浅谈k短路算法
An Old but Classic Problem
给定一个$n$个点,$m$条边的带正权有向图。给定$s$和$t$,询问$s$到$t$的所有权和为正路径中,第$k$短的长度。
Notice
定义两条路径不同,当且仅当它们的边集中存在一条边,使得它只在其中的一条路径上。
Solution#1 Shortest Path & A*
对于Dijstra算法,有一个结论就是,当一个点第$k$次出队的时候,此时路径长度就是$s$到它的第$k$短路。
那为什么还要A*呢?我试了试,写了个Dijstra,然后交了一发poj 2449,于是MLE了。。。如果您觉得我的Dijstra太丑了,您可以手写一个交一发。
所以用A*来优化优化状态数(其实就是玄学优化,需要你的人品还有出题人的素质)。
首先建反图,跑一次最短路算法,得到每个点到$t$的最短路的距离。
然后用当前走的距离加上到终点的最短路的长度作为优先级进行A*。
那如何得到答案?
- 当一个点第k次出队时,答案是它的优先级
- 当终点第k次出队时,答案是它已经走的路程
据说A*可以被卡成$O\left(nk\log n \right )$,只是我不会QAQ。
Code
/**
* poj
* Problem#2449
* Accepted
* Time: 250ms
* Memory: 9252k
*/
#include <iostream>
#include <fstream>
#include <sstream>
#include <algorithm>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <ctime>
#include <cctype>
#include <cmath>
#include <vector>
#include <queue>
#include <stack>
#include <map>
#include <set>
#include <bitset>
using namespace std;
typedef bool boolean; typedef class Edge {
public:
int end;
int next;
int w; Edge(int end = , int next = -, int w = ):end(end), next(next), w(w) { }
}Edge; const int N = 1e3, M = 1e5; typedef class MapManager {
public:
int cnt;
int h[N + ];
Edge edge[M + ]; MapManager() { }
MapManager(int n):cnt(-) {
// h = new int[(n + 1)];
// edge = new Edge[(m + 1)];
memset(h, -, sizeof(int) * (n + ));
} inline void addEdge(int u, int v, int w) {
edge[++cnt] = (Edge(v, h[u], w));
// h[u] = (signed)edge.size() - 1;
h[u] = cnt;
} inline int start(int node) { return h[node]; } Edge& operator [] (int pos) {
return edge[pos];
}
}MapManager;
#define m_endpos -1 int n, m;
MapManager g;
MapManager rg;
int s, t, k;
int ds[N + ]; inline void init() {
scanf("%d%d", &n, &m);
memset(g.h, -, sizeof(int) * (n + ));
memset(rg.h, -, sizeof(int) * (n + ));
for(int i = , u, v, w; i <= m; i++) {
scanf("%d%d%d", &u, &v, &w);
g.addEdge(u, v, w);
rg.addEdge(v, u, w);
}
scanf("%d%d%d", &s, &t, &k);
// ds = new int[(n + 1)];
} #define g rg
#define f ds
#define que que1
boolean vis[N + ];
queue<int> que;
boolean spfa(int s, int t) {
memset(f, 0x7f, sizeof(int) * (n + ));
memset(vis, false, sizeof(boolean) * (n + ));
que.push(s);
f[s] = ;
while(!que.empty()) {
int e = que.front();
que.pop();
vis[e] = false;
for(int i = g.start(e); i != m_endpos; i = g[i].next) {
int& eu = g[i].end;
// cout << e << " " << eu << " " << i <<endl;
if(f[e] + g[i].w < f[eu]) {
f[eu] = f[e] + g[i].w;
if(!vis[eu]) {
que.push(eu);
vis[eu] = true;
}
}
}
}
return (f[t] != 0x7f7f7f7f);
}
#undef g
#undef f
#undef que typedef class Status {
public:
int node;
int dis;
int priority; Status(int node = , int dis = ):node(node), dis(dis), priority(h()) { } int h() {
return dis + ds[node];
} boolean operator < (Status b) const {
return priority > b.priority;
}
}Status; int label[N + ];
priority_queue<Status> que;
int bfs(int s, int t) {
if(s == t) k++;
// label = new int[(n + 1)];
memset(label, , sizeof(int) * (n + ));
que.push(Status(s, ));
while(!que.empty()) {
Status e = que.top();
que.pop();
label[e.node]++;
if(e.node == t && label[e.node] == k)
return e.dis;
for(int i = g.start(e.node); i != m_endpos; i = g[i].next) {
if(label[g[i].end] < k)
que.push(Status(g[i].end, e.dis + g[i].w));
}
}
return -;
} inline void solve() {
if(!spfa(t, s)) {
puts("-1");
return;
}
printf("%d", bfs(s, t));
} int main() {
init();
solve();
return ;
}
最短路算法 + A*
Solution#2 Shortest Path & Protractable Heap
考虑建立反图,然后跑最短路算法得到以$t$为根的最短路径生成树。
当走了一条非树边$(u, v, w)$意味着什么?
