Hadoop 架构与原理
1.1. Hadoop架构
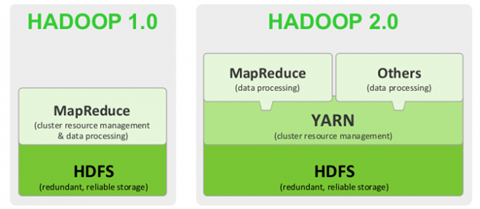
Hadoop1.0版本两个核心:HDFS+MapReduce
Hadoop2.0版本,引入了Yarn。核心:HDFS+Yarn+Mapreduce
Yarn是资源调度框架。能够细粒度的管理和调度任务。此外,还能够支持其他的计算框架,比如spark等。
1.2. HDFS设计
单台机器的硬件扩展
纵向扩展的问题,是有硬件瓶颈的,包括成本也会指数型增长。
1.3. namenode工作职责:
1.要知道管理有哪些机器节点,即有哪些datanode。比如ip信息等。
2.要管理文件信息,文件名、文件多大、文件被切成几块、以及每一块的存贮位置信息(存在哪个datanode节点上了),即管理元数据信息。
3.要有一个机制要知道集群里datanode节点的状态变化。可以rpc心跳机制来做到。
4.namenode存在单点故障问题,可以再引入一台管理者节点。
5.datanode挂掉后,可能数据就丢失,文件就不完整了,要有一个备份机制,一般来说,一个文件块,有3个备份,本机一份,同一机架的其他datanode有一份,另外一机器的机器上有一份。
1.4. HDFS细节说明
1.4.1. Hadoop块概念
Hadoop1.0是按64MB切,BlockSize=64MB
Hadoop2.0 BlockSize=128MB
1.4.2. namenode
管理元数据信息,文件名,文件大小,文件块信息等。
namdenode把元数据信息存到内存里,为了快速查询,此外为了应对服务宕机而引起的元数据丢失,也要持久化到本地文件里。
namdenode不存储具体块数据,只存储元数据信息;datanode用于负责存储块数据。
1.4.3. fsimage、edits
fsimage 文件,记录元数据信息的文件
edits文件,记录元数据信息改动的文件。只要元数据发生变化,这个edits文件就会有对应记录。
fsimage和edits文件会定期做合并,这个周期默认是3600s。fsimage根据edits里改动记录进行元数据更新。
元数据信息如果丢失,HDFS就不能正常工作了。
hadoop namenode -format 这个指令实际的作用时,创建了初始的fsimage文件和edits文件。
1.4.4. Secondarynamenode
负责将fsimage文件定期和edits文件做合并,合并之后,将合并后的元数据文件fsimage传给namenode。这个SN相当于namenode辅助节点。
Hadoop集群最开始启动的时候,创建Fsimage和edits文件,这个namenode做的,此外,namenode会做一次文件合并工作,这么做的目的是确保元数据信息是最新的,以为上次停集群的时候,可能还没来的及做合并。但以后的合并工作,就交给SN去做了。这种SN机制是Hadoop1.0的机制。
结论:Hadoop1.0的SN达不到热备效果,达不到元数据的实时更新,也就意味着了当namenode挂了的时候,元数据信息可能还会丢失,所以,Hadoop1.0版本的namenode还是单点故障问题。
1.5. HDFS架构图

1.5.1. namenode
名字节点。要管理元数据信息(Metadata),注意,只存储元数据信息。
namenode对于元数据信息的管理,放在内存一份,供访问查询,也会通过fsimage和edits文件,将元数据信息持久化到磁盘上。Hadoop1.0版本利用了SecondaryNamenode做fsimage和edits文件的合并,但是这种机制达不到热备的效果。Hadoop1.0的namenode存在单点故障问题。
1.5.2. datanode
数据节点。用于存储文件块。为了防止datanode挂掉造成的数据丢失,对于文件块要有备份,一个文件块有三个副本。
1.5.3. rack
机架
1.5.4. client
客户端,凡是通过API或指令操作的一端都可以看做是客户端
1.5.5. blockSize
数据块。Hadoop1.0:64MB。Hadoop2.0 :128MB。
块大小的问题。从大数据处理角度来看,块越大越好。所以从技术的发展,以后的块会越来越大,因为块大,会减少磁盘寻址次数,从而减少寻址时间
1.6. HDFS读流程图

5.
1.客户端发出读数据请求,Open File指定读取的文件路径,去找namenode要元数据信息。
2.namenode将文件的元数据信息返回给客户端。
3. 3客户端根据返回的元数据信息,去对应的datanode去读块数据。
假如一个文件特别大,比如1TB,会分成好多块,此时,namenode并是不一次性把所有的元数据信息返回给客户端。
4. 4客户端读完此部分后,再去想namenode要下一部分的元数据信息,再接着读。
5.读完之后,通知namenode关闭流
1.7. HDFS写流程
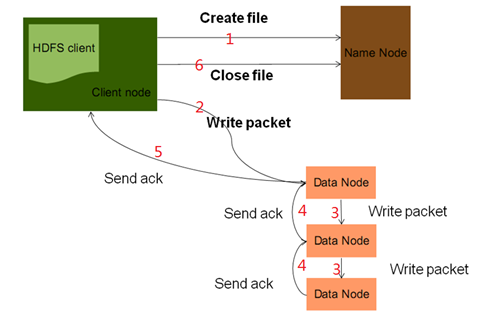
1.发起一个写数据请求,并指定上传文件的路径,然后去找namenode。namenode首先会判断路径合法性,然后会判断此客户端是否有写权限。然后都满足,namenode会给客户端返回一个输出流。此外,namenode会为文件分配块存储信息。注意,namenode也是分配块的存储信息,但不做物理切块工作。
2.客户端拿到输出流以及块存储信息之后,就开始向datanode写数据。因为一个块数据,有三个副本,所以图里有三个datanode。packet初学时可以简单理解为就是一块数据。
pipeLine:[bl1,datanode01-datanode03-datanode-07]
3.数据块的发送,先发给第一台datanode,然后再有第一台datanode发往第二台datanode,……。实际这里,用到了pipeLine 数据流管道的思想。
4.通过ack确认机制,向上游节点发送确认,这么做的目的是确保块数据复制的完整性。
5.通过最上游节点,向客户端发送ack,如果块数据没有发送完,就继续发送下一块。如果所有块数据都已发完,就可以关流了。
6.所有块数据都写完后,关流。
扩展:
数据流管道的目的:
我们的目标
是充分利用每台机器的带宽,避免网络瓶颈和高延时的连接,最小化推送所有数据的延时。 此外,利用通信的通信双工,能够提高传输效率。
packet 是一个64kb大小的数据包
Hadoop 架构与原理的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- 初步掌握Yarn的架构及原理
1.YARN 是什么? 从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性, ...
- 初步掌握Yarn的架构及原理(转)
1.YARN 是什么? 从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性, ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
- 资源管理与调度系统-YARN的基本架构与原理
资源管理与调度系统-YARN的基本架构与原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了能够对集群中的资源进行统一管理和调度,Hadoop2.0引入了数据操作系统YARN. ...
- Hadoop架构的初略总结(1)
Hadoop架构的初略总结(1) Hadoop是一个开源的分布式系统基础架构,此架构可以帮助用户可以在不了解分布式底层细节的情况下开发分布式程序. 首先我们要理清楚几个问题. 1.我们为什么需要Had ...
随机推荐
- mysql DATETIME和TIMESTAMP类型
以mysql 5.7.20 为例 一直以来,理解有偏差,作此记录,纠正 一.DATETIME和TIMESTAMP 都有高达微秒(6位)的精度 范围 DATETIME 1000-01-01 00: ...
- 【五一qbxt】day4 数论知识
这些东西大部分之前都学过了啊qwq zhx大概也知道我们之前跟着他学过这些了qwq,所以: 先讲新的东西qwq:(意思就是先讲我们没有学过的东西) 进制转换 10=23+21=1010(2) =32+ ...
- [fw]linux 下如何查看和踢除正在登陆的其它用户
linux 下如何查看和踢除正在登陆的其它用户 Posted on 2011/09/01 如何在linux下查看当前登录的用户,并且踢掉你认为应该踢掉的用户?请使用who这个命令来查看当前正在登录 ...
- hive Hsql
show databases; use flume; show tables; desc flume; alter table table_name add columns(dt string); a ...
- C#中XmlTextWriter读写xml文件详细介绍
XmlTextWriter类允许你将XML写到一个文件中去.这个类包含了很多方法和属性,使用这些属性和方法可以使你更容易地处理XML.为了使用这个类,你必须首先创建一个新的XmlTextWriter对 ...
- k3 cloud中出现合计和汇总以后没有显示出来,合价要新增一行以后才出现值
解决办法:找到对应字段,把及时触发值更新事件打上勾
- AES加密的C语言实现
摘自网上一种AES加密,用C语言实现通过32字节密钥对16字节长度数据进行加密. #include <string.h> #include <stdio.h> #ifndef ...
- Linux就该这么学10学习笔记
参考链接:https://www.linuxprobe.com/chapter-10.html 网站服务程序 第1步:把光盘设备中的系统镜像挂载到/media/cdrom目录. [root@linux ...
- 初学Java 求最大公约数
import java.util.Scanner; public class GreatesCommonDivisor { public static void main(String[] args) ...
- 【读书笔记】Cracking the Code Interview(第五版中文版)
导语 所有的编程练习都在牛客网OJ提交,链接: https://www.nowcoder.com/ta/cracking-the-coding-interview 第八章 面试考题 8.1 数组与字符 ...