solr 安装与配置
1. Solr安装与配置
1.1什么是Solr
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr是一个流行的开源搜索服务器,它通过使用类似REST的HTTP API,这就确保你能从几乎任何编程语言来使用solr。
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 使用Solr构建的应用程序非常复杂,可提供高性能。
为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。并于2016年发布最新版本Solr 6.0,支持并行SQL查询的执行。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
1.2 Solr安装
1:安装 Tomcat,解压缩即可。
2:解压 solr。
3:把 solr 下的dist目录solr-4.10.3.war部署到 Tomcat\webapps下(去掉版本号)。
4:启动 Tomcat解压缩 war 包
5:把solr下example/lib/ext 目录下的所有的 jar 包,添加到 solr 的工程中(\WEB-INF\lib目录下)。
6:创建一个 solrhome 。solr 下的/example/solr 目录就是一个 solrhome。复制此目录到D盘改名为solrhome
7:关联 solr 及 solrhome。需要修改 solr 工程的 web.xml 文件。
|
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>d:\solrhome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> |
8:启动 Tomcat
http://IP:8080/solr/
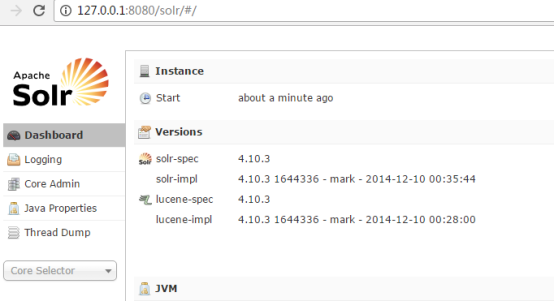
1.3中文分析器IK Analyzer
1.3.1 IK Analyzer简介
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
1.3.2 IK Analyzer配置
步骤:
1、把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
2、创建WEB-INF/classes文件夹 把停用词词典stopword.dic、配置文件IKAnalyzer.cfg.xml放到 solr 工程的 WEB-INF/classes 目录下。
3、修改 Solrhome 的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
|
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
1.4配置域
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性:
· name:指定域的名称
· type:指定域的类型
· indexed:是否索引
· stored:是否存储
· required:是否必须
· multiValued:是否多值
1.4.1域
修改solrhome的schema.xml 文件 设置业务系统 Field
|
<field name="item_goodsid" type="long" indexed="true" stored="true"/> <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="double" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category" type="string" indexed="true" stored="true" /> <field name="item_seller" type="text_ik" indexed="true" stored="true" /> <field name="item_brand" type="string" indexed="true" stored="true" /> |
1.4.2复制域
复制域的作用在于将某一个Field中的数据复制到另一个域中
|
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_category" dest="item_keywords"/> <copyField source="item_seller" dest="item_keywords"/> <copyField source="item_brand" dest="item_keywords"/> |
1.4.3动态域
当我们需要动态扩充字段时,我们需要使用动态域。对于优乐选,规格的值是不确定的,所以我们需要使用动态域来实现。需要实现的效果如下:
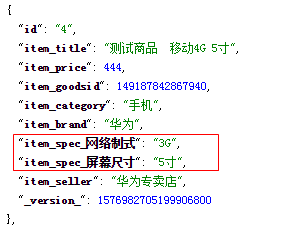
配置:
|
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" /> |
1. Solr安装与配置
1.1什么是Solr
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr是一个流行的开源搜索服务器,它通过使用类似REST的HTTP API,这就确保你能从几乎任何编程语言来使用solr。
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 使用Solr构建的应用程序非常复杂,可提供高性能。
为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。并于2016年发布最新版本Solr 6.0,支持并行SQL查询的执行。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
1.2 Solr安装
1:安装 Tomcat,解压缩即可。
2:解压 solr。
3:把 solr 下的dist目录solr-4.10.3.war部署到 Tomcat\webapps下(去掉版本号)。
4:启动 Tomcat解压缩 war 包
5:把solr下example/lib/ext 目录下的所有的 jar 包,添加到 solr 的工程中(\WEB-INF\lib目录下)。
6:创建一个 solrhome 。solr 下的/example/solr 目录就是一个 solrhome。复制此目录到D盘改名为solrhome
7:关联 solr 及 solrhome。需要修改 solr 工程的 web.xml 文件。
|
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>d:\solrhome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> |
8:启动 Tomcat
http://IP:8080/solr/

