mycat 配置简介
最近在看 mycat ,官网: http://www.mycat.io/ 上面就有 PDF 的教程下载。但是对于我这个初学者来讲,搭建环境的时候还是有点晕,下面从一个简单的例子来讲解相关配置。我用的是 linux 版本的,在解压后的目录记作:${MYCAT},在 ${MYCAT}/conf 目录下有几个关键的配置文件。
1. server.xml
主要用来配置 mycat 这个服务器的一些配置。程序员开发时,应该只关注一个数据库连接,但是分库分表时,数据是存在不同的物理机的 mysql 里的。 这个文件的其实配置的就是一个数据源,这个数据源可以通过 mycat 去按需连接到不同的物理机的 mysql 去获取数据。
<?xml version="1.0"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="nonePasswordLogin">0</property> <!-- 连接 mycat 的端口 -->
<property name="serverPort">8066</property>
<!-- 是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
</system> <!-- 连接 mycat 的用户和密码 -->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property><!-- 修改 schemas 内的文本来控制用户可访问的 schema,同时访问多个 schema 的话使用 , 隔开 -->
<property name="readOnly">false</property>
</user> </mycat:server>
2. schema.xml
主要用来配置 mycat 的逻辑库及其下面的表。逻辑库可以理解为 mysql 中数据库。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="auto-sharding-long" />
</schema> <dataNode name="dn1" dataHost="host108" database="stu108" />
<dataNode name="dn2" dataHost="host109" database="stu109" /> <dataHost name="host108" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select 1</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.8.108:3306" user="root" password="111111">
</writeHost>
</dataHost>
<!--
name:节点名称,在上方dataNode标签中调用
maxCon:底层数据库的链接最大数
minCon:底层数据库的链接最小数
balance:值可以为0,1,2,3,分别表示对当前datahost中维护的数据库的读操作逻辑
0:不开启读写分离,所有的读写操作都在最小的索引号的writeHost(第一个writeHost标签)
1:全部的readHost和备用writeHost都参与读数据的平衡,如果读的请求过多,负责写的第一个writeHost也分担一部分
2 :所有的读操作,都随机的在所有的writeHost和readHost中进行
3 :所有的读操作,都到writeHost对应的readHost上进行(备用writeHost不参加了),在集群中没有配置ReadHost的情况下,读都到第
一个writeHost完成
writeType:控制当前datahost维护的数据库集群的写操作
0:所有的写操作都在第一个writeHost标签的数据库进行
1:所有的写操作,都随机分配到所有的writeHost(mycat1.5完全不建议配置了)
dbtype:数据库类型(不同数据库配置不同名称,mysql)
dbDriver:数据库驱动,native,动态获取
switchType:切换的逻辑
-1:故障不切换
1:故障切换,当前写操作的writeHost故障,进行切换,切换到下一个writeHost;
slaveThreshold:标签中的<heartbeat>用来检测后端数据库的心跳sql语句;本属性检查从节点与主节点的同步情况(延迟时间数),配合心
跳语句show slave status; 读写分离时,所有的readHost的数据都可靠
-->
<dataHost name="host109" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select 1</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.8.109:3306" user="root" password="111111">
</writeHost>
</dataHost>
</mycat:schema>
2.1 <schema> 节点配置的是逻辑库,可以配置多个。
属性值:
checkSQLschema 当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;**则 MyCat 会把语句修改为**select * from travelrecord;**。即把表示 schema 的字符去掉,避免发送到后端数据库执行时报**(ERROR1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。 **不过,即使设置该值为 true ,如果语句所带的是并非是 schema 指定的名字,例如: **select * from db1.travelrecord;** 那么 MyCat 并不会删除 db1 这个字段,如果没有定义该库的话则会报错,所以在提供 SQL语句的最好是不带这个字段 。
sqlMaxLimit 当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句, MyCat 也会自动的加上所对应的值。例如设置值为 100,执行**select * from TESTDB.travelrecord;**的效果为和执行**select * from TESTDB.travelrecord limit 100;**相同。
2.2 <schema> 下面的 <table> 配置的是逻辑库下有什么表。其中 dataNode="dn1,dn2" 表示这个表的数据会存放在 dn1 和 dn2 上。rule 属性用的是 rule.xml 中的某个值。上面配置了“auto-sharding-long”, 看一下这个在 rule.xml 中的定义:
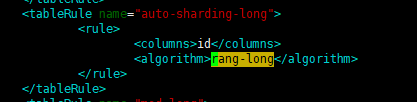
它又依赖了一个 "rang-long" 的算法。这个算法是根据 autopartition-long.txt 中的定义来决定数据存在哪个 mysql 里。

2.3 <dataNode> 节点中的 dataHost 属性为后面某个 <dataHost> 中的 name 属性的值。
2.4 <dataHost> 指明了真实的 mysql 的物理库的地址
假设 mycat 服务部署在 192.168.8.188 上面,那么通过上面的配置,我们可以通过 jdbc:mysql://192.168.8.188:8066/TESTDB 用户/密码: root/123456 (server.xml 中 <user> 的配置) 去连接 mycat,把它看作是一个 mysql 的数据源了。通过 navicat 去连接的话,可以看到类似下面的效果。 TESTDB 里会有一个 student 的表(schema.xml 中 <table> 的配置),这个表的数据其实是根据 rule 的配置规则,存入到 192.168.8.108:3306 中的 stu108 数据库和 192.168.8.109:3306 中的 stu109 数据库。
3. rule.xml
这个文件中配置的是各种各样的规则,默认已经有挺多的了。这些规则用于 <table> 中 rule 属性。mycat 根据指定的规则把数据存入到实际的物理库中。这个文件基本不用改。注意:如果使用的是 mod-long 这个规则的话,需要更改 count 这个属性的值,数量需要同 schema.xml 中 配置的 <dataNode> 的数量一致。

mycat 配置简介的更多相关文章
- SpringBoot常用配置简介
SpringBoot常用配置简介 1. SpringBoot中几个常用的配置的简单介绍 一个简单的Spring.factories # Bootstrap components org.springf ...
