Hadoop安装教程_集群/分布式配置
配置集群/分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加一行内容:Slave1。
2, 文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:</value>
</property>
</configuration>
5, 文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
在 Slave1 节点上执行:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
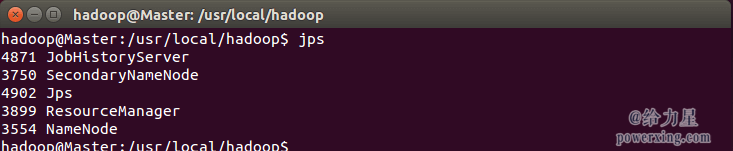
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:

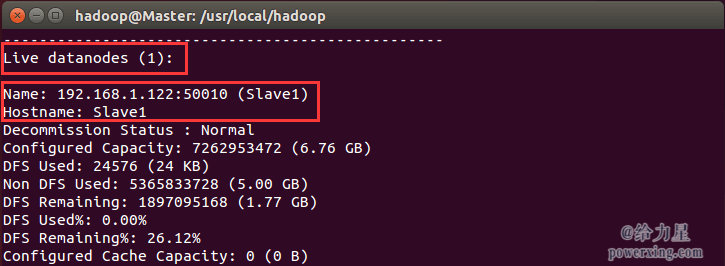
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:
hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
hdfs dfs -mkdir input
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:

接着就可以运行 MapReduce 作业了:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
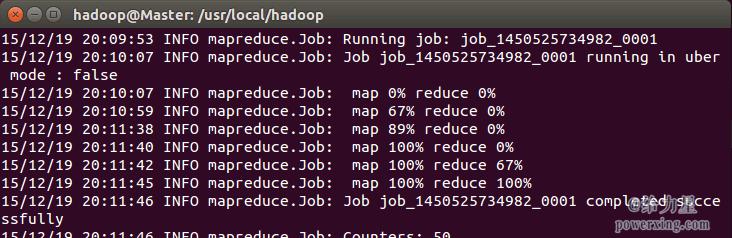
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
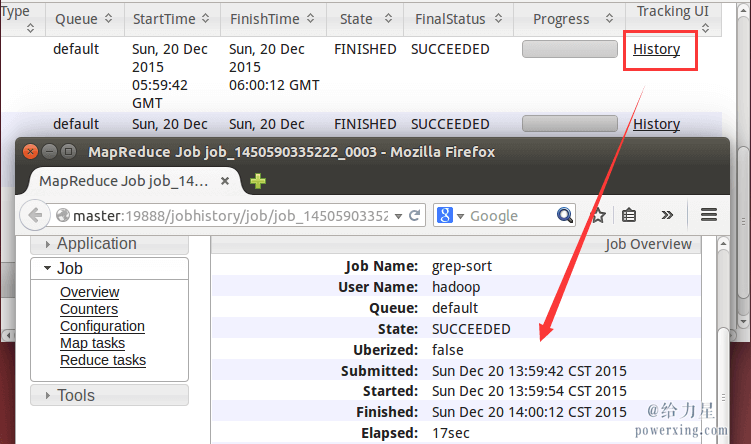
同样可以通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
执行完毕后的输出结果:
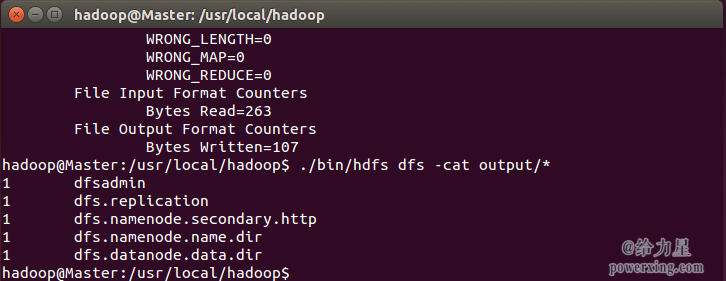
关闭 Hadoop 集群也是在 Master 节点上执行的:
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
此外,同伪分布式一样,也可以不启动 YARN,但要记得改掉 mapred-site.xml 的文件名。
自此,你就掌握了 Hadoop 的集群搭建与基本使用了。
相关教程
- 使用Eclipse编译运行MapReduce程序: 用文本编辑器写 Java 程序是不靠谱的,还是用 Eclipse 比较方便。
- 使用命令行编译打包运行自己的MapReduce程序: 有时候需要直接通过命令来编译 MapReduce 程序
Hadoop安装教程_集群/分布式配置的更多相关文章
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
- 【转】Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文链接:http://dblab.xmu.edu.cn/blog/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单, ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- Dubbo入门到精通学习笔记(十七):FastDFS集群的安装、FastDFS集群的配置
文章目录 FastDFS集群的安装 FastDFS 介绍(参考:http://www.oschina.net/p/fastdfs) FastDFS 上传文件交互过程: FastDFS 下载文件交互过程 ...
随机推荐
- AngularJS中使用$http对MongoLab数据表进行增删改查
本篇体验使用AngularJS中的$http对MongoLab数据表进行增删改查. 主页面: <button ng-click="loadCourse()">Load ...
- Alpha通道
Alpha通道是计算机图形学中的术语,指的是特别的通道,意思是“非彩色”通道,主要是用来保存选区和编辑选区.真正让图片变透明的不是Alpha 实际是Alpha所代表的数值和其他数值做了一次运算 为 ...
- SSH框架搭建详细图文教程(转)
这篇文章看的我醍醐灌顶的感觉,比之前本科时候学习的SSH架构 要清晰数倍 非常感觉这篇博主的文章 文章链接为:http://blog.sina.com.cn/s/blog_a6a6b3cd01017 ...
- WIN10平板 如何修改网络IP地址为固定
右击网络,属性,更改适配器设置,然后可以找到当前的无线网络 然后依次点开即可修改IP地址
- Duplicate复制数据库并创建物理StandBy(spfile版本)
过程和Duplicate复制数据库并创建物理StandBy类似,只是不需要重启数据库. 目的:创建standby,不重启源数据库 1设定环境如下: Primary数据库 IP 172.17.22.16 ...
- python3用BeautifulSoup抓取id='xiaodeng',且正则包含‘elsie’的标签
# -*- coding:utf-8 -*- #python 2.7 #XiaoDeng #http://tieba.baidu.com/p/2460150866 #使用多个指定名字的参数可以同时过滤 ...
- WWDC 2018:Swift 更新了什么?
本文转载自:https://juejin.im/post/5b1cb5805188257d507be5d4所有权归原文所有 WWDC 2018 Session 401 What's New in Sw ...
- Uber使用Swift重写APP的踩坑经历及解决方案(转载)
本文出自Uber移动架构和框架组负责人托马斯·阿特曼于2016年在湾区Swift峰会上的演讲,分享了使用Swfit重写Uber的好与坏.以下为译文: 我是托马斯·阿特曼,目前是Uber移动架构和框架组 ...
- Swift Assert 断言
前言 对每次运行都会出现的错误通常不会过于苦恼,可以使用断点调试或者 try catch 之类的方式判断并修复它.但是一些偶发(甚至是无数次运行才会出现一次)的错误单靠断点之类的方式是很难排除掉的,为 ...
- Hyper-V 怎样拷贝文件至虚拟硬盘并附加到虚拟机上
对于大文件来说,通过远程桌面拷贝是件麻烦的事情,虽然简单,但速度受限太多,不推荐使用. 我工作中对于大文件的拷贝,通过创建一个新的虚拟硬盘(VHD),再把大文件拷贝至虚拟硬盘中,最后附加到虚拟机上. ...