1.3中文分析器IK Analyzer
1.3.1 IK Analyzer简介
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
1.3.2 IK Analyzer配置
步骤:
1、把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
2、创建WEB-INF/classes文件夹 把停用词词典stopword.dic、配置文件IKAnalyzer.cfg.xml放到 solr 工程的 WEB-INF/classes 目录下。
3、修改 Solrhome 的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
|
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
1.4配置域
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性:
· name:指定域的名称
· type:指定域的类型
· indexed:是否索引
· stored:是否存储
· required:是否必须
· multiValued:是否多值
1.4.1域
修改solrhome的schema.xml 文件 设置业务系统 Field
|
<field name="item_goodsid" type="long" indexed="true" stored="true"/> <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="double" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category" type="string" indexed="true" stored="true" /> <field name="item_seller" type="text_ik" indexed="true" stored="true" /> <field name="item_brand" type="string" indexed="true" stored="true" /> |
1.4.2复制域
复制域的作用在于将某一个Field中的数据复制到另一个域中
|
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_category" dest="item_keywords"/> <copyField source="item_seller" dest="item_keywords"/> <copyField source="item_brand" dest="item_keywords"/> |
1.4.3动态域
当我们需要动态扩充字段时,我们需要使用动态域。对于优乐选,规格的值是不确定的,所以我们需要使用动态域来实现。需要实现的效果如下:

配置:
|
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" /> |

solr 安装与配置的更多相关文章
- 1.Solr安装与配置
1.Solr安装 1:安装 Tomcat,解压缩即可. 2:解压 solr. 3:把 solr 下的dist目录solr-4.10.3.war部署到 Tomcat\webapps下(去掉版本号). 4 ...
- 02——Solr学习之Solr安装与配置(linux上的安装)
借鉴博客:https://www.jianshu.com/p/1100f54fcbd8 https://www.cnblogs.com/jepson6669/p/9134652.html 1.准备一个 ...
- Solr(5.1.0) 与Tomcat 从0开始安装与配置
1.什么是Solr? Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置 ...
- JAVAEE——Solr:安装及配置、后台管理索引库、 使用SolrJ管理索引库、仿京东的电商搜索案例实现
1 学习回顾 1. Lucene 是Apache开源的全文检索的工具包 创建索引 查询索引 2. 遇到问题? 文件名 及文件内容 顺序扫描法 全文检索 3. 什么是全文检索? 这种先创建索引 再 ...
- Solr6.5在Centos6上的安装与配置 (一)
这篇文章主要是介绍在Centos6上Solr6.5的安装与配置. 一.安装准备及各软件使用版本说明: 1.JDK8,版本jdk1.8.0_121下载地址:jdk-8u121-linux-x64.tar ...
- Solr安装步骤
一.Solr概述 1.什么是Solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr学习总结(二)Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
随机推荐
- FAT12
FAT12 is one of FAT file system families,mostly used on 1.44MB floppy disk. FAT 's full name is File ...
- 开发框架DevExtreme全新发布v19.1.3|附下载
DevExtreme Complete Subscription是性能最优的 HTML5,CSS 和 JavaScript 移动.Web开发框架,可以直接在Visual Studio集成开发环境,构建 ...
- 使用Spring.Net进行Webservice开发&发布遇到的问题
发布遇到的问题1: HTTP 错误 404.17 - Not Found 请求的内容似乎是脚本,因而将无法由静态文件处理程序来处理. 最终解决时IIS的设置情况: 1.应用程序池的高级设置中 启用32 ...
- visual studio 2017激活
VS2017专业版和企业版激活密钥 Enterprise: NJVYC-BMHX2-G77MM-4XJMR-6Q8QF Professional: KBJFW-NXHK6-W4WJM-CRMQB- ...
- 事物Spring boot @Transactional
事物:dr @Override @UDS(value="fq") @Transactional public BaseResultMessage testTransactional ...
- java 8 接口默认方法
解决问题:在java8 之前的版本,在修改已有的接口的时候,需要修改实现该接口的实现类. 作用:解决接口的修改与现有的实现不兼容的问题.在不影响原有实现类的结构下修改新的功能方法 案例: 首先定义一个 ...
- POJ 1742 Coins ( 经典多重部分和问题 && DP || 多重背包 )
题意 : 有 n 种面额的硬币,给出各种面额硬币的数量和和面额数,求最多能搭配出几种不超过 m 的金额? 分析 : 这题可用多重背包来解,但这里不讨论这种做法. 如果之前有接触过背包DP的可以自然想到 ...
- 20181022-JSP 开发环境搭建
JSP 开发环境搭建 JSP开发环境是您用来开发.测试和运行JSP程序的地方. 本节将会带您搭建JSP开发环境,具体包括以下几个步骤. 配置Java开发工具(JDK) 这一步涉及Java SDK的下载 ...
- 为什么Redis可以方便地实现分布式锁
1.Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系. 2.Redis的SETNX命令可以方便的实现分布式锁. setNX(SET if ...
- Retrotranslator使用简介(JDK1.5->1.4)
Retrotranslator是一个可以把JDK1.5(6)下编译的类(或包)转译成JDK1.4下可以识别的类(包)的工具. 为现在还用JDK1.4呢?我想无非是现在的大部分Java Web应用是 ...