spark基础---->spark的第一个程序
这里面我们介绍一下spark的安装,并通过一个python的例子来简单的体会一下spark的使用。
spark的安装与使用
安装环境:mac 10.13.6,spark版本:2.3.1,python版本:3.6.5
一、在mac上面安装spark和pyspark,可以使用brew包管理器安装。直接运行命令
> brew install apache-spark
> pip install pyspark
二、通过start-master启动我们的集群
> ./start-master.sh

然后我们访问:http://localhost:8080/,就可以看到集群相关的信息。
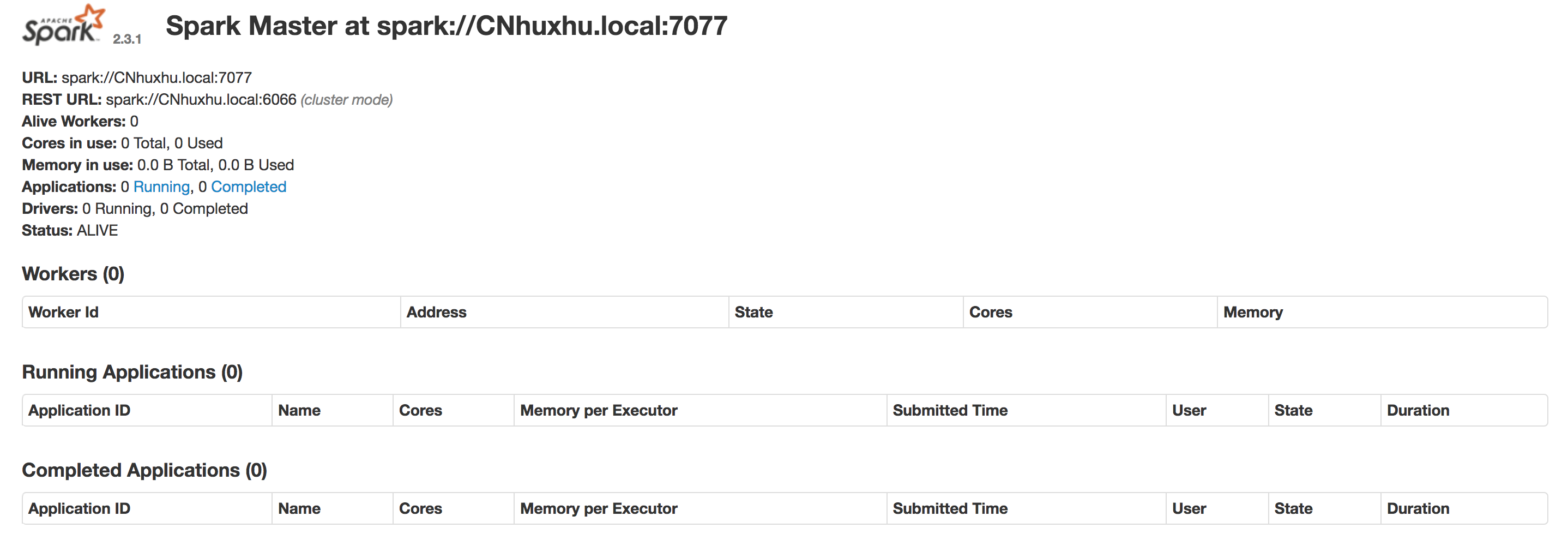
三、启动我们的worker。
> ./start-slave.sh spark://CNhuxhu.local:7077

