Redis哨兵机制(sentinel)
1、简介:
1、是什么:
Redis-Sentinel是Redis官方推荐的高可用(HA)方案,当用Reids 做master-slave高可用方案时,假如master宕机了,redis本身(包括它的很多客服端)都没有实现自动的主备切换,而Redis-Sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能自动切换。
2、功能
- 不时监控redis是否按照预期的良好的运行。
- 如果发现某个redis节点运行出现状况,能够通知别外一个进程(如它的客户端)。
- 能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果超过一个slave的话)中的一个来作为新的master,其它的slave节点会将他的master地址改为新提升为master的服务器的地址。
4、优缺点:
优点:
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都有。
- 主从可以自动切换,系统更健壮,可用性更高
缺点:
- redis较难支持在线扩容,在集群容量达上限时在线扩容变的很复杂。
2、原理:
1、哨兵的工作方式:
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个redis集群中的master主服务器、slave从服务器以及其他的Sentinel(哨兵)进程发送一个ping命令。
- 如果一个实例距离最后一次有效回复ping命令的时间超过down-after-milliseconds选项所指定的值则这个实例会被Sentinel标记为主观下线(SDOWN)。
- 如是是master主服务器被标记为SDOWN,则正在监控这个服务器的所有Sentinel都要以每秒一次的频率确认服务器是否真的已经进入SDOWN(主观下线状态)。
- 当有足够数量(≥配置文件配置值)的Sentinel在指定的时间内确认了master进入了SDOWN状态,则master被标记为ODOWN(客观下线状态)。
- 在一般情况下,每个Sentinel会每10秒向redis 主服务器和从服务器发送Info命令。但是当master被标记为客观下线时,频率改为1秒一次。
- 若没有足够数量的Sentinel同意master服务器下线,则master的SDOWN状态被移除,若master重新向Sentinel发送ping命令返回了有效回复,则master的SDOWN状态被移除。
2、原理
- Sentinel集群通过给定的配置文件发现master,启动时会监控master。通过向master发送info信息获得该服务下面的所有从服务器。
- Sentinel集群通过命令连接向被监控的主从服务器发送hello信息(每秒一次),该信息包括Sentinel本身的ip、端口、id等内容,以此来向其他Sentinel宣告自己的存在。
- Sentinel集群通过订阅连接接收其他Sentinel发送的hello信息,以此来发现监视同一个主服务器的其他Sentinel;集群之间会互相创建命令连接用于通信,因为已经有主从服务器作为发送和接收hello信息的中介,Sentinel之间不会创建订阅连接。
- Sentinel集群使用Sentinel命令来检测实例的状态,如果指定的时间内(down-after-milliseconds)没有回复或者返回错误回复,那么该实例被判为主观下线SDOWN。
- 当failover主备切换被触发后,failover并不会马上进行,还需要Sentinel集群中另外quorum个其他Sentinel授权,成功后进入ODOWN客观下线状态,之后再进行failover。
- Sentinel向选为master的slave发送slaveof no one 命令,选择slave的条件是首先会根据slave的优先级来排序,优先级越小排名越靠前。如果相同,则查看复制的下标,哪个接收master的复制数据越多哪个越靠前,如果两个都一样就选择进程ID较小的。
- Sentinel被授权后会获得宕机的master的一份最新配置版本号(config-epoch)当failover结束后,这个版本号将会用于最新的配置,通过广播的形式通知其他Sentinel,其它的Sentinel则更新对应的master配置。
1-3是自动发现机制
- 以10秒一次的频率,向被监控的master发送Info命令,根据回复获取当前master信息。
- 以1秒一次的频率,向所有的redis服务器包括 Sentinel 发送ping命令,通过回复判断服务器是否在线
- 以2秒一次的频率,通过 向所有被监控的master,slave服务器发送的当前Sentinel,master信息的消息。
4、是检测机制,5、6是failover机制,7是更新配置机制。
注意:
- 因为redis采用的是异步复制,没有办法避免数据的丢失。但可以通过以下配置来使得数据不会丢失:min-slaves-to-write 1 ; min-slaves-max-lag 10。
- 一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。
- 要注意到master也是有可能通过failover变成slave的。
- 如果一个redis的slave优先级配置为0,那么它将永远不会被选为master,但是它依然会从master哪里复制数据。
3、SDOWN和ODOWN
- sentinel对于不可用有两种不同的看法,一个叫主观不可用(SDOWN),另外一个叫客观不可用(ODOWN)。
- SDOWN是sentinel自己主观上检测到的关于master的状态,ODOWN需要一定数量的sentinel达成一致意见才能认为一个master客观上已经宕掉,各个sentinel之间通过命令
SENTINEL is_master_down_by_addr来获得其它sentinel对master的检测结果。- 从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDOWN的条件。这个时间在配置中通过
is-master-down-after-milliseconds参数配置。- 从SDOWN切换到ODOWN不需要任何一致性算法,只需要一个gossip协议:如果一个sentinel收到了足够多的sentinel发来消息告诉它某个master已经down掉了,SDOWN状态就会变成ODOWN状态。如果之后master可用了,这个状态就会相应地被清理掉。
- 真正进行failover需要一个授权的过程,但是所有的failover都开始于一个ODOWN状态。
- ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
4、配置版本号
- 为什么要先获得大多数sentinel的认可时才能真正去执行failover呢?
