导入数据库
1、使用python生成数据库文件内容
# coding=utf-8
import random
import time
def create_user():
start = time.time()
count = 1000 # 一千万条数据
beginId = 200010000
with open(r"./userInfo.txt", "w") as fp:
for i in range(1,count+1):
id = str(i)
userId = beginId + i
name = ''.join(random.sample('zyxwvutsrqponmlkjihgfedcba', 4)).replace('', '')
sex = str(random.choice(['男', '女']))
weight = str(random.randrange(10, 99))
address = str(random.choice(['北京', '上海', '深圳', '广州', '杭州']))
insert_t_user_weight = (
"INSERT INTO t_user_weight VALUES ('%s', '%s', '%s','%s', '%s', '%s', '%s');"
% (id, userId, name, sex, weight, address, time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
)
insert_t_user_weight = insert_t_user_weight + '\n'
# print(insert_t_user_weight)
fp.write(insert_t_user_weight)
print('共创建%d条sql耗时:'% count, time.time() - start)
if __name__ == "__main__":
create_user()
2、使用命令导入数据库
load data infile "/tmp/userInfo.txt" into table test_insert fields terminated by ',';
3、MYSQL导入数据出现The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
这个原因是因为在安装MySQL的时候限制了导入与导出的目录权限,只能在规定的目录下才能导入,我们需要通过下面命令查看 secure-file-priv 当前的值是什么。
show variables like '%secure%';
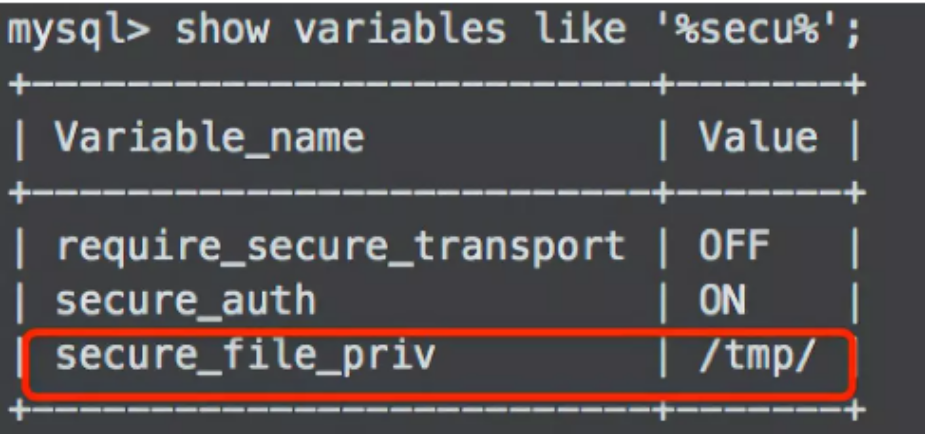
只需要把相对应的文件放在上面的目录下,即可成功读取,而不会报上面的错误了。
python生成数据后,快速导入数据库的更多相关文章
- 图解JanusGraph系列 - 关于JanusGraph图数据批量快速导入的方案和想法(bulk load data)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- mysql分批导出数据和分批导入数据库
mysql分批导出数据和分批导入数据库 由于某些原因,比如说测试环境有很多库,需要迁移到新的环境中,不需要导出系统库的数据.而数据库又有好多,如何才能将每个库导出到独立的文件中呢?导入到一个文件的话, ...
- [DJANGO] excel十几万行数据快速导入数据库研究
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- excel十几万行数据快速导入数据库研究(转,下面那个方法看看还是可以的)
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- python时间序列数据的对齐和数据库的分批查询
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 0. 前言 在机器学习里,我们对时间序列数据做预处理的时候,经常会碰到一个问题:有多个时间序列存在多个表里,每个表的的时间轴不完全相同,要如 ...
- DataTable 快速导入数据库——百万条数据只需几秒
public void InsertTable(DataTable dt, string TabelName, DataColumnCollection dtColum) { string str = ...
- 通过Python将Excel表格信息导入数据库
前言 公司原采用Excel表格方式记录着服务器资产信息,随着业务的增加,相应的硬件资产也增加,同时物理机虚拟化出多台虚拟机,存在表格管理杂乱.变更资产信息不能及时相互同步, 为了紧跟时代的步伐,老大搞 ...
- 包含LOB_Data列的表删除大量数据后表及数据库文件的收缩
最近有一张表(内含varchar(max)字段),占用空间达到240G,删除历史数据后几十万条后,空间并未得到释放. 然后用DBCC CLEANTABLE(0,tb_name,100)来释放删除记录后 ...
- Python生成gexf文件并导入gephi做网络图分析
Gephi是一款优秀的复杂网络分析软件,支持导入多种格式的文件.gexf格式是Gephi 推荐的格式,基于 XML.本文是一个用python写的简单Demo,示例如何生成一个典型的gexf格式文件.代 ...
随机推荐
- OrCAD Capture CIS 16.6 为原理图中的Off-Page Connector添加页面编号
操作系统:Windows 10 x64 工具1:OrCAD Capture CIS 16.6-S062 (v16-6-112FF) 为原理图中的Off-Page Connector添加页面编号 一般来 ...
- Emacs Org-mode 4 超连接
4.1 连接格式 连接的格式非常的简单,示例如下: [[文档内部锚点.外部连接][对连接的描述,可选]] 4.2 内部连接 想要引用或者连接到文档自身内的某个位置,需要引入另外一个概念:anchor( ...
- Coverity代码扫描工具
1.说明:Coverity代码扫描工具可以扫描java,C/C++等语言,可以和jenkins联动,不过就是要收钱,jenkins上的插件可以用,免费的,适用于小的java项目 2.这是Coverit ...
- python的单、双、多分支流程控制
if流程控制总结: 1.当满足条件时,执行满足条件的代码. 2.当执行完if语句内代码,程序继续往下执行. 单分支: if 条件成立,执行满足条件的代码 如下: if a>50: print(' ...
- 527D.Clique Problem
题解: 水题 两种做法: 1.我的 我们假设$xi>xj$ 那么拆开绝对值 $$xi-w[i]>x[j]+w[j]$$ 由于$w[i]>0$,所以$x[i]+w[i]>x[j] ...
- C3_note
- Servlet(四):request和response对象
Request对象:问题: 浏览器发起请求到服务器,会遵循HTTP协议将请求数据发送给服务器. 那么服务器接受到请求的数据改怎么存储呢?不但要存,而且要保证完成性. 解决: 使用对象进行存储,服务器每 ...
- STL复习之 map & vector --- disney HDU 2142
题目链接: https://vjudge.net/problem/40913/origin 大致题意: 这是一道纯模拟题,不多说了. 思路: map模拟,vector辅助 其中用了map的函数: er ...
- Django实例
更新:今年8月在深圳和嵩天老师居然见面了,很开心.嵩天老师很和蔼. =========== 今天看了嵩天老师的视频,感觉讲的很好,于是看着视频自己做了一个初步的实例认识. 步骤1,新建一个Web框架 ...
- DWM1000 收发RXLED TXLED控制代码修改
DWM1000 模块一共可以最多外接4个LED,但是API默认只会只用到两个LED,分别是RXLED.TX LED. 特别注意:RXLED 是模块在RX 状态,而不是接收到数据. 修改代码,使得4个L ...