小白学 Python 爬虫(26):为啥上海二手房你都买不起

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
引言
看到题目肯定有同学会问,为啥不包含新房,emmmmmmmmmmm
说出来都是血泪史啊。。。

小编已经哭晕在厕所,那位同学赶紧醒醒,太阳还没下山呢。
别看不起二手房,说的好像大家都买得起一样。

分析
淡不多扯,先进入正题,目标页面的链接小编已经找好了:https://sh.lianjia.com/ershoufang/pg1/ 。

房源数量还是蛮多的么,今年正题房产行业不景气,据说 房价都不高。
小编其实是有目的的,毕竟也来上海五年多了,万一真的爬出来的数据看到有合适,对吧,顺便也能帮大家探个路。

首先还是分析页面的链接信息,其实已经很明显了,在链接最后一栏有一个 pg1 ,小编猜应该是 page1 的意思,不信换成 pg2 试试看,很显然的么。
随便打开一个房屋页面进到内层页面,看下数据:
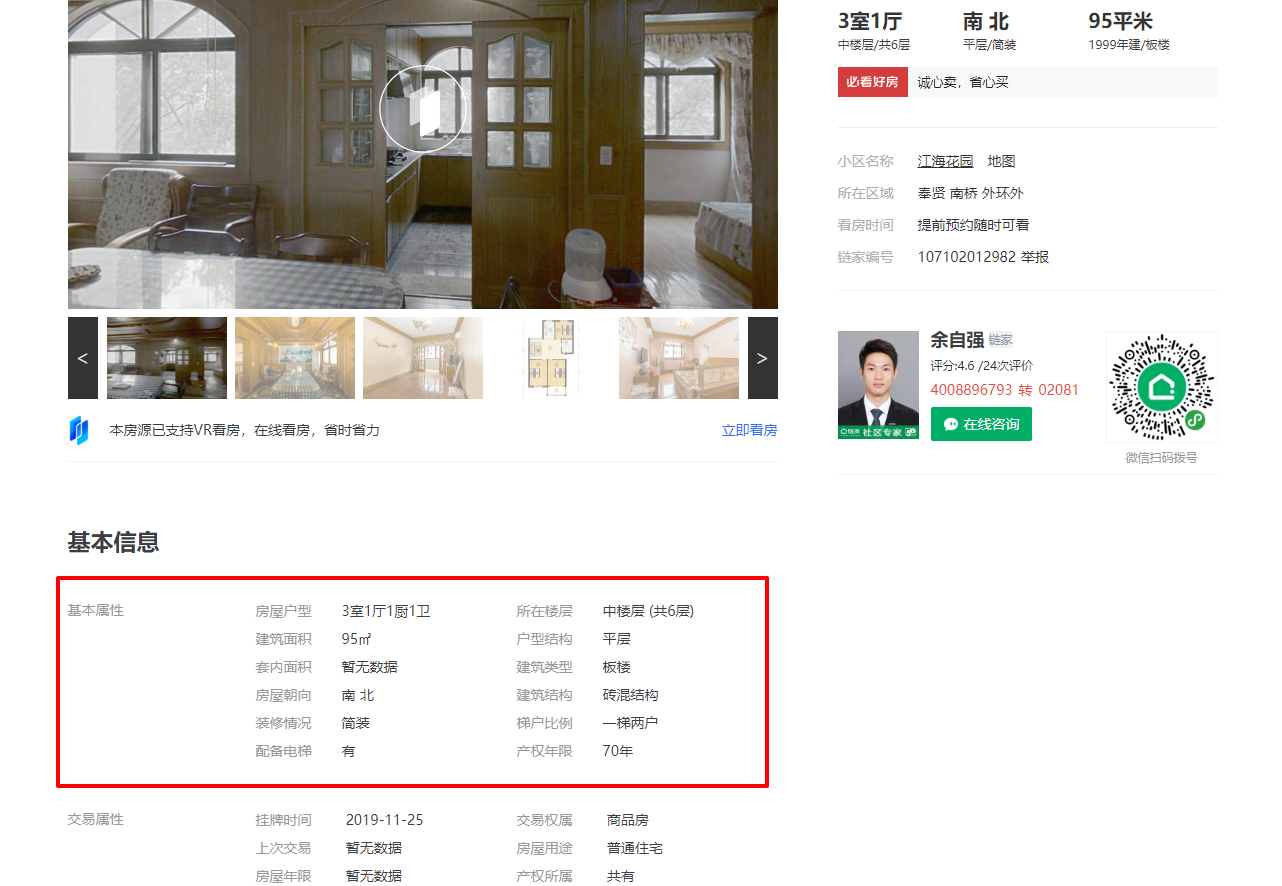
数据还是很全面的嘛,那详细数据就从这里取了。
顺便再看下详情页的链接:https://sh.lianjia.com/ershoufang/107102012982.html 。
这个编号从哪里来?
小编敢保证在外层列表页的 DOM 结构里肯定能找到。

