论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
2019-04-25 21:43:11
Paper:https://arxiv.org/pdf/1904.04357.pdf
Code: https://github.com/fanchenyou/HME-VideoQA
1. Background and Motivation:
用 Memory Network 做视觉问题回答并不是特别新鲜,因为 CVPR-2018 已经有很多工作,都是用这种外部记忆网络来进行知识的读取,从而更好的辅助 VQA。但是本文做的是另外一种 task,video question answer,相对来说,视频的肯定要更难一些。如何很好的根据问题,到视频中去定位相关的视频帧,从而更好的完成问题回答,是一个需要关注的问题之一。

现有的方法都尝试对视频或者问题进行 attend 处理,以得到更好的结果:
1. Jang et al. 对视频特征的空间和时间维度都进行加权处理(spato-temporal attention mechansim on both spatial and temporal dimension of video features);他们也提出用 VGG 和 C3D 来提取 appearance 和 motion feature 来更好的表达视频帧;但是他们采用前期融合的方法,然后输入到 video encoder 中,这种方式得到的效果,并不是最优的;
2. Gao et al. 提出用更先进的 co-attention mechanism 来替换掉 Jang 的前期融合的方法;但是这种方法并没有同速进行 appearance 和 motion feature 检测到的 attention;与此同时,这种方法也丢失了可以从表观和运动特征中得到的 attention;
