SQL执行计划之sql_trace
一,sql_trace的作用:用以描述SQL的执行过程的trace输出。
SQL>alter session set max_dump_file_size = unlimited;
SQL>alter session set tracefile_identifier = liangjian

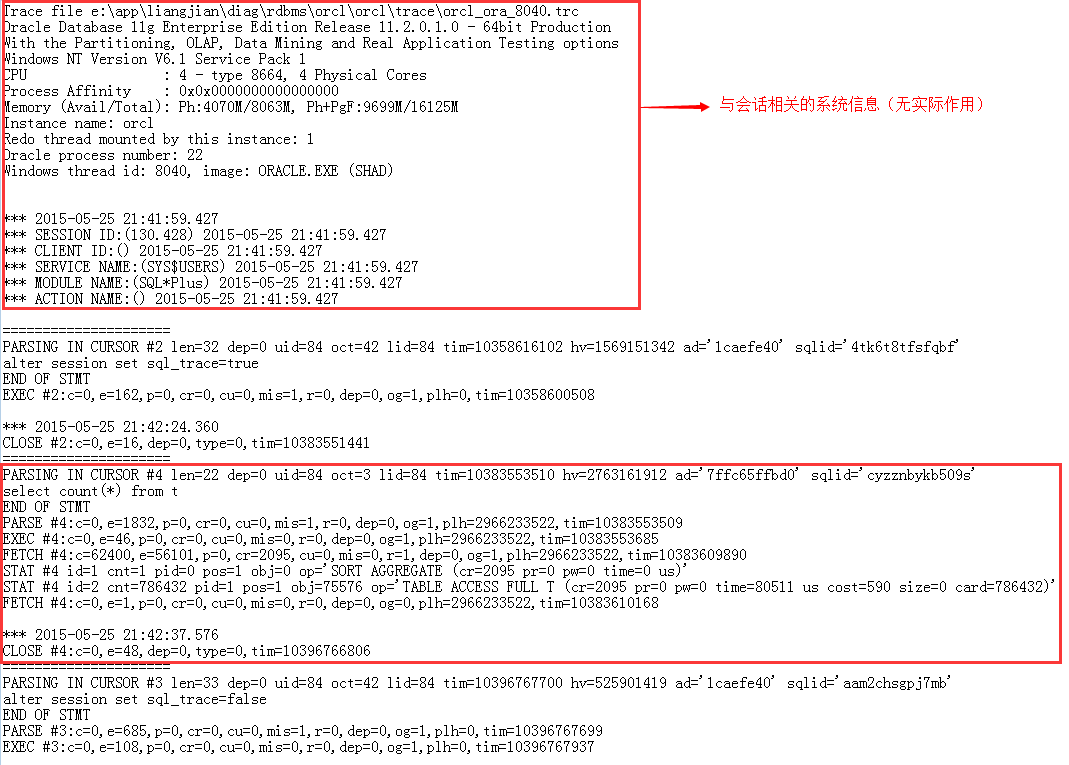
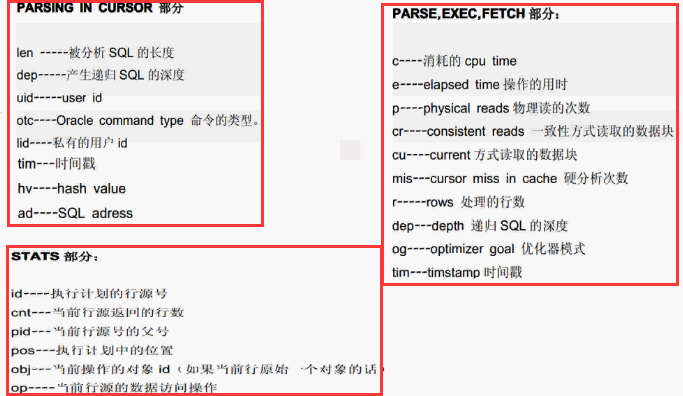
六,tkprof格式化工具

SQL执行计划之sql_trace的更多相关文章
- Oracle中SQL调优(SQL TUNING)之最权威获取SQL执行计划大全
该文档为根据相关资料整理.总结而成,主要讲解Oracle数据库中,获取SQL语句执行计划的最权威.最正确的方法.步骤,此外,还详细说明了每种方法中可选项的意义及使用方法,以方便大家和自己日常工作中查阅 ...
