kaggle之泰坦尼克号乘客死亡预测
前言
一般接触kaggle的入门题,已知部分乘客的年龄性别船舱等信息,预测其存活情况,二分类问题。
python,所需库 机器学习scikit-learn,数据分析pandas,科学计算numpy,画图工具matplotlib,详细的指导说明
本篇大多是整理了下寒小阳的博文,按照他的思路先熟悉一下。
相关性分析
数据

数据如表所示,Pclass 等级,Sibsp 同辈亲戚人数,Parch长辈或者晚辈亲戚人数,Ticket 票号,Fare票价,Cabin 船舱号,Embarked 登陆港口。
数据特点
1.data_train.describe()查看数据分布信息。
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
2.data_train.info()查看数据类型,数据量,其中反应了缺失数据以及需要数值化的变量。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
3.plot查看数据分布情况
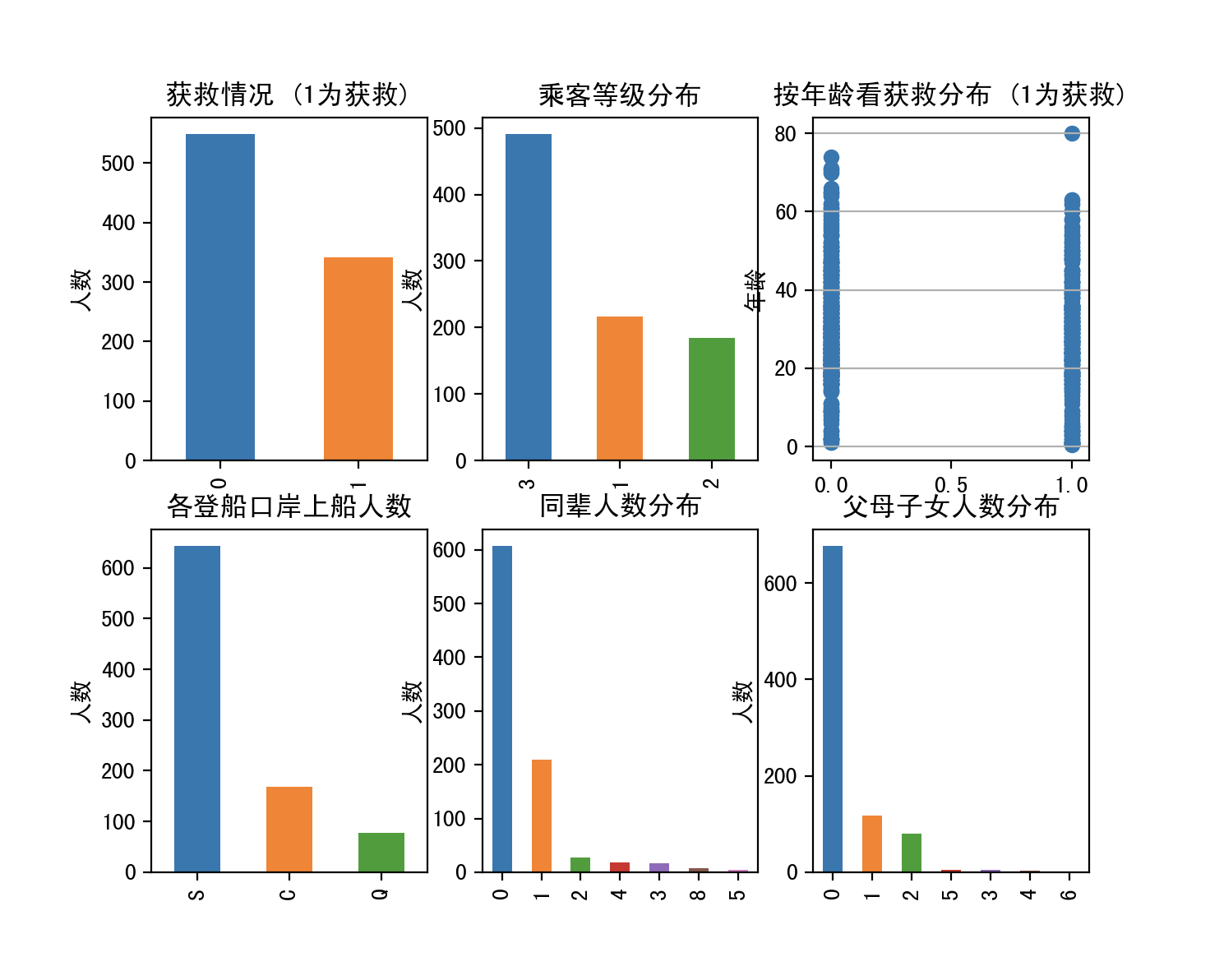
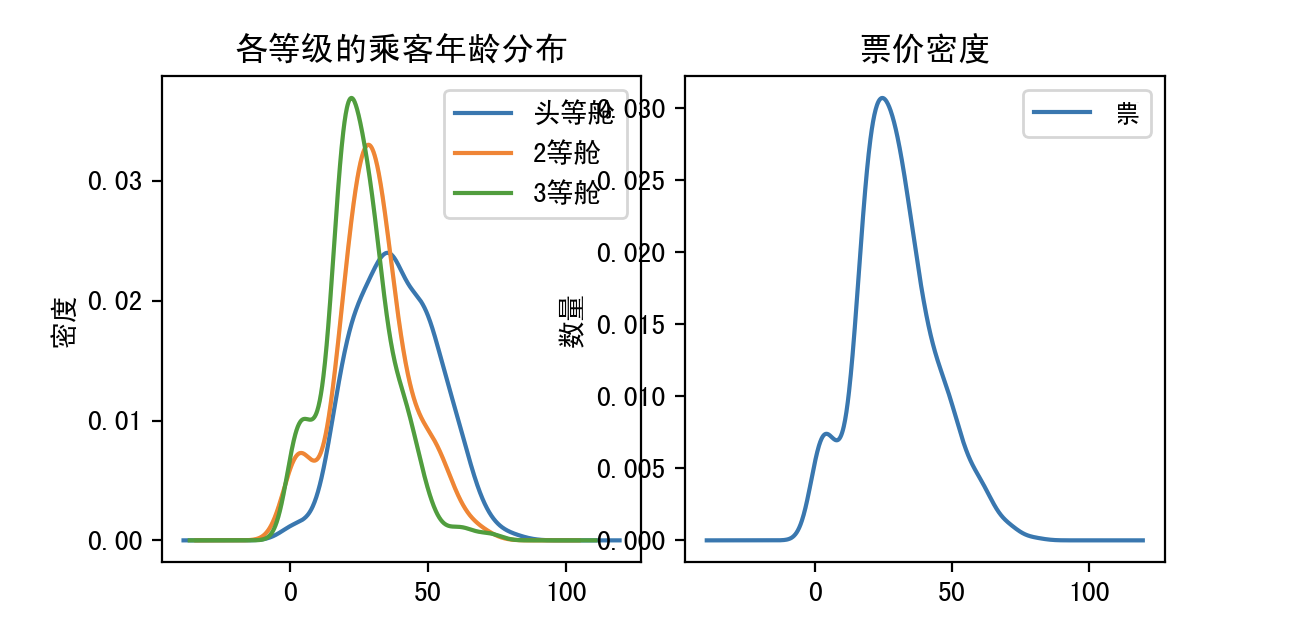
4.分析
- 透过图表,我们看到绝大多数人是没有存活
- 3rd船票最多,1st和2nd相差不大,不同船舱的人有着不同的social-economy state,船舱的就生设备可能也不一样,1st存活可能性应该更高。
- 中年人居多,小孩女人和老人获救可能性更大,年龄性别是个重要的参考因素
- 来自S登船口岸的居多,不同地方的人经济地位也可能不一样
- 独自一人来占大多数,按常识有陪伴的获救可能性大些
- 曲线都基本符合高斯分布
相关性分析
探寻不同属性与是否存活的相关性,为后面的特征工程中特征选取做准备,不过本题中的特征基本上都能利用上。
1.Sex & Survived
女性获救人数要高过男性

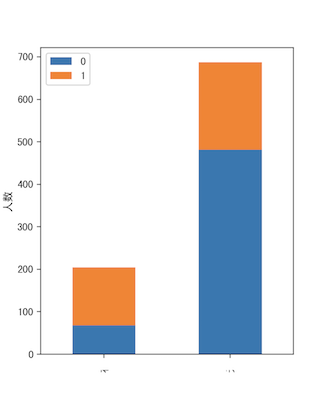
2.Pclass & Survived
相对来说1号船舱获救人数多
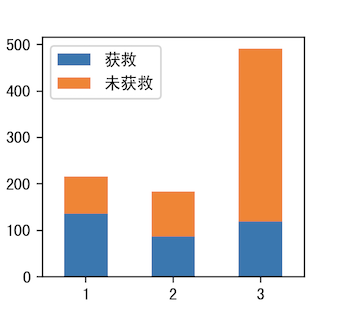
3.SibSp & Survived
有陪伴的存活率相对较高
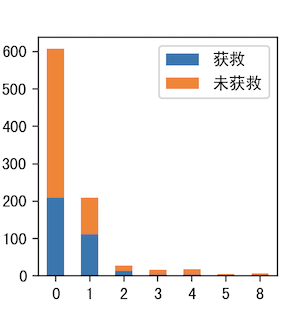
4.Parch & Survived
有陪伴的存活率相对较高
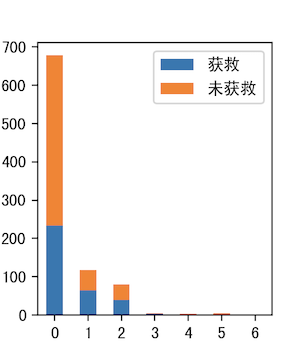
5.Age & Survived (18岁分界)
小孩获救概率要高
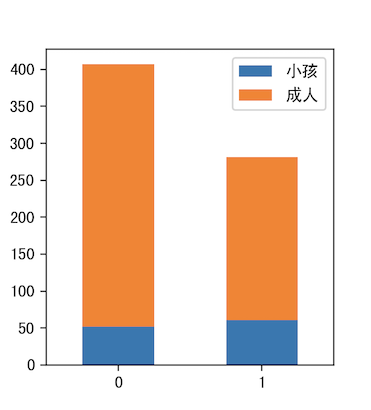
6.Cabin & Survived
因为Cabin存在很多缺失数据,在这里考虑将是否记录作为一组数据,含有Cabin为1,不含为0
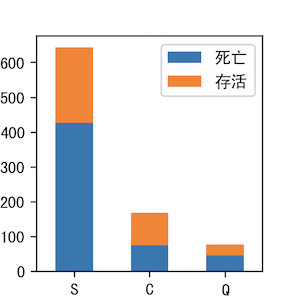
7.Embarked & Survived
S死亡率较高,其次Q,C
数据预处理
数据预处理,包含了很多特征工程(feature engineering)的内容,常见的包含
- 数据清洗
- 缩放特征值
- 处理离群点
- 分箱(离散化)
- 遗漏值填补
- 平滑
- 正则化
- 降维(解决维数灾难问题)
- PCA主成分分析(以下都没了解过)
- 核化线性降维
- 主成分回归
- 特征选择(选取与学习任务相关的特征,例如剔除冗余特征)