这就叫老司机的直觉,秀不秀就完了。

撸代码
思想还是老思想,先将外层列表页的数据构建一个列表,然后通过循环那个列表爬取详情页,将获取到的数据写入 Mysql 中。
本篇所使用到的请求库和解析库还是 Requests 和 pyquery 。
别问为啥,问就是小编喜欢。
因为简单。

还是先定义一个爬取外层房源列表的方法:
def get_outer_list(maxNum):
list = []
for i in range(1, maxNum + 1):
url = 'https://sh.lianjia.com/ershoufang/pg' + str(i)
print('正在爬取的链接为: %s' %url)
response = requests.get(url, headers=headers)
print('正在获取第 %d 页房源' % i)
doc = PyQuery(response.text)
num = 0
for item in doc('.sellListContent li').items():
num += 1
list.append(item.attr('data-lj_action_housedel_id'))
print('当前页面房源共 %d 套' %num)
return list
这里先获取房源的那个 id 编号列表,方便我们下一步进行连接的拼接,这里的传入参数是最大页数,只要不超过实际页数即可,目前最大页数是 100 页,这里最大也只能传入 100 。
房源列表获取到以后,接着就是要获取房源的详细信息,这次的信息量有点大,解析起来稍有费劲儿:
def get_inner_info(list):
for i in list:
try:
response = requests.get('https://sh.lianjia.com/ershoufang/' + str(i) + '.html', headers=headers)
doc = PyQuery(response.text)
# 基本属性解析
base_li_item = doc('.base .content ul li').remove('.label').items()
base_li_list = []
for item in base_li_item:
base_li_list.append(item.text())
# 交易属性解析
transaction_li_item = doc('.transaction .content ul li').items()
transaction_li_list = []
for item in transaction_li_item:
transaction_li_list.append(item.children().not_('.label').text())
insert_data = {
"id": i,
"danjia": doc('.unitPriceValue').remove('i').text(),
"zongjia": doc('.price .total').text() + '万',
"quyu": doc('.areaName .info').text(),
"xiaoqu": doc('.communityName .info').text(),
"huxing": base_li_list[0],
"louceng": base_li_list[1],
"jianmian": base_li_list[2],
"jiegou": base_li_list[3],
"taoneimianji": base_li_list[4],
"jianzhuleixing": base_li_list[5],
"chaoxiang": base_li_list[6],
"jianzhujiegou": base_li_list[7],
"zhuangxiu": base_li_list[8],
"tihubili": base_li_list[9],
"dianti": base_li_list[10],
"chanquan": base_li_list[11],
"guapaishijian": transaction_li_list[0],
"jiaoyiquanshu": transaction_li_list[1],
"shangcijiaoyi": transaction_li_list[2],
"fangwuyongtu": transaction_li_list[3],
"fangwunianxian": transaction_li_list[4],
"chanquansuoshu": transaction_li_list[5],
"diyaxinxi": transaction_li_list[6]
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(i, ':写入完成')
except:
print(i, ':写入异常')
continue
两个最关键的方法已经写完了,接下来看下小编的成果:
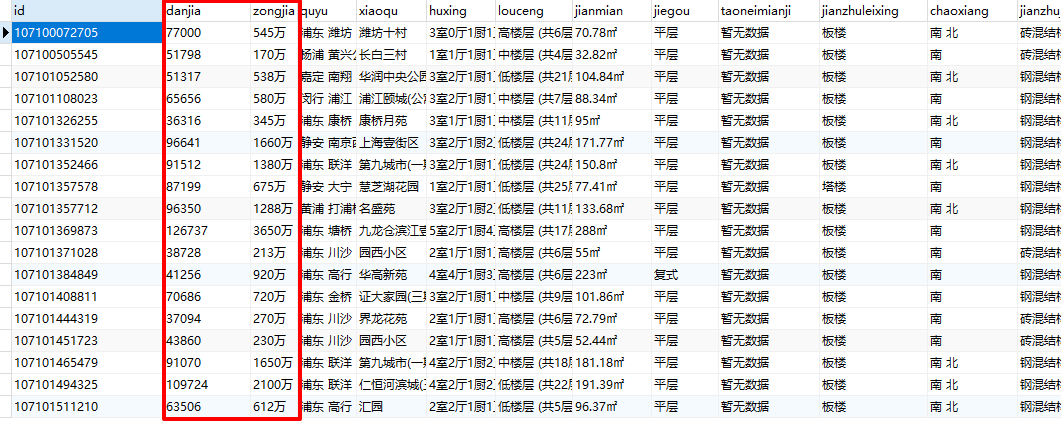
这个价格看的小编血压有点高。