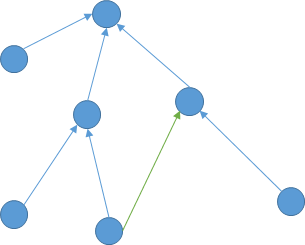
最终的路径长度就会因此增加$f[v] - f[u] + w$。
对于一条路径,我们依次将它经过的非树边记下来,约定得到的序列是这条路径的非树边序列。
考虑对于一个合法的非树边序列,我们可以找到唯一的一条$s$到$t$的路径与之对应。
因此,$k$短路的长度就等于第$k$小的代价和加上$s$到$t$的最短路的长度。
考虑如何来得到一个合法的非树边序列。
- 找到一条起点在当前点$p$到根$t$的路径上的非树边
- 令p等于这条边的终点。
我们可以通过这样的方法来得到所有的非树边序列。但是我们并不需要所有的非树边序列,因此当找到第$x$短路后再进行拓展状态,然后用优先队列来维护。
但是这样每次拓展时间复杂度可达$O(m)$,总时间复杂度可以达到$O\left(mk\log \left (mk \right ) \right )$。
令人无法接受。但是其中真正会被用到的状态十分少。
因此可以像UVa 11997那样进行优化。
当一个非树边序列出队时,代价和比它大的才可能有用。
因此,考虑一个非树边序列出队时通过下面的方法来进行得到新的序列:
- 追加操作:假如最后一条非树边的终点为$v$,找到一条起点在$v$到$t$的路径上代价最小的非树边追加在当前非树边序列后
- 替换操作:将最后一条非树边更换为代价比它大的1条非树边。
例如图中橙色虚线是被替换掉的非树边,紫色是新加入的非树边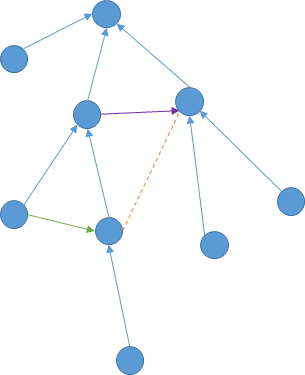
考虑用一些可持久化数据结构(如可持久化斜可并堆,可持久化线段树,可持久化Treap)来维护起点在点$u$到根的路径上的非树边的代价。
对于替换操作,
- 如果用的可持久化堆,那么把最后一条非树边替换为它所在的堆(你从哪个堆把它拿出来的)中它的左右子节点代表的边。
- 如果用的可持久化平衡树,那么把最后一条非树边直接替换为它的后继
- ......
这是一个很稳定的算法,时间复杂度$O\left ( n + m\log m + k\log k \right )$。就是常数有点大,sad.....