- 过滤式选择
- 包裹式选择
- 嵌入式选择
在原始数据中,Age,Cabin部分数据丢失,Cabin采用的方法是将不存在的数据设为一类,存在设为一类,Age缺失的数据比较少,可以利用其他数据拟合的方法得到。如果数据丢失很多,可以丢弃,拟合缺失数据往往会带来很多噪音。
在这里针对年龄数据进行拟合。scikitlearn中回归的方法很多,包含基本回归方法(线性、决策树、SVM、KNN)和集成方法(随机森林,Adaboost和GBRT)等这里使用决策树试一哈
对Cabin分类有无两类,对类目性特征因子化(比如Pclass为1时,Pclass_1 = 1,Pclass_2 = Pclass_3 = 0),将类目属性变成01属性。
接下来对部分属性数据进行缩放scaling到[-1,1]范围内,因为Fare和Age比较大, 在使用Logistic回归时候可能不收敛。
from sklearn import tree
import pandas as pd
import sklearn.preprocessing as preprocessing
def set_missing_ages(df):
age_df = df[['Age','Fare','Parch','SibSp','Pclass']]
#df.info()
unknown_age = age_df[age_df.Age.isnull()]
# unknown_age.info()
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
dtr = tree.DecisionTreeRegressor()
dtr.fit(X, y)
predictedAges = dtr.predict(unknown_age[:,1:])
df.loc[(df.Age.isnull(),'Age')] = predictedAges
return df,dtr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
def Dummies(data_train):
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
return df
def scale(df):
scaler = preprocessing.StandardScaler()
# age_scale_param = scaler.fit(df[['Age']])
df['Age_scaled'] = scaler.fit_transform(df[['Age']])
# fare_scale_param = scaler.fit(df[['Fare']])
df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])
return df
data_test = pd.read_csv('train.csv')
#data_test = data_test[152:153]
#print(data_test)
data_test = set_Cabin_type(data_test)
data_test, dtr = set_missing_ages(data_test)
data_test = Dummies(data_test)
data_test = scale(data_test)
对测试数据同样要进行相同的预处理。
预测模型