作者认为:现有方法未能正确的识别 attention,是因为他们分开进行了特征的融合 (feature integration) 和注意力学习 (attention learning) 的步骤;为了解决这一问题,作者提出一种新的多种记忆(heterogeneous memory)来同时完成融合 appearance and motion features 以及 learning spatio-temporal attention。
另外,如果 question 有非常复杂的语义信息,那么 VideoQA 就会变得异常复杂,从而需要多个步骤的推理。现有的方法都是简单的用 Memory Network 来处理这种情况,但是作者认为他们的方法太多简单,用 LSTM 或者 GRU 得到的 single feature vector 缺乏捕获问题中复杂语义的能力,如图 1 所示。所以,就需要设计一种新的模型来理解问题中复杂的语义信息。为了解决这一问题,作者提出一种新的网络结构,尝试将 question encoder 和 question memory 来互相增强。question encoder 学习问题的有意义表达,然后重新设计 question memory 来理解复杂的语义,然后通过存储和更新全局内容来强调检索的物体。
此外,作者也设计了一种多模态融合层,通过对齐相关视觉内容和关键问题单词,来同时对 visual 和 question hints 进行加权处理。在逐渐优化联合 attention 之后,再将其进行加权融合,然后进行 multi-step reasoning,以从复杂的语义中进行正确答案的推理。
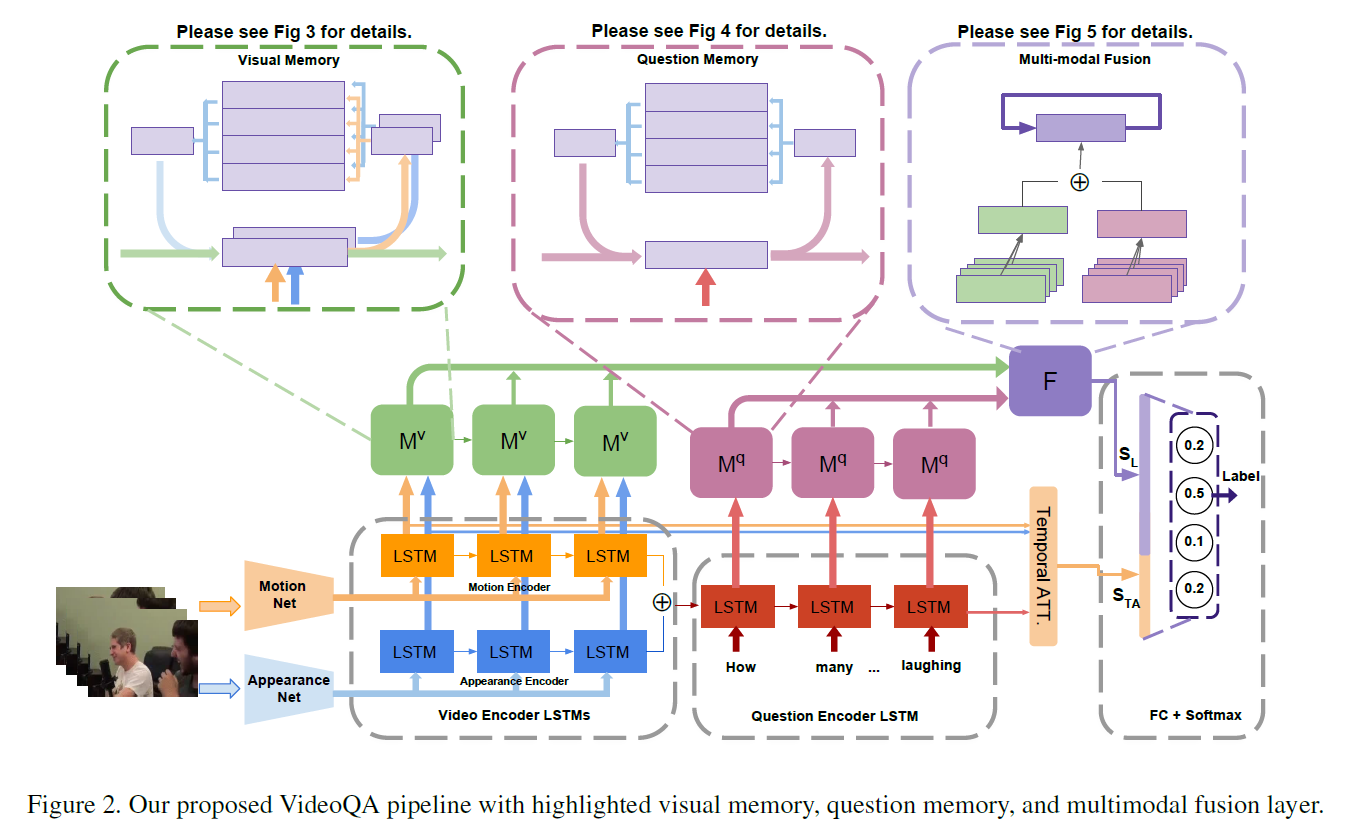
2. The Proposed Method:
2.1 Video and Text Representation:
对于 video,作者用 Resnet, VGG 和 C3D 模型来提取 appearance and motion feature, $f^a, f^m$. 然后用两支 LSTM 模型分别对 motion and appearance features 进行处理,最终放到 memory network 中进行特征融合;