- 当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
- 而且,sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过
failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。- redis sentinel保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
redis sentinel也保证了安全性:每个试图去failover同一个master的sentinel都会得到一个独一无二的版本号。5、配置传播
- 一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
- 一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送
SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。- 当将一个slave选举为master并发送
SLAVEOF NO ONE后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的,然后所有sentinels将会发布新的配置信息。新配在集群中相互传播的方式,就是为什么我们需要当一个sentinel进行failover时必须被授权一个版本号的原因。
- 每个sentinel使用##发布/订阅##的方式持续地传播master的配置版本信息,配置传播的##发布/订阅##管道是:
__sentinel__:hello。- 因为每一个配置都有一个版本号,所以以版本号最大的那个为标准。
举个栗子:
- 假设有一个名为mymaster的地址为192.168.1.50:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。
- 一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。
- 如果failover成功了,假设地址改为了192.168.1.50:9000,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel
- 由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
这意味着sentinel集群保证了第二种活跃性:一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
6、Sentinel之间和Slaves之间的自动发现机制
- 虽然sentinel集群中各个sentinel都互相连接彼此来检查对方的可用性以及互相发送消息。但是你不用在任何一个sentinel配置任何其它的sentinel的节点。因为sentinel利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点。通过向名为
__sentinel__:hello的管道中发送消息来实现。- 同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
- 每个sentinel通过向每个master和slave的发布/订阅频道
__sentinel__:hello每秒发送一次消息,来宣布它的存在。- 每个sentinel也订阅了每个master和slave的频道
__sentinel__:hello的内容,来发现未知的sentinel,当检测到了新的sentinel,则将其加入到自身维护的master监控列表中。- 每个sentinel发送的消息中也包含了其当前维护的最新的master配置。如果某个sentinel发现自己的配置版本低于接收到的配置版本,则会用新的配置更新自己的master配置。
- 在为一个master添加一个新的sentinel前,sentinel总是检查是否已经有sentinel与新的sentinel的进程号或者是地址是一样的。如果是那样,这个sentinel将会被删除,而把新的sentinel添加上去。
7、网络隔离时的一致性
例子:
- 有三个主机,每个主机分别运行一个redis和一个sentinel。初始状态下redis3是master, redis1和redis2是slave。
- 之后redis3所在的主机网络不可用了,sentinel1和sentinel2启动了failover并把redis1选举为master。
- Sentinel集群的特性保证了sentinel1和sentinel2得到了关于master的最新配置。但是sentinel3依然是旧的配置,因为它与外界隔离了。
当网络恢复以后,我们知道sentinel3将会更新它的配置。但是,如果客户端所连接的master被网络隔离,会发生什么呢?