Logistic回归训练模型
from sklearn import linear_model
import pandas as pd
#df = pd.read_csv("train.csv")
df = data_train.filter(regex = 'Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
df_np = df.as_matrix()
X = df_np[:,1:]
Y = df_np[:,0]
lr = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
lr.fit(X, Y)
测试模型
from sklearn import linear_model
import pandas as pd
df_test = pd.read_csv('test.csv')
data_test = data_test.filter(regex = 'Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
data_test.info()
predictions = lr.predict(data_test)
result = pd.DataFrame({'PassengerId':df_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)
提交后识别率0.77511
模型优化
查看Logistics回归中参数
columns coef
0 SibSp [-0.3381454779319025]
1 Parch [-0.1064602610081524]
2 Cabin_No [-0.43037949159765415]
3 Cabin_Yes [0.4995693787782281]
4 Embarked_C [0.0]
5 Embarked_Q [0.0]
6 Embarked_S [-0.4044885229471587]
7 Sex_female [2.371995280082146]
8 Sex_male [-0.27587171480659783]
9 Pclass_1 [0.34926690132602034]
10 Pclass_2 [0.0]
11 Pclass_3 [-1.1852811813447819]
12 Age_scaled [-0.5456032666714946]
13 Fare_scaled [0.08190439585453066]
kaggle之泰坦尼克号乘客死亡预测的更多相关文章
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- TensorFlow从1到2(十四)评估器的使用和泰坦尼克号乘客分析
三种开发模式 使用TensorFlow 2.0完成机器学习一般有三种方式: 使用底层逻辑 这种方式使用Python函数自定义学习模型,把数学公式转化为可执行的程序逻辑.接着在训练循环中,通过tf.Gr ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- Kaggle 入门题-泰坦尼克号灾难存活预测
这个题目的背景概况来讲就是基于泰坦尼克号这个事件,然后大量的人员不幸淹没在这个海难中,也有少部分人员在这次事件之中存活,然后这个问题提供了一些人员的信息如姓名.年龄.性别.票价,所在客舱等等一些信息, ...