对于 question,先用 Glove 300-D 得到 embedding,然后用 LSTM 对这些向量进行处理。
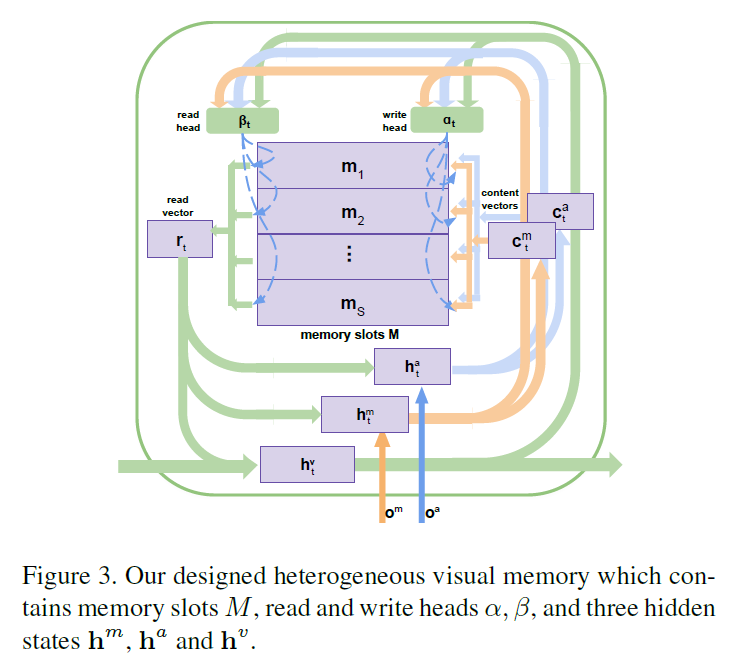
2.2 Heterogeneous Video Memory:
与常规的 external memory network 不同,作者新设计的网络处理多个输入,包括编码的 motion feature,appearance feature;用多个 write heads 来决定内容的写入,如图 3 所示。其中的 memory slots M = [m1, m2, ... , ms] 以及 三个 hidden states $h^m, h^a$ and $h^v$。前两个 hidden state $h^m$ 和 $h^a$ 用来表示 motion 和 appearance contents,将会写入到记忆中,$h^v$ 用于存贮和输出 global context-aware feature,该特征是融合了 motion 和 appearance information 的。




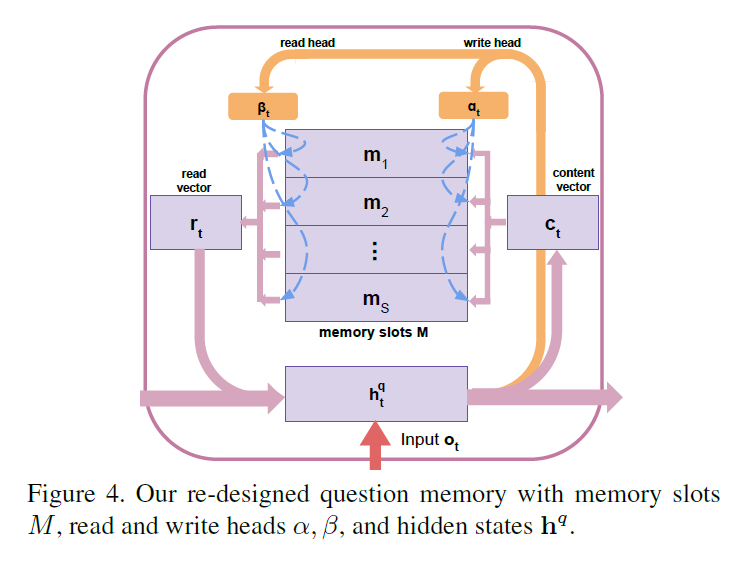
2.3 External Question Memory:
该问题记忆的目标是存贮 sequential text information,学习不同单词之间的相关性,并且尝试从全局的角度来理解问题。


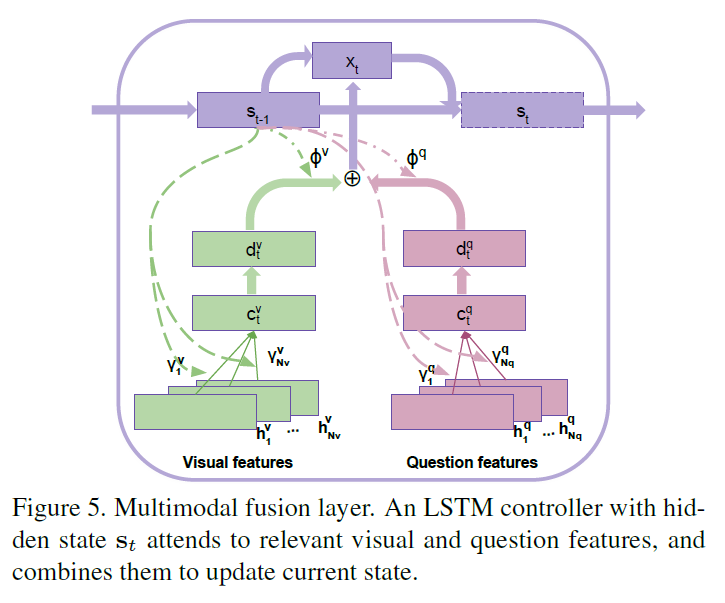
2.4 Multi-modal Fusion and Reasoning :
==
论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering的更多相关文章
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制
在上一篇博客中介绍的论文"Show and tell"所提出的NIC模型采用的是最"简单"的encoder-decoder框架,模型上没有什么新花样,使用CNN ...