- 客户端将依然可以向redis3写数据,但是当网络恢复后,redis3就会变成redis的一个slave,那么,在网络隔离期间,客户端向redis3写的数据将会丢失。
- 因为redis采用的是异步复制,在这样的场景下,没有办法避免数据的丢失。然而,你可以通过以下配置来配置redis3和redis1,使得数据不会丢失。
min-slaves-to-write 1
min-slaves-max-lag 10
- 通过上面的配置,当一个redis是master时,如果它不能向至少一个slave写数据(上面的min-slaves-to-write指定了slave的数量),它将会拒绝接受客户端的写请求。
- 由于复制是异步的,master无法向slave写数据意味着slave要么断开连接了,要么不在指定时间内向master发送同步数据的请求了(上面的min-slaves-max-lag指定了这个时间)。
8、Slave选举与优先级
当一个sentinel准备好了要进行failover,并且收到了其他sentinel的授权,那么就需要选举出一个合适的slave来做为新的master。
slave的选举主要会评估slave的以下几个方面:
与master断开连接的次数
Slave的优先级
数据复制的下标(用来评估slave当前拥有多少master的数据)
进程ID
如果一个slave与master失去联系超过10次,并且每次都超过了配置的最大失联时间(
down-after-milliseconds),如果sentinel在进行failover时发现slave失联,那么这个slave就会被sentinel认为不适合用来做新master的。更严格的定义是,如果一个slave持续断开连接的时间超过
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state就会被认为失去选举资格。
符合上述条件的slave才会被列入master候选人列表,并根据以下顺序来进行排序:
sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。
如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。
如果优先级和下标都相同,就选择进程ID较小的那个。
一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。要注意到master也是有可能通过failover变成slave的。
如果一个redis的slave优先级配置为0,那么它将永远不会被选为master。但是它依然会从master哪里复制数据。
3、配置
1、redis.conf 配置
################################# REPLICATION #################################
#复制选项,slave复制对应的master。
# slaveof <masterip> <masterport> #如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。
# masterauth <master-password> #当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
slave-serve-stale-data yes #作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)。
slave-read-only yes #是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。
repl-diskless-sync no #diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。所以最好等待一段时间,等更多的slave连上来。
repl-diskless-sync-delay 5 #slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
# repl-ping-slave-period 10 #复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
# repl-timeout 60 #是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。默认是no,即使用tcp nodelay。如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。但是这也可能带来数据的延迟。默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no #复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m。
# repl-backlog-size 5mb #master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
# repl-backlog-ttl 3600 #当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。而配置成0,永远不会被选举。
slave-priority 100 #redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能。