- 【项目实战】Kaggle泰坦尼克号的幸存者预测
前言 这是学习视频中留下来的一个作业,我决定根据大佬的步骤来一步一步完成整个项目,项目的下载地址如下:https://www.kaggle.com/c/titanic/data 大佬的传送门:http ...
- 机器学习之路: python 决策树分类DecisionTreeClassifier 预测泰坦尼克号乘客是否幸存
使用python3 学习了决策树分类器的api 涉及到 特征的提取,数据类型保留,分类类型抽取出来新的类型 需要网上下载数据集,我把他们下载到了本地, 可以到我的git下载代码和数据集: https: ...
- chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序.Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型, ...
- Kaggle之泰坦尼克号幸存预测估计
上次已经讲了怎么下载数据,这次就不说废话了,直接开始.首先导入相应的模块,然后检视一下数据情况.对数据有一个大致的了解之后,开始进行下一步操作. 一.分析数据 1.Survived 的情况 train ...
- Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 NbViewer 比赛页面:https://www.kaggle.com/c/titanic Titanic大概是kaggle上最受欢迎的项目了,有7000多 ...
随机推荐
- Web安全基础——小白自学
2019-02-23 19:41:49 话不多说,直接分享我学习到的东西~ Web万维网(World Wide Web,WWW),这个名称我们熟悉不过啦.跟它密切相关就是HTTP,叫做超文本传输协 ...
- thinkphp在iis上不是出现500错误
按照官方文档,部署好iis下面URL重定向文件后,出现500错误,不停地百度,不停地修改web.config文件,终也不成. 在虚拟空间调整了php版本,一下子就好了.原来的版本为5.4,调整为5.6 ...
- jira7.3.6的安装步骤
准备环境:jira7.3需要jdk1.8 1.下载jira需要的版本 https://www.atlassian.com/software/jira/download 2.上传atlassian-ji ...
- HttpClient基本使用
1.在pom.xml加入对httpclient的必需的jar包的依赖 <!--//httpclient的接口基本都在这儿--> <dependency> <groupId ...
- (五)ORBSLAM关键帧的筛选和插入
ORBSLAM2的关键帧简介 图像插入频率过高会导致信息冗余度快速增加,而这些冗余的信息对系统的精度却十分有限,甚至没有提高,反而消耗了更多的计算资源.这等于吃力不讨好. 关键帧的目的在于,适当地降低 ...
- 项目Alpha冲刺(团队)-第一天冲刺
格式描述 课程名称:软件工程1916|W(福州大学) 作业要求:项目Alpha冲刺(团队)-代码规范.冲刺任务与计划 团队名称:为了交项目干杯 作业目标:描述第一天冲刺的项目进展.问题困难.心得体会 ...
- rpmbuild analysis
- spring MVC 项目 WEB-INF下的jsp不能加载css文件
一.项目目录 二.解决方法(已解决) 1. jsp文件加入 <link href="<c:url value="/css/main.css" />&qu ...
- 文件上传的一个坑 Apache上传组件和SpringMVC自带上传冲突
List list = upload.parseRequest(request); 接受不到数据,size=0; 原因就是下面这货造成的 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ bean id=&qu ...
- VMware14虚拟机上使用Ubuntu16.04遇到的各种问题(不定期更新)
1.ubuntu系统界面无法全屏铺满的问题 网上大部分解决方案都是使用vmware tools,我没尝试过,不过这里推荐一个更加简单的方法,只需要输入两行命令 第一步:sudo apt-get ins ...