注意一些细节
- 计算代价时需要考虑终点是否可以到达$t$
- 考虑$s = t$时,要求的$k$短路包不包含0
- $k$短路不存在,队首为空
(注意!不能用斜堆可持久化,斜堆的时间复杂度是均摊的。这里能过应该只是没有被卡)
Code
/**
* poj
* Problem#2449
* Accepted
* Time: 438ms
* Memory: 15196k
*/
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
#include <vector>
#include <queue>
using namespace std;
typedef bool boolean; #define pii pair<int, int>
#define fi first
#define sc second typedef class Node {
public:
int val, ed;
Node *l, *r; Node() { }
Node(int val, int ed, Node *l, Node *r):val(val), ed(ed), l(l), r(r) { }
}Node; #define Limit 1000000 Node pool[Limit];
Node* top = pool; Node* newnode(int val, int ed) {
if(top >= pool + Limit)
return new Node(val, ed, NULL, NULL);
top->val = val, top->ed = ed, top->l = top->r = NULL;
return top++;
} Node* merge(Node* a, Node* b) {
if (!a) return b;
if (!b) return a;
if (a->val > b->val) swap(a, b);
Node* p = newnode(a->val, a->ed);
p->l = a->l, p->r = a->r;
p->r = merge(p->r, b);
swap(p->l, p->r);
return p;
} typedef class Status {
public:
int dist;
Node* p; Status(int dist = , Node* p = NULL):dist(dist), p(p) { } boolean operator < (Status b) const {
return dist > b.dist;
}
}Status; typedef class Edge {
public:
int end, next, w; Edge(int end = , int next = , int w = ):end(end), next(next), w(w) { }
}Edge; typedef class MapManager {
public:
int ce;
int* h;
Edge* es; MapManager() { }
MapManager(int n, int m):ce() {
h = new int[(n + )];
es = new Edge[(m + )];
memset(h, , sizeof(int) * (n + ));
} void addEdge(int u, int v, int w) {
es[++ce] = Edge(v, h[u], w);
h[u] = ce;
} Edge& operator [] (int pos) {
return es[pos];
}
}MapManager; int n, m;
int s, t, k;
MapManager g;
MapManager rg;
boolean *vis;
int* f, *lase; inline void init() {
scanf("%d%d", &n, &m);
g = MapManager(n, m);
rg = MapManager(n, m);
for (int i = , u, v, w; i <= m; i++) {
scanf("%d%d%d", &u, &v, &w);
g.addEdge(u, v, w);
rg.addEdge(v, u, w);
}
scanf("%d%d%d", &s, &t, &k);
} queue<int> que;
void spfa(MapManager& g, int s) {
vis = new boolean[(n + )];
f = new int[(n + )];
lase = new int[(n + )];
memset(f, 0x7f, sizeof(int) * (n + ));
memset(vis, false, sizeof(boolean) * (n + ));
que.push(s);
f[s] = , lase[s] = ;
while (!que.empty()) {
int e = que.front();
que.pop();
vis[e] = false;
for (int i = g.h[e]; i; i = g[i].next) {
int eu = g[i].end, w = g[i].w;
if (f[e] + w < f[eu]) {
f[eu] = f[e] + w, lase[eu] = i;
if (!vis[eu]) {
vis[eu] = true;
que.push(eu);
}
}
}
}
} Node** hs;
inline void rebuild() {
for (int i = ; i <= n; i++)
for (int j = g.h[i]; j; j = g[j].next) {
int e = g[j].end;
if (lase[i] != j)
g[j].w += f[e] - f[i];
} hs = new Node*[(n + )];
que.push(t);
hs[t] = NULL;
while (!que.empty()) {
int e = que.front();
que.pop();
if (lase[e])
hs[e] = hs[g[lase[e]].end];
for (int i = g.h[e]; i; i = g[i].next)
if (lase[e] != i && f[g[i].end] != 0x7f7f7f7f)
hs[e] = merge(hs[e], new Node(g[i].w, g[i].end, NULL, NULL));
for (int i = rg.h[e]; i; i = rg[i].next) {
int eu = rg[i].end;
if (lase[eu] == i)
que.push(eu);
}
}
} inline int kthpath(int k) {
if (s == t)
k++;
if (f[s] == 0x7f7f7f7f)
return -;
if (k == )
return f[s]; priority_queue<Status> q;
if (!hs[s])
return -; q.push(Status(hs[s]->val, hs[s]));
while (--k && !q.empty()) {
Status e = q.top();
q.pop(); if(k == )
return e.dist + f[s]; int eu = e.p->ed;
if (hs[eu])
q.push(Status(e.dist + hs[eu]->val, hs[eu]));
if (e.p->l)
q.push(Status(e.dist - e.p->val + e.p->l->val, e.p->l));
if (e.p->r)
q.push(Status(e.dist - e.p->val + e.p->r->val, e.p->r));
}
return -;
} inline void solve() {
printf("%d\n", kthpath(k));
} int main() {
init();
spfa(rg, t);
rebuild();
solve();
return ;
}
最短路算法+可持久化堆
特别鸣谢
YJQ
ZJC
浅谈k短路算法的更多相关文章
- 浅谈URLEncoder编码算法
一.为什么要用URLEncoder 客户端在进行网页请求的时候,网址中可能会包含非ASCII码形式的内容,比如中文. 而直接把中文放到网址中请求是不允许的,所以需要用URLEncoder编码地址, 将 ...
- 浅谈Hex编码算法
一.什么是Hex 将每一个字节表示的十六进制表示的内容,用字符串来显示. 二.作用 将不可见的,复杂的字节数组数据,转换为可显示的字符串数据 类似于Base64编码算法 区别:Base64将三个字节转 ...
