文本分类学习 (九)SVM入门之拉格朗日和KKT条件
上一篇说到SVM需要求出一个最小的||w|| 以得到最大的几何间隔。
求一个最小的||w|| 我们通常使用

来代替||w||,我们去求解 ||w||2 的最小值。然后在这里我们还忽略了一个条件,那就是约束条件,在上一篇的公式(8)中的不等式就是n维空间中数据点的约束条件。只有在满足这个条件下,求解||w||2的最小值才是有意义的。思考一下,若没有约束条件,那么||w||2的最小值就是0,反应在图中就是H1和H2的距离无限大那么所有点都会在二者之间,都属于同一类,而无法分开了。
求最小值的目标函数和约束条件s.t.
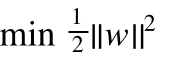
 (1)
(1)
xi和yi分别表示样本向量和样本所属的标签,w 是自变量,本身是一个向量。
求最小值也就是求最优值,它有一个很好听的名字叫做规划,而我们的目标函数是1/2 * ||w||2是一个二次函数,二次函数属于凸函数,所以改求解也就有个更好听的名字叫做凸二次规划
对于这种带有约束条件的规划问题,我们可以通过一定的方式把约束条件去掉!
凸函数和凸集
这里提一下凸函数,提到凸函数就要提交凸集或者凸包,凸集内的如意两个点的连线,都在凸集之内。满足这样的集合就叫凸集,比如正方形,六边形都是凸集。
那么凸函数:对区间[a,b]上定义的函数f,若它对区间中任意两点x1,x2均有:
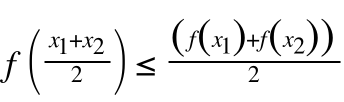 (2)
(2)则称f为区间[a,b]上的凸函数。
引入拉格朗日乘数,来消除约束条件
拉格朗日乘子法:
对于 带约束的优化问题:
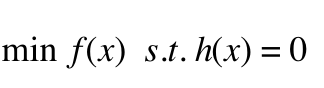 (3)
(3)
则可以通过拉格朗日乘子构造拉格朗日函数
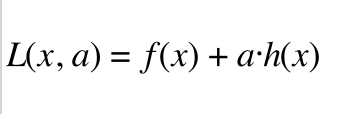 (4)
(4)
其中a是一个拉格朗日乘子构成的向量(a1,a2,a3,a4,....)ai>0
然后在对x 和 拉格朗日乘子a 求导,连立方程求出x 和 a ,再把x代入目标函数中求得极值.
回到我们的问题,通过拉格朗日乘子法构建拉格朗日函数, 在此之前我们把约束条件左边加上负号,让其条件变成小于0
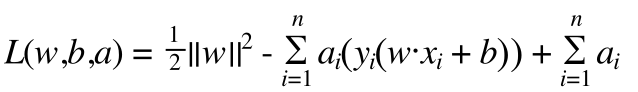 (5)
(5)
我们设
 (6)
(6)
如果xi满足约束条件,yi(w * xi + b) >= 1,则 θp(x)要取最大值,只能让 α= 0 就是取0向量,则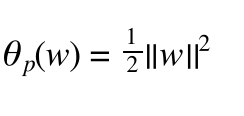 (7)
(7)
如果xi不满足条件 yi(w * xi + b) <= 1 要取最大值,那么α 可以无限大,所有
 (8)
(8)
所以我们看以看出 θp(x) 已经实现了把约束条件变成无约束条件
所以(1)中的带有约束条件的目标函数,就可以变成求(6)式(不带约束)的最小值,原因就是上面(7)和(8)公式 :
 (9)
(9)
我们直接求解此比较困难,需要这个式子转换成它的对偶问题(min 和 max 调换位置),再去求解这个对偶问题:
 (10)
(10)
为什么可以通过转换成对偶问题来求解原问题呢?因为存在这样一条定理设原问题的解为p* 它的对偶问题解为d*,一般情况下有d*<=p*, 证明过程就不写了。
所以求解对偶问题只能得到原问题解的下界,而不能保证d* = p*。
对这个对偶问题进行求解,先求minw,bL(w,b,a) 把a 当做常数 对w 和 b分别求导可以得到:
 (11)
(11)
 (12)
(12)
把(11)和(12)式代入 (5)式中可以求得minw,bL(w,b,a)
 (13)
(13)
可以看到(13)式中的w 和 b都消失了,(13)式是minw,bL(w,b,a)的值,求完最小值,还要求maxai>0
 (14)
(14)
如果把(14)问题中的 a 求出来,那么w 也就能求出来(通过(11)),b 也就可以求出了。
先不管怎么把a 求出来,因为这里有很多算法可以去求解,用的最多的就是SMO算法。
我们接下来证明这个通过对偶问题求出来的解 d* 就是我们想要的原问题解 p* ,这里就要介绍到KKT条件
根据(11)和 (12)式,我们可以得出