- 论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grain ...
- 【论文笔记】CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 2018-09-14 21:52:42 Paper:http://openaccess.thecvf.com/co ...
- SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract 提出了一种无监督单目深度估计和相机运动估计的框架 利用视觉合成作为监督信息,使用端到端的方式学习 网络分为两部分(严格意义上是三个) 单目深度估计 多视图姿态估计 解释性网络( ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
- (zhuan) 自然语言处理中的Attention Model:是什么及为什么
自然语言处理中的Attention Model:是什么及为什么 2017-07-13 张俊林 待字闺中 要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model( ...
- [转]自然语言处理中的Attention Model:是什么及为什么
自然语言处理中的Attention Model:是什么及为什么 https://blog.csdn.net/malefactor/article/details/50550211 /* 版权声明:可以 ...
- 自然语言处理中的Attention Model:是什么及为什么
/* 版权声明:能够随意转载.转载时请标明文章原始出处和作者信息 .*/ author: 张俊林 要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model(后文有 ...
随机推荐
- 微信小程序字符串替换
字符串替换有两种,一种是替换一个子字符串,一种是将子字符串全部替换 替换一个子字符串 要求:将“ ”(空格)替换成“,” var isguestnumbername=“aaa bbb ccc” isg ...
- spring 相关注解详情(二)
@Configuration用于定义配置类,可替换xml配置文件,被注解的类内部包含有一个或多个被@Bean注解的方法 /* 数据源的属性类 */ public class DataSourcePro ...
- Spring Boo数据访问JDBC
一.SpringBoot 访问JDBC原理 我们可以参考源代码:SpringBoot2中默认的数据源是使用HikariDataSource /** * Hikari DataSource config ...
- 多线程深入:乐观锁与悲观锁以及乐观锁的一种实现方式-CAS(转)
原文:https://www.cnblogs.com/qjjazry/p/6581568.html 首先介绍一些乐观锁与悲观锁: 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每 ...
- opencart分类筛选逻辑修改为并且条件
opencart分类筛选模式默认是或的逻辑,满足条件1或条件2都展现出来,如果想要改成既满足条件1又满足条件2要怎么改呢?有一个插件可以实现,FixFilter OC2x,可以修改默认的筛选条件 1. ...
- 2019-oo-第一次总结
一.度量分析程序结构 1.UML类图分析 1.1第一次作业 1.2第二次作业 1.3第三次作业 1.4总结 从UML类图三次作业的可以看出,我从一个类到逐渐利用多个类,代码结构在不 ...
- 拼多多(7pdd)微信跳转h5页面打开app跳转任意url关注技术weixin://dl/business/?ticket
拼多多微信跳转接口利用了微信官方的weixin://dl/business/?ticket技术,此类接口可以在官方接口中找到,分析代码如下: <title>拼多多</title> ...
- JFinal框架
FJinal过滤器(tomcat) 创建java类继承JFinalConfig 会实现六个方法(有一个是拦截器的方法好像是,那个我好像看的跟struts2一样但是又没看懂暂时不写) Controlle ...
- Python:re中的group方法简介
原文地址:http://www.cnblogs.com/kaituorensheng/archive/2012/08/20/2648209.html. 正则表达式中,group()用来提出分组截获的字 ...
- py001
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple -------------------------------- ...