- 浅谈Base64编码算法
一.什么是编码解码 编码:利用特定的算法,对原始内容进行处理,生成运算后的内容,形成另一种数据的表现形式,可以根据算法,再还原回来,这种操作称之为编码. 解码:利用编码使用的算法的逆运算,对经过编码的 ...
- k短路算法
k短路算法 求解k短路用到了A* 算法,A* ( A star )算法,又称启发式搜索算法,与之相对的,dfs与bfs都成为盲目型搜索:即为带有估价函数的优先队列BFS称为A*算法. 该算法的核心思想 ...
- 浅谈分布式共识算法raft
前言:在分布式的系统中,存在很多的节点,节点之间如何进行协作运行.高效流转.主节点挂了怎么办.如何选主.各节点之间如何保持一致,这都是不可不面对的问题,此时raft算法应运而生,专门 用来解决上述问题 ...
- 浅谈关于特征选择算法与Relief的实现
一. 背景 1) 问题 在机器学习的实际应用中,特征数量可能较多,其中可能存在不相关的特征,特征之间也可能存在相关性,容易导致如下的后果: 1. 特征个数越多,分析特征.训练模型所需的时间就越 ...
- 浅谈K-means聚类算法
K-means算法的起源 1967年,James MacQueen在他的论文<用于多变量观测分类和分析的一些方法>中首次提出 “K-means”这一术语.1957年,贝尔实验室也将标准算法 ...
- 浅谈数据结构-Boyer-Moore算法
上文讲解了KMP算法,这种算法在字符串匹配中应用比较少,在各种文本编辑器中的查找功能大多采用Boyer-Moore算法.1977年,德克萨斯大学的Robert S. Boyer教授和J Strothe ...
- Kmp算法浅谈
Kmp算法浅谈 一.Kmp算法思想 在主串和模式串进行匹配时,利用next数组不改变主串的匹配指针而是改变模式串的匹配指针,减少大量的重复匹配时间.在Kmp算法中,next数组的构建是整个Kmp算法的 ...
随机推荐
- ASP.Net Core 2.2 MVC入门到基本使用系列 (一)(转)
本教程会对基本的.Net Core 进行一个大概的且不会太深入的讲解, 在您看完本系列之后, 能基本甚至熟练的使用.Net Core进行Web开发, 感受到.Net Core的魅力. 本教程知识点大体 ...
- sift拟合详解
1999年由David Lowe首先发表于计算机视觉国际会议(International Conference on Computer Vision,ICCV),2004年再次经David Lowe整 ...
- MySQL.Linux.安装
Linux 7.x.安装 MySQL 环境: linux是安装在虚拟机中的,宿主机是:win10系统.安装MySQL的时候,首先需要网络是通的(宿主机和虚拟机之间通信).相关配置,参见:虚拟机和宿主机 ...
- python pillow
https://www.cnblogs.com/morethink/p/8419151.html#%E7%9B%B4%E6%8E%A5%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA ...
- Hotfix
http://group.jobbole.com/6311/ http://www.jianshu.com/p/6f0ae1e364d9 http://www.mamicode.com/info-de ...
- [5]传奇3服务器源码分析一GameServer
1. 2. 留存 服务端下载地址: 点击这里
- <<attention is all you need>>速读笔记
背景 在seq2seq中,一般是有一个encoder 一个decoder ,一般是rnn/cnn 但是rnn 计算缓慢,所以提出了纯用注意力机制来实现编码解码. 模型结构 大部分神经序列转导模型都有一 ...
- codeoforces 975B Mancala
题意: 一个游戏,有14个洞,每个洞中开始有若干个球或者没有球. 每一步的操作,是将一个洞中的所有球取出,再逆时针放一个球到它的后一个洞,后两个洞,后三个洞....如果当前放的是最后一个,那么下一个又 ...
- python 数据序列化(json、pickle、shelve)
本来要查一下json系列化自定义对象的一个问题,然后发现这篇博客(https://www.cnblogs.com/yyds/p/6563608.html)很全面,感谢作者,关于python序列化的知识 ...
- 设置 DNS,防止 DNS 污染,清除 DNS 缓存ipconfig /flushdns
设置 DNS,防止 DNS 污染选中“使用下面的 DNS 服务器地址”,“首选 DNS 服务器”中填写 8.8.8.8,“备用 DNS 服务器”中填写 8.8.4.4,然后点击“确定”按钮清除 DNS ...