- Oracle查看SQL执行计划的方式
Oracle查看SQL执行计划的方式 获取Oracle sql执行计划并查看执行计划,是掌握和判断数据库性能的基本技巧.下面案例介绍了多种查看sql执行计划的方式: 基本有以下几种方式: ...
- Atitit sql执行计划
Atitit sql执行计划 1.1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的 Oracle中的执行计划 ...
- 查看SQL执行计划
一用户进入某界面慢得要死,查看SQL执行计划如下(具体SQL语句就不完全公布了,截断的如下): call count cpu elapsed disk ...
- 查看Oracle SQL执行计划的常用方式
在查看SQL执行计划的时候有很多方式 我常用的方式有三种 SQL> explain plan for 2 select * from scott.emp where ename='KING'; ...
- sql执行计划解析案例(二)
sql执行计划解析案例(二) 今天是2013-10-09,本来以前自己在专注oracle sga中buffer cache 以及shared pool知识点的研究.但是在研究cache buffe ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- DB查询分析器7.01新增的周、月SQL执行计划功能
DB查询分析器7.01新增的周.月SQL执行计划功能 马根峰 (广东联合电子服务股份有限公司, 广州 510300) 1 引言 中国本土 ...
- SQL优化 MySQL版 -分析explain SQL执行计划与笛卡尔积
SQL优化 MySQL版 -分析explain SQL执行计划 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 首先我们先创建一个数据库,数据库中分别写三张表来存储数据; course: ...
随机推荐
- linux-文件系统-5
cat /proc/partions cat /proc/mounts mount [options] -o [option] -t 文件类型 设备 挂载目录 设备: (1)设备文件:例如/dev/s ...
- mini-batch
我们在训练神经网络模型时,最常用的就是梯度下降,梯度下降有一下几种方式: 1.Batch gradient descent(BGD批梯度下降) 遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度 ...
- BZOJ 4422 Cow Confinement (线段树、DP、扫描线、差分)
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=4422 我真服了..这题我能调一天半,最后还是对拍拍出来的...脑子还是有病啊 题解: ...
- c++中的类(构造函数,析构函数的执行顺序)
类对象的初始化顺序 新对象的生成经历初始化阶段(初始化列表显式或者隐式的完成<这部分有点像java里面的初始化块>)——> 构造函数体赋值两个阶段 1,类对象初始化的顺序(对于没有父 ...
- mysql-8.0解压缩版安装配置完整过程
https://www.cnblogs.com/xiongzaiqiren/p/8970203.html
- 浏览器端-W3School:JS & DOM 参考手册
ylbtech-浏览器端-W3School:JS & DOM 参考手册 1.返回顶部 1. JavaScript 参考手册 本部分提供完整的 JavaScript 参考手册: JavaScri ...
- Delphi XE2 之 FireMonkey 入门(43) - 控件基础: TStringGrid、TGrid
Delphi XE2 之 FireMonkey 入门(43) - 控件基础: TStringGrid.TGrid TStringGrid.TGrid 都是从 TCustomGrid 继承; 区别有:1 ...
- Object.freeze与 Object.seal的区别
Object.freeze()冻结一个对象.不能添加新的属性,不能删除已有属性,不能修改该对象已有属性的可枚举性.可配置性.可写性,以及不能修改已有属性的值.冻结一个对象后该对象的原型也不能被修改. ...
- 阶段3 1.Mybatis_09.Mybatis的多表操作_5 完成user的一对多查询操作
定义List<Account> accounts,生成getter和setter 复制AccountTest类改名UserTest类 修改测试类 还没封装所以Account的list都是n ...
- Django-DRF组件学习-环境安装与配置与序列化器学习
1.DRF环境安装与配置 DRF需要以下依赖: Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6) Django (1.10, 1.11, 2.0) DRF是以Django扩展 ...