再次访问http://localhost:8080/,可以在workers里面看到我们启动的worker信息。

四、编写我们的第一个spark的python程序
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("FirstApp").setMaster("spark://CNhuxhu.local:7077")
sc = SparkContext(conf=conf)
lines = sc.textFile('/usr/local/Cellar/apache-spark/2.3.1/README.md')
print('counts = ', lines.count())
五、提交到spark中处理
spark-submit --master local[4] simpleSpark.py
可以在控制台看到如下的打印信息:
counts = 103
程序中遇到的一些问题
一、运行程序报以下的错误
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
这是由于我们的mac本地安装的java版本有jdk8和jdk10,但是默认的是jdk10。spark2.3.1要求的jdk版本是1.8,所以修改系统的jdk版本问题解决。vim ~/.zshrc,添加以下内容
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_162.jdk/Contents/Home
二、查看系统安装jdk的java_home命令
usr/libexec/java_home -V
可以查看系统安装的所有java以及JAVA_HOME的信息
Matching Java Virtual Machines (2):
10.0.2, x86_64: "Java SE 10.0.2" /Library/Java/JavaVirtualMachines/jdk-10.0.2.jdk/Contents/Home
1.8.0_162, x86_64: "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_162.jdk/Contents/Home /Library/Java/JavaVirtualMachines/jdk-10.0.2.jdk/Contents/Home
三、以下是一个java版本的spark程序
项目是由maven构建的,在pom.xml添加所需的依赖。
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
我们编写的java代码如下:
package com.linux.huhx; import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession; /**
* user: huxhu
* date: 2018/8/11 3:40 PM
**/
public class SimpleSpark {
public static void main(String[] args) {
String logFile = "/usr/local/Cellar/apache-spark/2.3.1/README.md"; // Should be some file on your system
SparkSession spark = SparkSession.builder().appName("Simple Application").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache(); long numAs = logData.filter(s -> s.contains("a")).count();
long numBs = logData.filter(s -> s.contains("b")).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); spark.stop();
}
}
mvn package打包项目,在target目录下生成可执行的sparkLearn-1.0-SNAPSHOT.jar文件。最后执行spark-submit命令
spark-submit --class "com.linux.huhx.SimpleSpark" --master local[] target/sparkLearn-1.0-SNAPSHOT.jar
可以在控制台看到如下的日志打印
Lines with a: 61, lines with b: 30
友情链接
spark基础---->spark的第一个程序的更多相关文章
- Java 零基础跑起第一个程序
Java 零基础跑起第一个程序 一 概述 1 java代码编译 编译后才干在计算机中执行.编译就是把人能看懂的代码转换成机器能看懂的形式 2 java的长处 一次编译.到处执行.由于java代码是在 ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- C#基础知识-编写第一个程序(二)
通过上一篇数据类型已经介绍了C#中最基本的15种预定义数据类型,了解每一种类型代表的数据以及每种类型的取值范围,这是很重要也是最基本.下面我们通过实例来了解每个类型如何去使用.编写C#程序时我们需要用 ...
- Go基础---->go的第一个程序
今天我们学习搭建一个学习go语言的开发环境. Go语言 一.下载go 下载地址:https://golang.org/dl/ 校验下载,在命令行输入go version 二.编写第一个hello wo ...
- cocos2dx基础篇(2) 第一个程序
[本节内容] 1.程序的基本组成:CCSprite(精灵).CCLayer(层).CCScene(场景).CCDirector(导演) 2.分析HelloWorld源码. 一.基本组成 cocos2d ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark菜鸟学习营Day5 分布式程序开发
Spark菜鸟学习营Day5 分布式程序开发 这一章会和我们前面进行的需求分析进行呼应,完成程序的开发. 开发步骤 分布式系统开发是一个复杂的过程,对于复杂过程,我们需要分解为简单步骤的组合. 针对每 ...
- spark基础知识
1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架. dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopM ...
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
随机推荐
- EBS MOAC
alter session set nls_language='SIMPLIFIED CHINESE';alter session set nls_language ='AMERICAN'; exec ...
- Queue depth
Queue depth - It is the number of I/O requests that can be kept waiting to be serviced in a port que ...
- sql server management studio 查询的临时文件路径
C:\Users\你的登录名称\Documents\SQL Server Management Studio\Backup Files C:\Users\你的登录名称\AppData\Local\Te ...
- 【PMP】项目、项目集、项目组合
项目:为创建独特的产品和服务成果而进行的临时性工作. 项目集:是一组相互关联且被协调管理的项目.子项目集和项目活动,以便获得分别管理所无法获得的利益. 项目组合:是指实现战略目标而组合在一起管理的项目 ...
- Oracle11g登录名和密码不区分大小写
问题描述: oracle11g对账户密码实行大小写识别,烦的一比!想移除此限制 问题解决: oracle 11g以前的版本的用户名和密码是不区分大小写!oracle 11g 用户名和密码默认区分大小写 ...
- 【Windows】创建任务计划
任务计划,可以将任何脚本.程序或文档安排在某个时间运行. 可以按照如下的方式来启动:附件 -> 系统工具 -> 任务计划程序. 也可以在Win+R后,输入:taskschd.msc 命令来 ...
- 10.翻译系列:EF 6中的Fluent API配置【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/fluent-api-in-code-first.aspx EF 6 Code-Firs ...
- 并发和多线程-八面玲珑的synchronized
上篇<并发和多线程-说说面试常考平时少用的volatile>主要介绍的是volatile的可见性.原子性等特性,同时也通过一些实例简单与synchronized做了对比. 相比较volat ...
- 用.NET CORE做项目,VS里编译碰到‘。。。。包降级。。。。’错误
用.NET CORE做项目,VS里编译碰到‘....包降级....’错误 本地开发机:WIN10+VS2017 15.7.3 ,用CORE2.1版本的建立一个项目,做好了,传到gitee上 今天有新同 ...
- [k8s]docker calico网络&docker cluster-store
docker cluster-store选项 etcd-calico(bgp)实现docker夸主机通信 配置calico网络 - 启动etcd etcd --listen-client-urls h ...