# min-slaves-to-write 3 #延迟小于min-slaves-max-lag秒的slave才认为是健康的slave。
# min-slaves-max-lag 102、sentinel.conf配置
port 20086 #默认端口26379 dir "/tmp" logfile "/var/log/redis/sentinel_20086.log" daemonize yes #格式:sentinel <option_name> <master_name> <option_value>;#该行的意思是:监控的master的名字叫做T1(自定义),地址为127.0.0.1:10086,行尾最后的一个2代表在sentinel集群中,多少个sentinel认为masters死了,才能真正认为该master不可用了。
sentinel monitor T1 127.0.0.1 10086 2 #sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒,默认30秒。
sentinel down-after-milliseconds T1 15000 #failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。默认180秒,即3分钟。
sentinel failover-timeout T1 120000 #在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
sentinel parallel-syncs T1 1 #sentinel 连接设置了密码的主和从
#sentinel auth-pass <master_name> xxxxx #发生切换之后执行的一个自定义脚本:如发邮件、vip切换等
##sentinel notification-script <master-name> <script-path> ##不会执行,疑问?
#sentinel client-reconfig-script <master-name> <script-path> ##这个会执行例子:
port 20086 dir "/var/lib/sentinel_20086" logfile "/var/log/redis/sentinel_20086.log" daemonize yes sentinel monitor T1 127.0.0.1 10086 2 sentinel down-after-milliseconds T1 15000 sentinel failover-timeout T1 120000 sentinel parallel-syncs T1 1 #发生切换之后执行的一个自定义脚本:如发邮件、vip切换等
#sentinel notification-script <master-name> <script-path>主要配置sentinel monitor 主服务器的地址,其他配置按需要调整。
可添加 logfile 路径作为 sentinel 的日志文件。
关键配置:sentinel monitor T1 127.0.0.1 10086 2
3、启动命令
redis-sentinel sentinel.conf 注意:当一个master配置为需要密码才能连接时,客户端和slave在连接时都需要提供密码。master通过requirepass设置自身的密码,不提供密码无法连接到这个master。slave通过masterauth来设置访问master时的密码。客户端需要auth提供密码,但是当使用了sentinel时,
由于一个master可能会变成一个slave,一个slave也可能会变成master,所以需要同时设置上述两个配置项,并且sentinel需要连接master和slave,需要设置参数:sentinel auth-pass <master_name> xxxxx。
4、验证
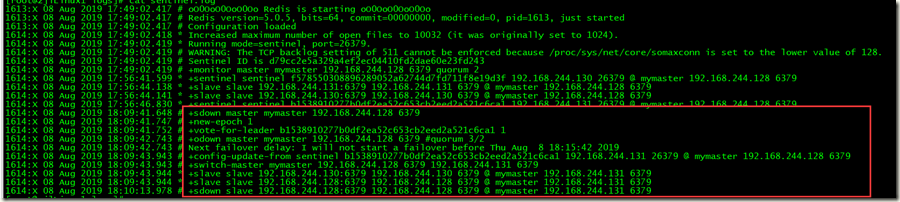
1、分别查看sentinel日志可看到如下记录
可看到+monitor master mymaster 192.168.244.128 6379 quorum 2
+sentinel sentinel f578550308896289052a62744d7fd711f8e19d3f 192.168.244.130 26379 @ mymaster 192.168.244.128 6379
+sentinel sentinel b1538910277b0df2ea52c653cb2eed2a521c6ca1 192.168.244.131 26379 @ mymaster 192.168.244.128 6379
如下说明sentinel集群启动成功
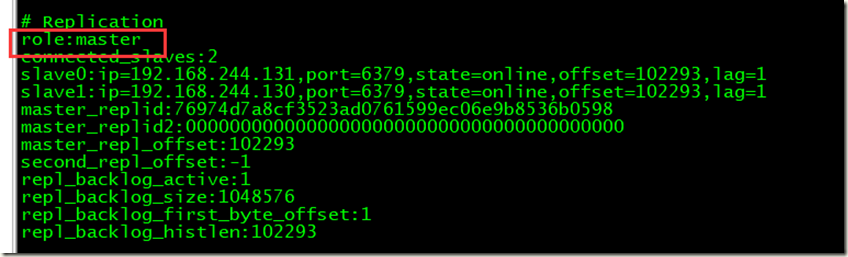
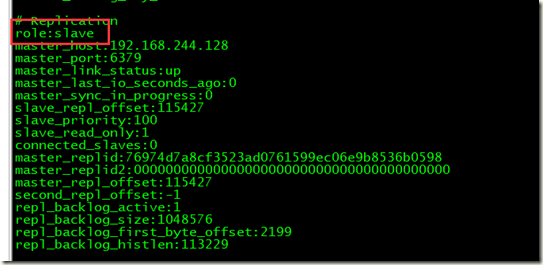
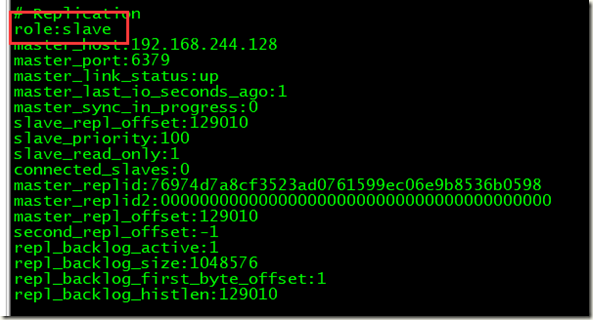
2、服务器info 命令查看信息
192.168.244.128
192.168.244.130
192.168.244.131
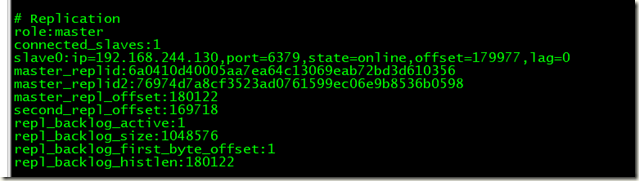
3、关闭主redis info命令查看
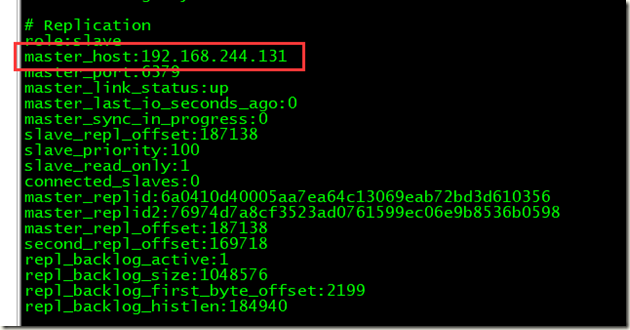
192.168.244.131 已经成为主服务器
192.168.244.130 已经成为131 的从服务器
4、可以查看主服务器停掉之后sentinel的日志是如何切换主备的
5、重新启动后的主服务器变成了从服务器


整理自:https://www.cnblogs.com/zhoujinyi/p/5570024.html
https://www.cnblogs.com/zhoujinyi/p/5569462.html
Redis哨兵机制(sentinel)的更多相关文章
- redis 哨兵机制环境搭建
Redis哨兵机制,一主二从 注:Redis哨兵切换,建议一主多从 一.一主二从 教程步骤:https://www.cnblogs.com/zwcry/p/9046207.html 二.哨兵配置(se ...