再根据原问题中的约束条件,我们可以得出

这5个条件加起来就满足了KKT条件,KKT条件是对偶问题的解d* = p* 的充分必要条件
以下是证明过程:
文本分类学习 (九)SVM入门之拉格朗日和KKT条件的更多相关文章
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 带约束优化问题 拉格朗日 对偶问题 KKT条件
转自:七月算法社区http://ask.julyedu.com/question/276 咨询:带约束优化问题 拉格朗日 对偶问题 KKT条件 关注 | 22 ... 咨询下各位,在机器学习相关内容中 ...
- 文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的.因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来. 所以要理解SVM ...
- 文本分类学习(六) AdaBoost和SVM
直接从特征提取,跳到了BoostSVM,是因为自己一直在写程序,分析垃圾文本,和思考文本分类用于识别垃圾文本的短处.自己学习文本分类就是为了识别垃圾文本. 中间的博客待自己研究透彻后再补上吧. 因为获 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
随机推荐
- Spark操作:Aggregate和AggregateByKey
1. Aggregate Aggregate即聚合操作.直接上代码: import org.apache.spark.{SparkConf, SparkContext} object Aggregat ...
- 登录sqlplus 后,显示问号 ????
登录sqlplus 后,显示 ???? SYS@orcl>startup ORACLE instance started. Total System Global Area 3290345472 ...
- 【PMP】项目采购管理~重点知识
1.合同的类型与区别 固定总价(FFP):大多数买方都喜欢这种合同,因为货物的采购价格在一开始就已确定,并且不允许改变(除非工作范围发生变更) 总价加激励费用(FPIF):这种总价合同给买方和卖方提供 ...
- VTK拾取网格模型上的可见点
消隐与Z-Buffer 使用缓冲器记录物体表面在屏幕上投影所覆盖范围内的全部像素的深度值,依次访问屏幕范围内物体表面所覆盖的每一像素,用深度小(深度用z值表示,z值小表示离视点近)的像素点颜色替代深度 ...
- 阿里云k8s应用最新日志采集不到的问题
问题描述: 阿里云k8s应用日志之前一直都是可以正常的采集, 先出现一问题, 通过kibana 和阿里云的日志服务都没法展示最新的k8s应用的日志, 部分应用的最新日志有被采集到,但大部分应用日志没有 ...
- AirServer for Mac(Airplay 终端实用工具)破解版安装
1.软件简介 AirServer 是一款 Mac 上的 AirPlay 终端,通过这款软件,利用 AirPlay 技术,iPhone 或 iPad 就可以无线连接到 Mac 上,不需要在 iPh ...
- 9.4 翻译系列:EF 6以及 EF Core中的NotMapped特性(EF 6 Code-First系列)
原文链接:http://www.entityframeworktutorial.net/code-first/notmapped-dataannotations-attribute-in-code-f ...
- 【转载整理】mysql权限分配详解
原文:https://www.cnblogs.com/Csir/p/7889953.html MySQL权限级别 1)全局性的管理权限,作用于整个MySQL实例级别 2)数据库级别的权限,作用于某个指 ...
- 第一部分:开发前的准备-第三章 Application 基本原理
第3章 应用程序基本原理 首先我们需要强调一下Android 应用程序是用java写的.Android SDK工具编译代码并把资源文件和数据打包成一个文件.这个名字的扩展名是.APK.要在androi ...
- Linux之sort
sort是在Linux里非常常用的一个命令,管排序的,集中精力,五分钟搞定sort,现在开始! 1 sort的工作原理 sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按AS ...