果然还是我大魔都,不管几手房,价格看看就好。
小结
从结果可以看出来,链家虽然是说的有 6W 多套房子,实际上我们从页面上可以爬取到的拢共也就只有 3000 套,远没有达到我们想要的所有的数据。但是小编增加筛选条件,房源总数确实也是会变动的,应该是做了强限制,最多只能展示 100 页的数据,防止数据被完全爬走。
套路还是很深的,只要不把数据放出来,泥萌就不要想能爬到我的数据。对于一般用户而言,能看到前面的一些数据也足够了,估计也没几个人会翻到最后几页去看数据。

本篇的代码就到这里了,如果有需要获取全部代码的,可以访问代码仓库获取。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
小白学 Python 爬虫(26):为啥上海二手房你都买不起的更多相关文章
- 小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(30):代理基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(31):自己构建一个简单的代理池
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- python time 和日期相关模块
时间日期相关的模块 calendar 日历模块 time 时间模块 datetime 日期时间模块 timeit 时间检测模块 日历模块 calendar() 功能:获取指定年份的日历字符串 格式:c ...
- Reinforcement Learning for Self Organization and Power Control of Two-Tier Heterogeneous Networks
R. Amiri, M. A. Almasi, J. G. Andrews and H. Mehrpouyan, "Reinforcement Learning for Self Organ ...
- [Linux] 027 RPM 包与 源码包的区别
1. 区别 安装之前的区别: 概念上的区别 安装之后的区别: 安装位置不同 2. RPM 包安装位置 安装在默认位置中 RPM 包默认安装路径 明细 /ect 配置文件安装目录 /usr/bin/ 可 ...
- spring-第八篇之容器中的bean的生命周期
1.容器中的bean的生命周期 spring容器可以管理singleton作用域的bean的生命周期,包括bean何时被创建.何时初始化完成.何时被销毁.客户端代码不能控制该类型bean的销毁.spr ...
- CentOS安装Prolog和Erlang语言
安装Erlang比较简单 下载Erlang的压缩包 输入tar -zxvf 压缩包 解压 进入解压的目录下 输入./configure 在./configure执行完成后,输入make 然后输入mak ...
- bfs(双向bfs加三维数组)
http://acm.hdu.edu.cn/showproblem.php?pid=2612 Find a way Time Limit: 3000/1000 MS (Java/Others) ...
- 2019 Multi-University Training Contest 1 - 1004 - Vacation - 二分 - 思维
http://acm.hdu.edu.cn/showproblem.php?pid=6581 一开始想了好几个假算法.但是启发了一下潘哥,假如时间知道的话就可以从头开始确定各个车的位置.那么直接 \( ...
- supermap idesktop连接oraclesptial数据源
1.要使用相同的版本,如iServer 9D, iDesktop9D ,32位的 plsql,32位的 oracleinstance_client 11g 2.当时遇到的问题是使用oracleinst ...
- Python人工智能识别文字内容(OCR)
环境准备 安装pytesseract和PIL 安装这两个包可以借助pip命令行安装 pip install PIL pip install pytesseract 安装识别引擎tesseract-oc ...
- 机器学习-线性回归(基于R语言)
基本概念 利用线性的方法,模拟因变量与一个或多个自变量之间的关系.自变量是模型输入值,因变量是模型基于自变量的输出值. 因变量是自变量线性叠加和的结果. 线性回归模型背后的逻辑——最小二乘法计算线性系 ...