- 关于Redis哨兵机制,7张图详解!
写在前面 之前有位朋友去面试被问到Redis哨兵机制,这道题其实很多小伙伴都应该有被问到过!本文将跟大家一起来探讨如何回答这个问题!同时用XMind画了一张导图记录Redis的学习笔记和一些面试解析( ...
- Redis哨兵机制的实现及与SpringBoot的整合
1. 概述 前面我们聊过Redis的读写分离机制,这个机制有个致命的弱点,就是主节点(Master)是个单点,如果主节点宕掉,整个Redis的写操作就无法进行服务了. 为了解决这个问题,就需要依靠&q ...
- Redis哨兵(Sentinel)模式
Redis哨兵(Sentinel)模式 主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用.这不是一种推荐的方式 ...
- redis哨兵机制--配置文件sentinel.conf详解
转载自 https://blog.csdn.net/u012441222/article/details/80751390 Redis的哨兵机制是官方推荐的一种高可用(HA)方案,我们在使用Redis ...
- Redis之哨兵机制(sentinel)——配置详解及原理介绍
说到Redis不得不提哨兵模式,那么究竟哨兵是什么意思?为什么要使用哨兵呢? 接下来一一为您讲解: 1.为什么要用到哨兵 哨兵(Sentinel)主要是为了解决在主从(master-slave)复制架 ...
- redis哨兵机制讲解
原文链接:https://blog.csdn.net/yswKnight/article/details/78158540 一.什么是哨兵机制? 答:Redis的哨兵(sentinel) 系统用于管理 ...
- contos7下安装redis&redis的主从复制的配置&redis 哨兵(sentinel)
一.centos7下安装redis 1.解压 redis-5.0.5.tar.gz 压缩文件 解压命令为: .tar.gz -C redis 解压后进入 redis 工作目录,进入 redis-5.0 ...
- Redis哨兵机制原理
1.概述 Redis Sentinel是一个分布式系统,为Redis提供高可用性解决方案.可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip p ...
随机推荐
- 在Python中处理大型文件的最快方法
我们需要处理的各种目录中有大约500GB的图像.每个图像的大小约为4MB,我们有一个python脚本,一次处理一个图像(它读取元数据并将其存储在数据库中).每个目录可能需要1-4小时才能处理,具体取决 ...
- spring-data-neo4j了解
本项目demo地址[请阅读readme文件]: https://gitee.com/LiuDaiHua/project-neo4j 最近项目上要搭建一个关系图谱的东西,领导给了neo4j和d3两个概念 ...
- 修改默认runlevel
CentOS直接修改文件 /etc/inittab 就好了 # Default runlevel. The runlevels used are: # - halt (Do NOT set init ...
- sub
Popen.communicate(input=None)¶Interact with process: Send data to stdin. Read data from stdout and s ...
- 七、Null、空以及0的区别
一.Null的区别 create database scort use scort create table emp ( empno int primary key, ename ), sal int ...
- Node.js require 方法
Node.js 中存在 4 类模块(原生模块和3种文件模块),尽管 require 方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同
- 小程序内嵌H5页面判断微信及小程序环境
判断微信及小程序环境 1.H5页面引入jweixin-1.3.2.js 2. var ua = window.navigator.userAgent.toLowerCase(); if(ua.matc ...
- js学习笔记-日期对象
<body> <script> var d = new Date() console.log(d) var arr = ['星期日', '星期一', '星期二', '星期三', ...
- Mybatis基于SqlSession实现CRUD
之前我们讲的基于XML还是接口注解配置都是使用接口实现CRUD,本文我们将要讲解通过splsession来实现CRUD,这种方法比较灵活. 基本配置 <!-- spring和MyBatis完美整 ...
- vue2 打包部署(vue-cli )
1.一般打包 :直接 npm run build.(webpack的文件,根据不同的命令,执行不同的代码的) 注:这种打包的静态文件,只能放在web服务器中的根目录下才能运行. 2.在服务器中 非根目 ...