- Configuration所有配置简介
// 内存缓存的设置选项 (最大图片宽度,最大图片高度) 默认当前屏幕分辨率 // .memoryCacheExtraOptions(480, 800) // 硬盘缓存的 ...
- MyCat 入门:漫谈 MyCat 配置系统
文章首发于[博客园-陈树义],点击跳转到原文<MyCat 入门:漫谈 MyCat 配置系统> 上篇文章<MyCat 启蒙:分布式系统的数据库架构演变>中,我们通过一个项目从零到 ...
- MyCat配置详解
MyCAT 配置解析 server.xml Mycat的配置文件,设置账号.参数等schema.xml Mycat对应的物理数据库和数据库表的配置rule.xml Mycat分片(分库分表)规则 一 ...
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- Django中的路由配置简介
Django中的路由配置简介 路由配置(URLconf)就是Django所支撑网站的目录.其实,我们利用路由交换中的"寻址"的概念去理解Django的路由控制会简单很多,它的本质就 ...
- mycat配置实现mysql读写分离
需要先把mysql的主从复制配置好,然后才可以开始mycat的配置 m ysql主从复制配置:https://www.cnblogs.com/renjianjun/p/9093062.html myc ...
- Mycat 配置及优化【转】
前言 Mycat 是一个数据库分库分表中间件 MyCAT 是作为通用代理设计的,后端是以 Mysql协议 和 JDBC 的方式连接数据库,可以支持 Oracle.DB2.SQL Server . mo ...
- 转: ZigBee/Z-Stack CC2530实现低功耗运行的配置简介
转: ZigBee/Z-Stack CC2530实现低功耗运行的配置简介http://bbs.elecfans.com/jishu_914377_1_1.html(出处: 中国电子技术论坛) 设备支持 ...
随机推荐
- P-残缺的棋盘
Input 输入包含不超过10000 组数据.每组数据包含6个整数r1, c1, r2, c2, r3, c3 (1<=r1, c1, r2, c2, r3, c3<=8). 三个格子A, ...
- django -----原生SQL语句查询与前端数据传递?
view.py中 import MySQL def request_data(request): if request.method == "GET": conn = MySQLd ...
- vue解决开发时候跨域问题
vue项目/config/index.js 找到dev对象,增加如下代码 proxyTable: { '/api': { target: 'http://192.168.1.208:8888', ch ...
- 使用阿里ARouter路由实现组件化(模块化)开发流程
Android平台中对页面.服务提供路由功能的中间件,我的目标是 —— 简单且够用. 这是阿里对Arouter的定位,那么我们一起来梳理一下Arouter使用流程,和使用中我所遇到的一些问题! 先来看 ...
- 新建maven子模块 出现 Unable to read parent POM
新建maven子模块 出现 Unable to read parent POM错误 于是把pom.xml文件中的 中文字符全部删除 包括 注释 最后成功建立
- java封装小实例
封装是java语言的一个重要的特性,通过把对象的属性和操作方法封装在同一个类中,对外只提供公共方法对这些数据进行set和get,同时封装也能对方法进行封装.总之封装能够有效地隐藏内部的代码细节,从而使 ...
- ubuntu安装软件失败
Unable to fetch some archives, maybe run apt-get update or try with --fix-missing sudo gedit /etc/ho ...
- macos升级Nodejs和Npm到最新版
第一步,先查看本机node.js版本: node -v 第二步,清除node.js的cache: sudo npm cache clean -f 第三步,安装 n 工具,这个工具是专门用来管理node ...
- maven 依赖显示红线 pom文件不显示红线的一种可能问题
pom文件引用的是CDH的jar包 而没有配置CDH的仓库 导致maven找不到资源 ,依赖显示红色波浪,并且在仓库内生成了一堆.lastupdate文件 解决: 1. 删除本地仓库内所有的.las ...
- wpf socket 简单通讯示例
源码下载地址:https://github.com/lizhiqiang0204/WPF-Socket 效果如下: