celery源码解读
Celery启动的入口:
文件:Celery/bin/celery.py

看下main函数做了什么事
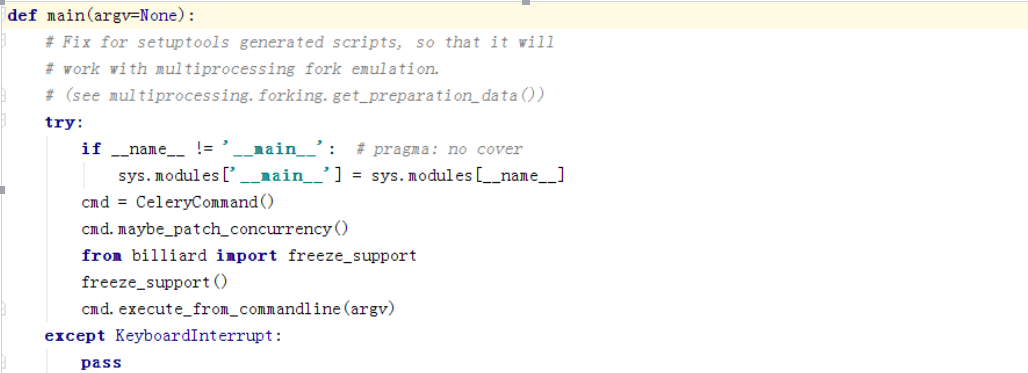
可以看到主要做了几个事根据-P参数判断是否需要打patch,如果是gevent或者eventlet则要打对应的补丁。
然后执行命令行逻辑
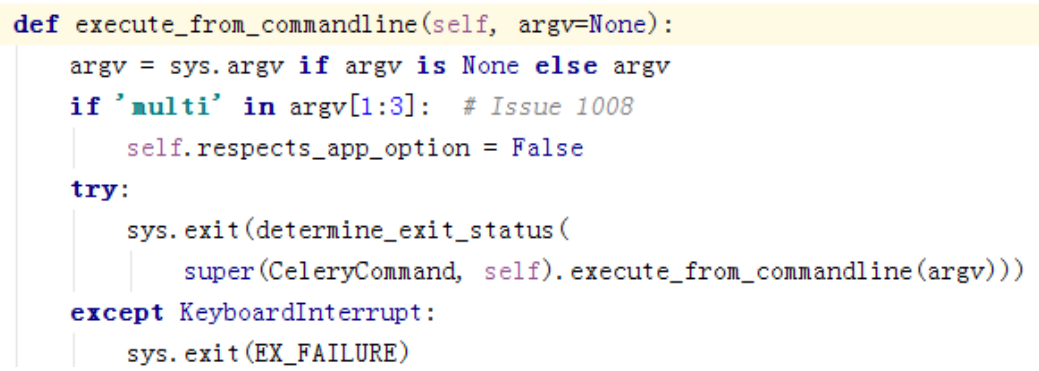
可以看到,这边取出系统参数

然后执行基类Command的execute_from_commandline,
文件:celery/bin/base.py

setup_app_from_commandline是核心函数,作用是获得我们的app对象和获得我们的配置参数

文件:Celery/bin/celery.py
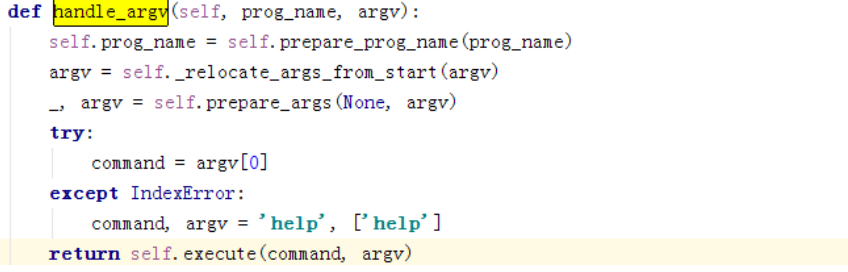
这边主要获取启动类别及启动参数,我们的类别是worker所以:
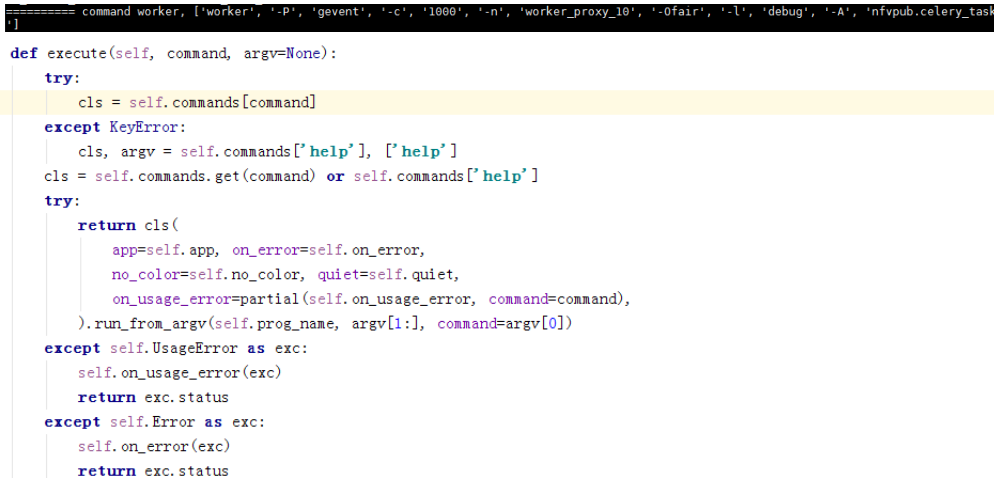
这边是开始准备启动对应类别的对象,worker、beat等。
self.commands是支持的命令:

上面我们知道,我们的类型是worker,即celery.bin.worker.worker,初始化该类,然后执行run_from_argv函数
文件:celery/bin/worker.py

最后一行会执行到父类的__call__函数,
文件:celery/bin/base.py

这边主要执行的是run函数
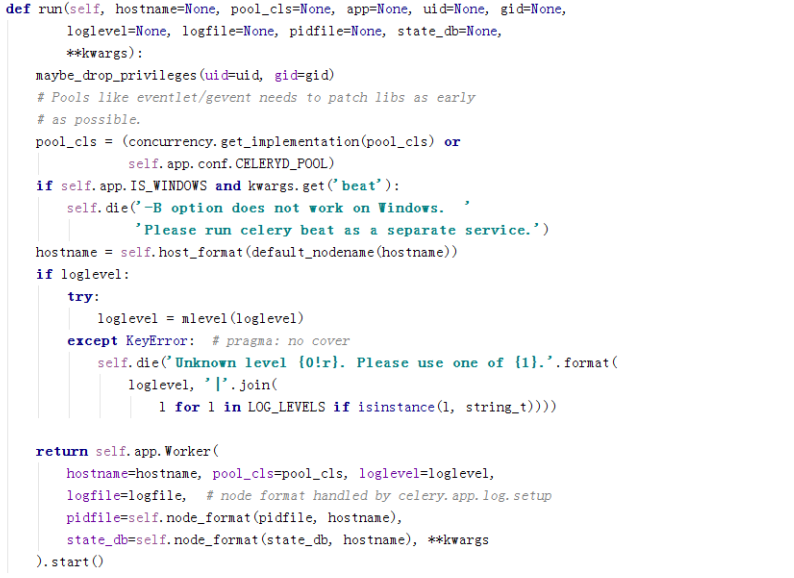
这个函数主要是启动worker

终于进入worker了,现在这里涉及一些比较关键的东西了,
文件:celery/worker/__init__.py
在WorkController类里,是worker的基类

这是worker的蓝图,这边会形成一个依赖图,是启动的必要组件,分别负责worker的一部分任务,比较重要的几个:
Timer:用于执行定时任务的 Timer,和 Consumer 那里的 timer 不同
Hub:Event loop 的封装对象
Pool:构造各种执行池(线程/进程/协程)的
Beat:创建Beat进程,不过是以子进程的形式运行(不同于命令行中以beat参数运行)
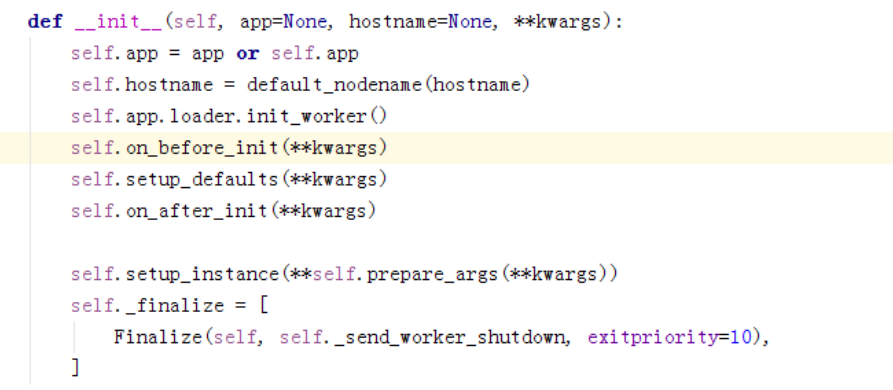
文件:celery/apps/worker.py

文件:celery/apps/trace.py
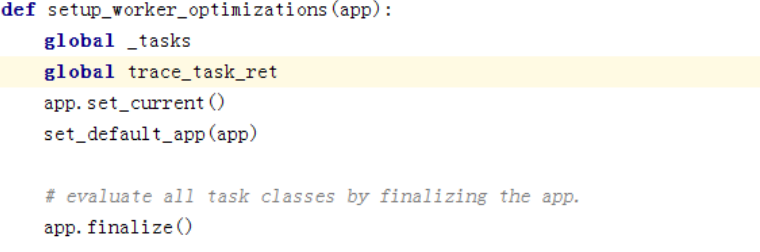
文件:celery/app/base.py
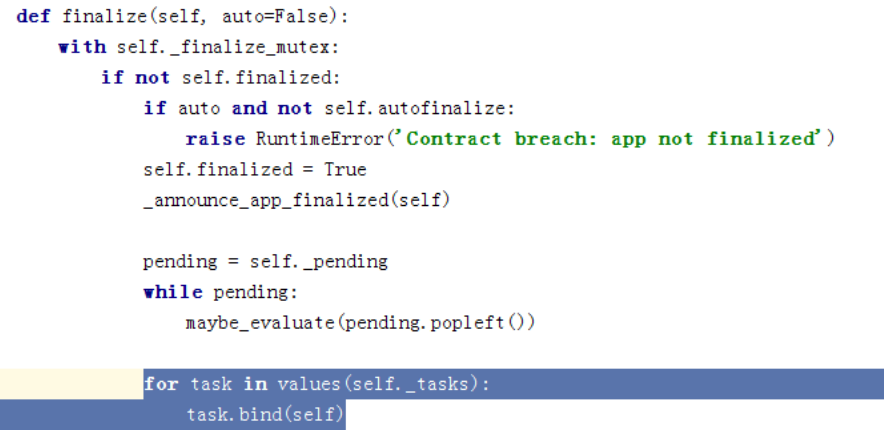
从init_before开始,这边是最主要的,即绑定所有的task到我们的app,注册task在下面

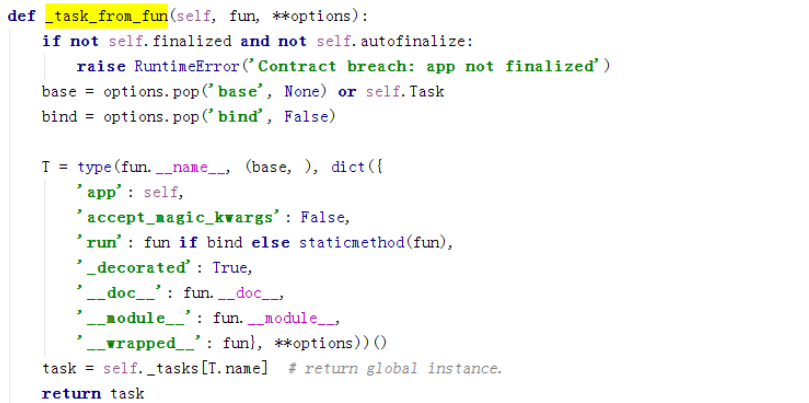
每个task都有delay和apply_async函数,这个可以用来帮我们启动任务。

文件:celery/worker/__init__.py


这边是设置关注及不关注的队列,可以看到,celery支持ampq协议。

调用setup_includes安装一些通过CELERY_INCLUDE配置的模块,保证所有的任务模块都导入了
最后初始化蓝图,并进行apply完成蓝图各个step的依赖关系图的构建,并进行各个组件的初始化,依赖在component中已经标出

这个requires就是依赖,说明hub依赖timer,上面蓝图声明的组件都有互相依赖关系。
回到文件:celery/worker/__init__.py执行start

执行的是蓝图的start。

分别执行各个步骤的start,在apply时,会判断step是否需要start,不start但是仍要create。
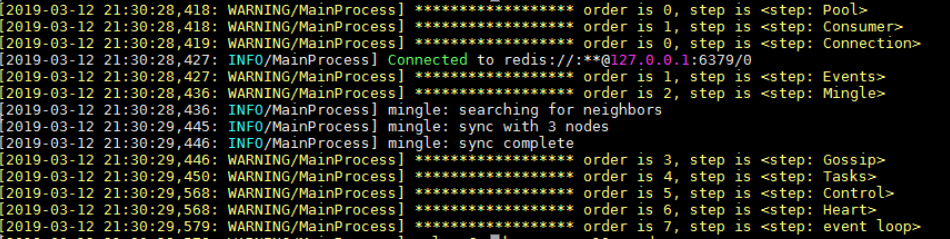
通过启动日志看,worker启动的step为Pool,和Consumer;
如果换成prefork方式起,worker会多起hub和autoscaler两个step:


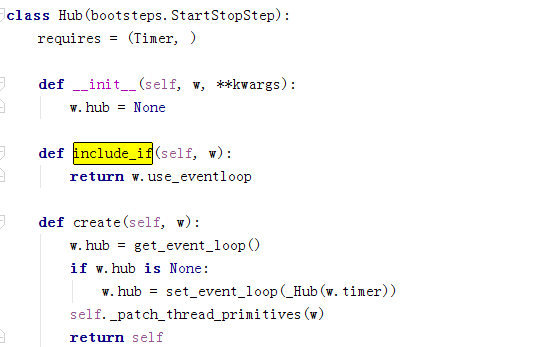
Hub依赖Timer,我们用gevent,所以include_if是false,这个不需要start。
Hub创建时候引用的kombu的Hub组件,Connection会注册到Hub,Connection是各种类型连接的封装,对外提供统一接口
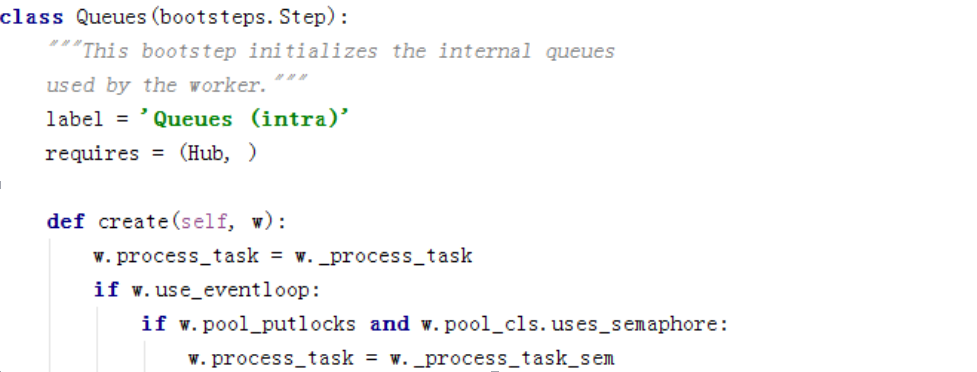
Queue依赖Hub,这边是基于Hub创建任务队列
下面是我们的worker启动的step其中的一个,重点进行说明

初始化线程/协程池,是否弹缩,最大和最小并发数

Celery支持的几种TaskPool,
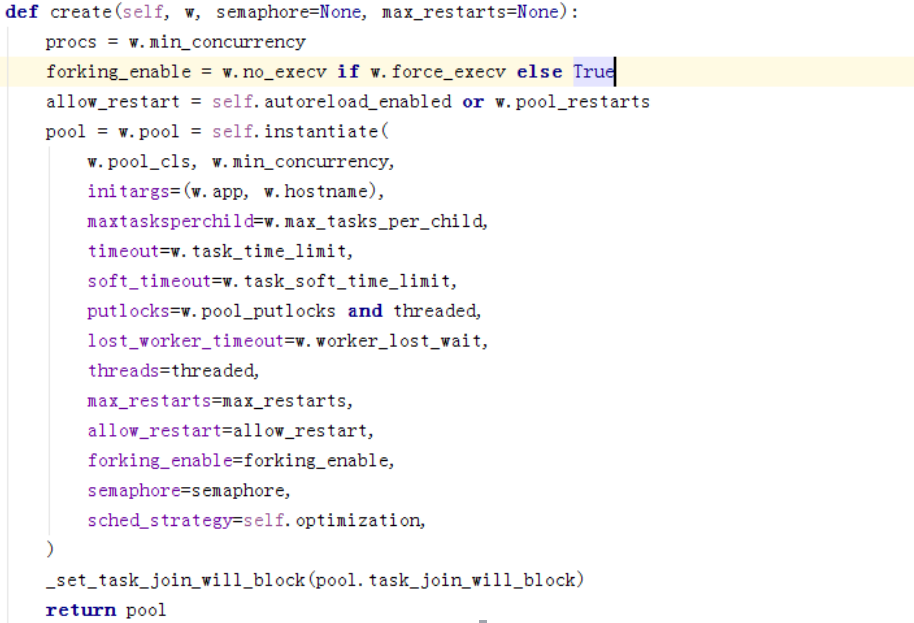
我们是gevent,所以这边直接找gevent的代码。

这边直接引用gevent的Pool

下面看worker启动的第二个step
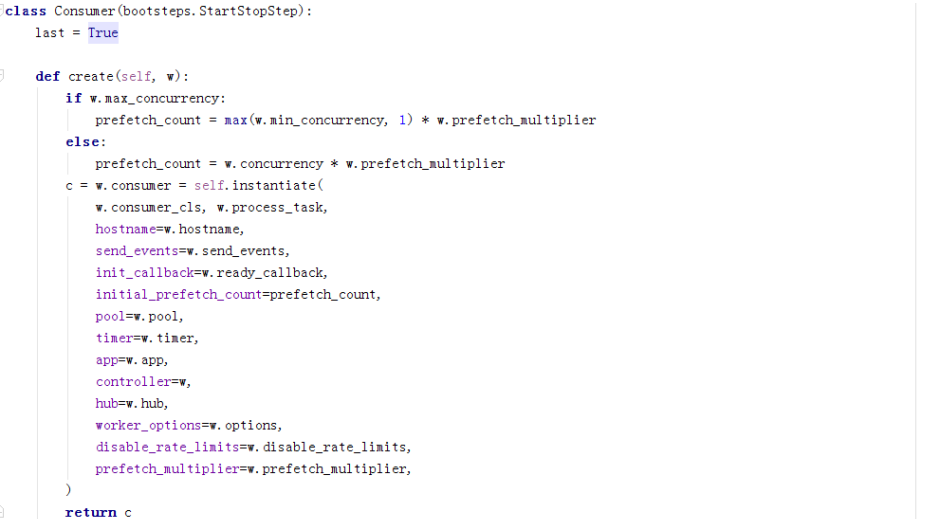

可以看到,这边启动的是celery.worker.consumer.Consumer,这边就会涉及另一个重要的蓝图了。
文件:celery/worker/consumer,Consumer类

这是Consumer的蓝图,
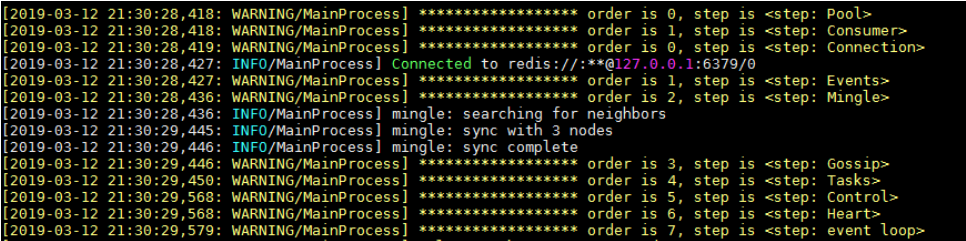
Consumer启动的step为Connection,events,mingle,Gossip,Tasks,Contorl,Heart和event loop。

__init__初始化一些必要的组件,很多都是之前worker创建的。
然后执行blueprint的apply,做的事我worker之前是一样的。

执行Consumer的start,也就是执行blueprint的start。
启动的step的基本功能:
Connection:管理和broker的Connection连接
Mingle:不同worker之间同步状态用的
Tasks:启动消息Consumer
Gossip:消费来自其他worker的事件
Heart:发送心跳事件(consumer的心跳)
Control:远程命令管理服务
其中Connection,Tasks,Heart和event loop是最重要的几个。
先看Connection。
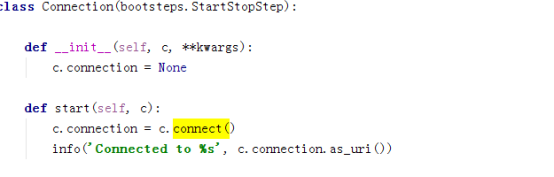
使用了consumer的connect()

Conn引用了ampq的connection,ampq的Connection是直接使用的kombu的Connection,上面说过,这个Connection是各种支持的类型(如redis,rabbitMQ等)的抽象,对外提供统一接口。
如果hub存在,会将连接注册到event loop。
再看Tasks:
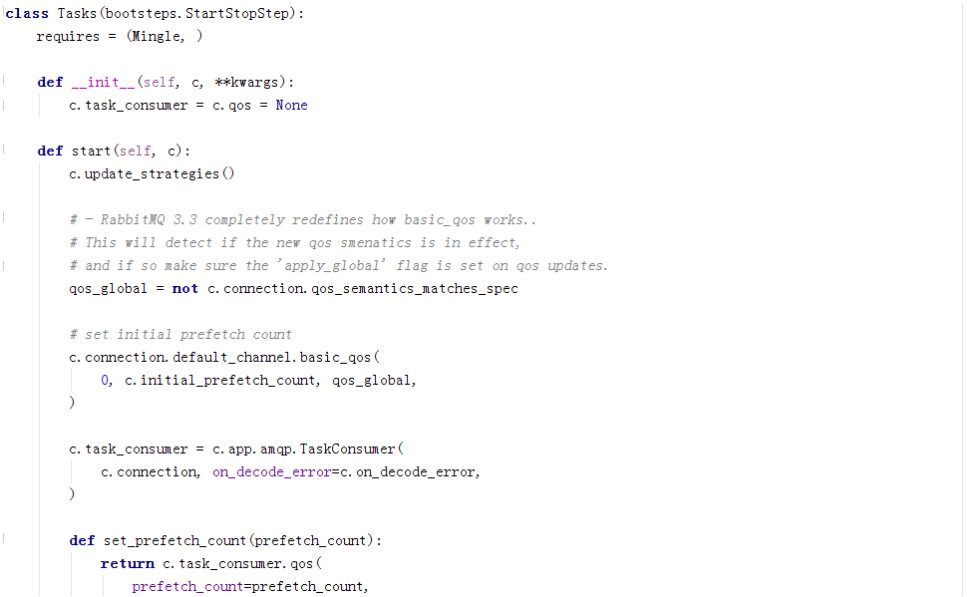
这边引用的ampq的TaskConsumer,ampq的TaskConsumer继承了kombu的Consumer。
可以看到,在关键的几个地方,celery都引用了kombu,Kombu对所有的MQ进行抽象,然后通过接口对外暴露出一致的API(Redis/RabbitMQ/MongoDB),Kombu对MQ的抽象如下:
Message:生产消费的基本单位,就是一条条消息
Connection:对 MQ 连接的抽象,一个 Connection 就对应一个 MQ 的连接
Transport:真实的 MQ 连接,也是真正连接到 MQ(redis/rabbitmq) 的实例
Producers: 发送消息的抽象类
Consumers:接受消息的抽象类
Exchange:MQ 路由,这个和 RabbitMQ 差不多,支持 5种 类型
Queue:对应的 queue 抽象,其实就是一个字符串的封装
Hub是一个eventloop,Connection注册到Hub,一个Connection对应一个Hub。Consumer绑定了消息的处理函数,每一个Consumer初始化的时候都是和Channel绑定的,也就是说我们Consumer包含了Queue也就和Connection关联起来了,Consumer消费消息是通过Queue来消费,然后Queue又转嫁给Channel,再转给connection,Channel是AMQP对MQ的操作的封装,Connection是AMQP对连接的封装,那么两者的关系就是对MQ的操作必然离不开连接,但是,Kombu并不直接让Channel使用Connection来发送/接受请求,而是引入了一个新的抽象Transport,Transport负责具体的MQ的操作,也就是说Channel的操作都会落到Transport上执行。
再看下event loop:
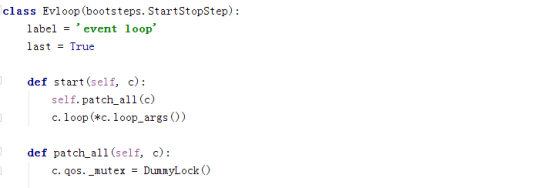

上面我们有了connection以及绑定connection的consumer,下面看看消费者怎么消费消息,如果是带hub的情况:

先对consumer进行一些设置,
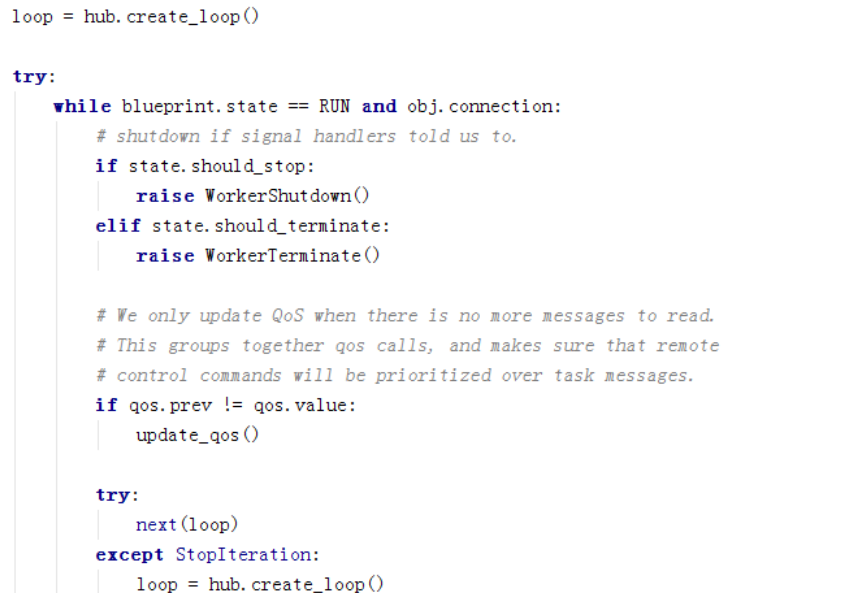
然后开始进行循环。loop是kombu创建的event loop,启用事件循环机制,然后next这边就开始不停的循环获取消息并执行。
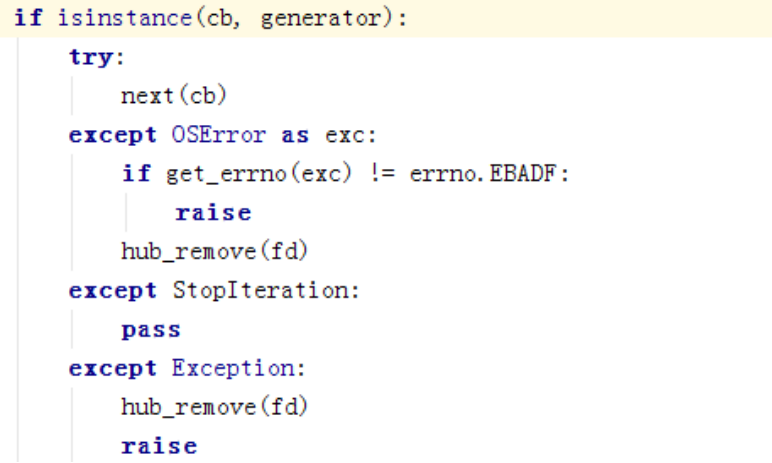
这个是kombu里的部分实现,是对从池里取到的消息进行处理。
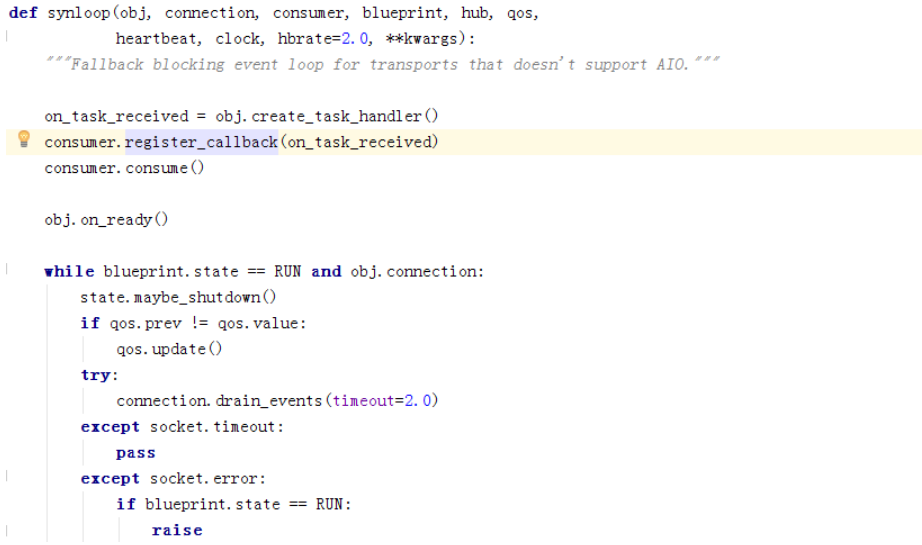
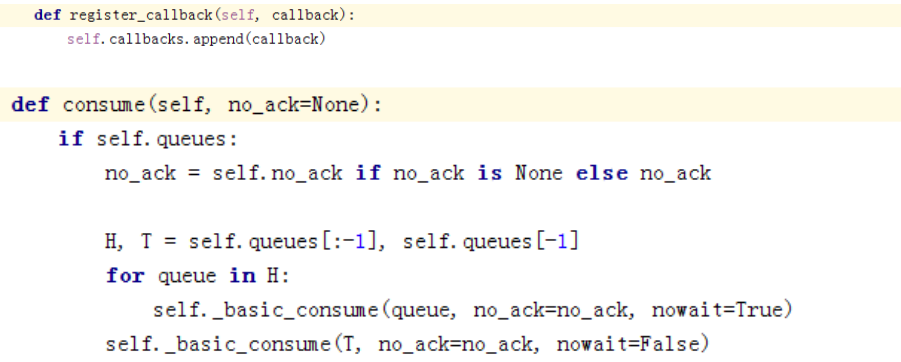
看下同步代码,register_callback将回调注册consumer,然后执行consume:
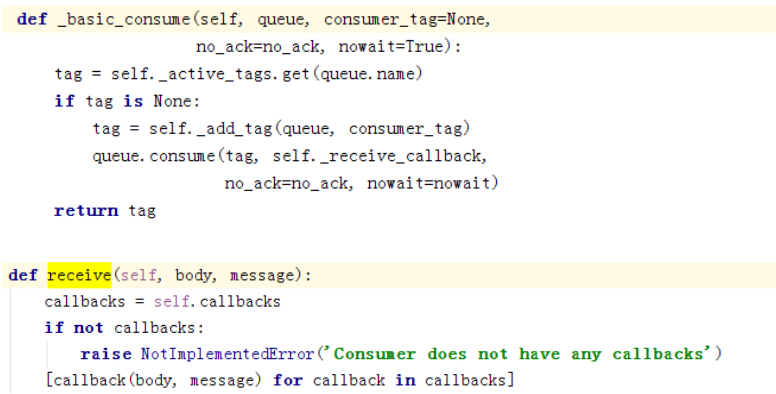
再看消息循环那几行,

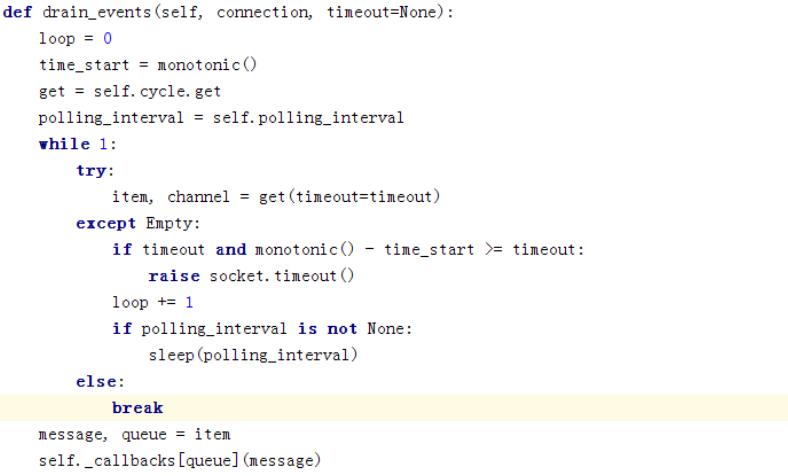
获取到消息后,调用回调函数进行处理。

回调函数使用的是create_task_handler(),strategies是在上面的update_strategies里进行的更新,该函数是在Task里调用的

打印一下strategies里的信息,只截部分图:

下面看下我们怎么启动任务的,

调用到app的send_task

再调用到ampq的publish_task,

最终又交给kombu的publish。
关于pool的选择:

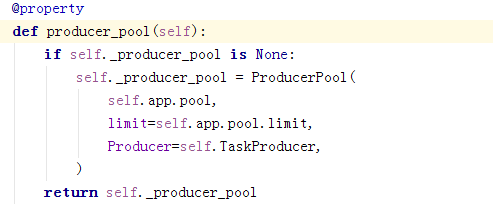
使用的是app的pool,即
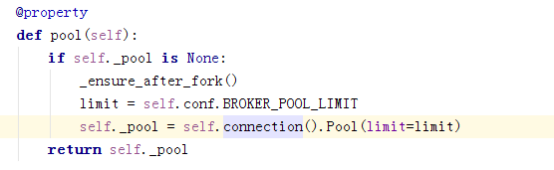
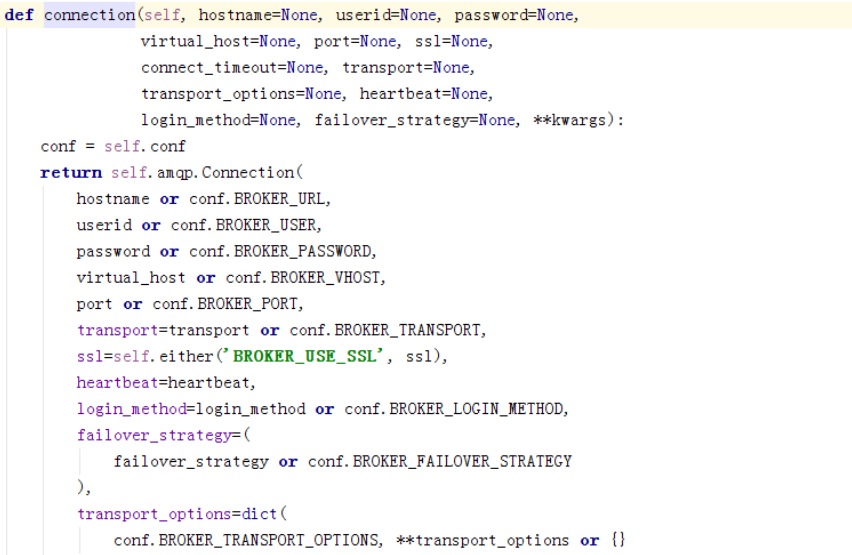
通过connection又走到了ampq再转到kombu里。
Worker和consumer基本大框架就是上面的流程,下面看下beat是怎么实现的。
Beat起动的时候是celery beat,根据我们上面的分析,首先进入的应该是celey/bin/beat.py,然后调用该文件中的Beat的run函数:

然后在指向apps的Beat:

在apps里的Beat调用run:

主要执行了三个函数,init_loader主要初始化并绑定task,第二步设置一些头信息之类的,关键是第三步,主干代码
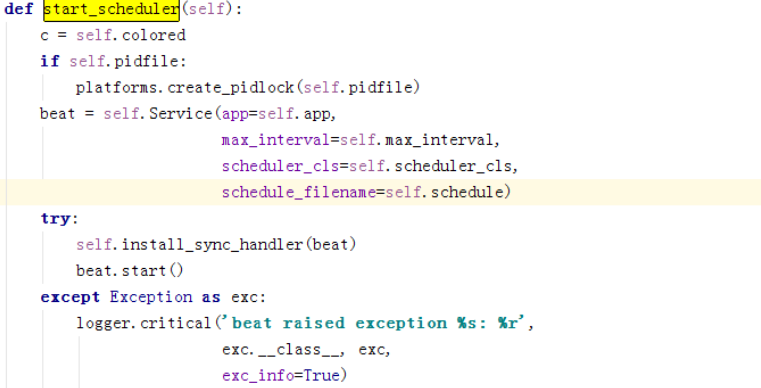
主要是初始化service并start。

Start最关键的部分是那个while循环体,只要不被shutdown,就会一直调用scheduler的tick

这边这个self.schedule就是我们准备调度的任务:

下面看对这些任务的处理:

这是判断是否要执行任务的逻辑,如果要执行,则执行apply_async。
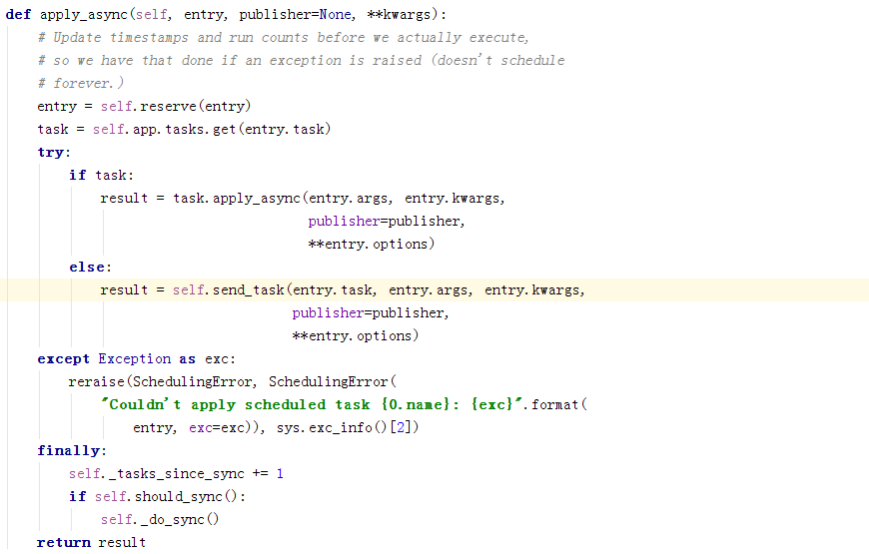
如果发现任务该执行了,则去tasks里获取任务,并执行,这边的apply_async和worker那边的没区别,如果没找到task,则将task注册到broker。
怎样将consumer和concurrency联系起来
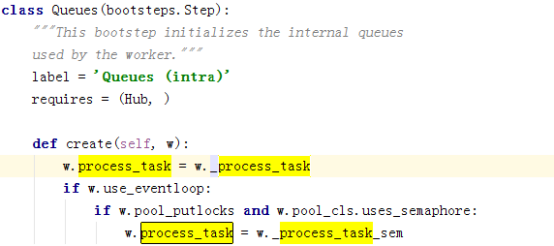
这边调用了_process_task,调用的是worker里的
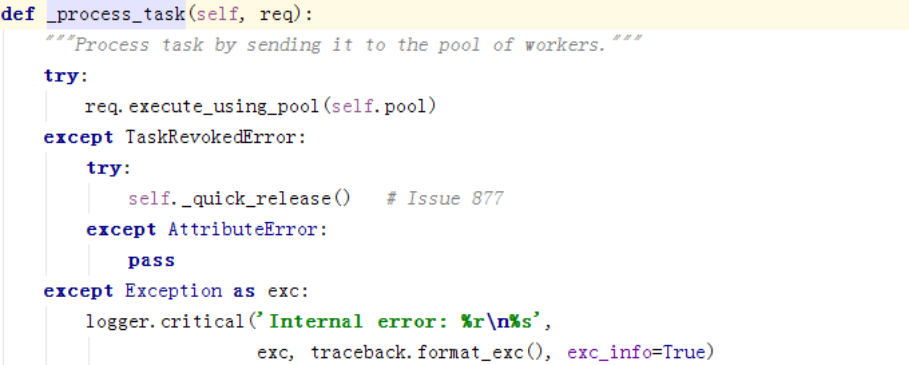
这边调用各种池的启动函数:
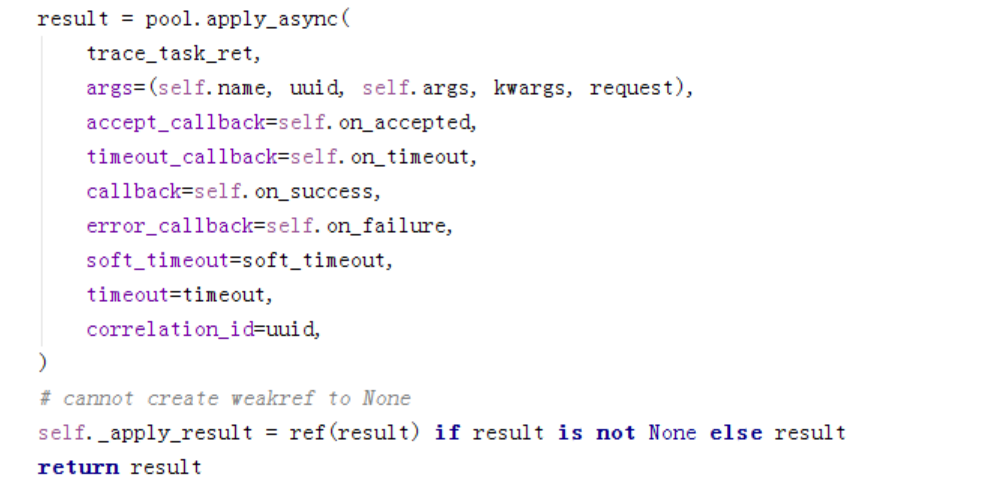
但是queue里只是引用,后面还有别的处理
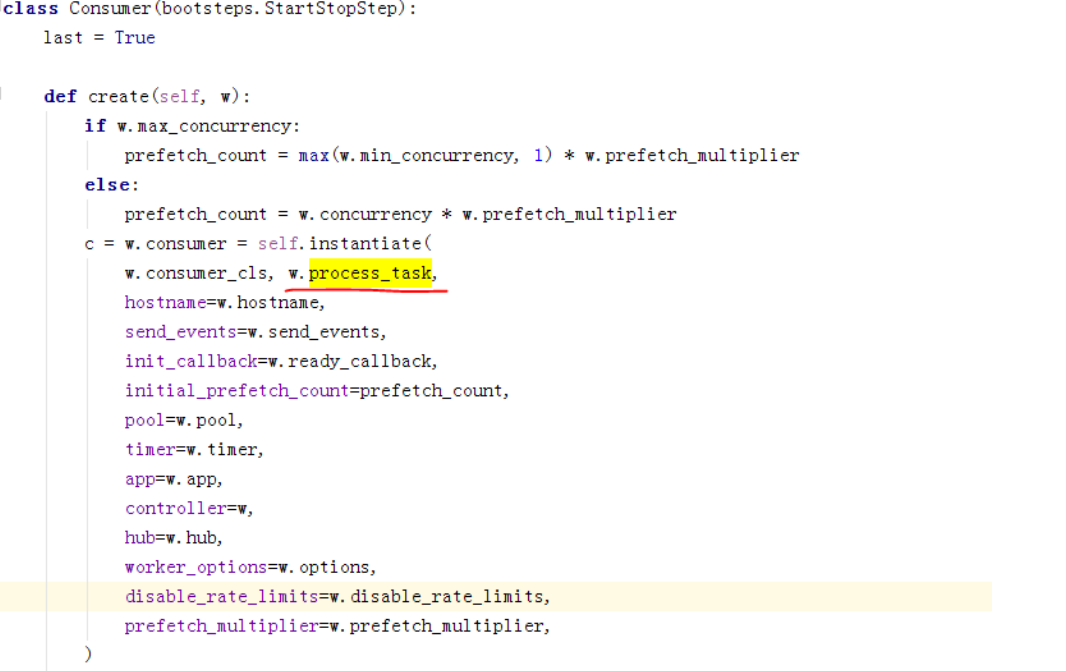
在初始化consumer时候将调用池的操作传了进去,成为了Consumer里的on_task_request

在Tasks调用start的时候会更新strategies
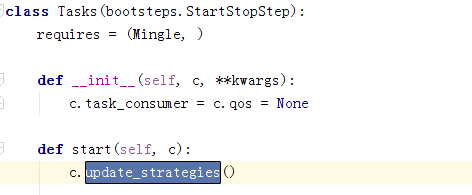
然后在这边调用start_strategy

然后就进入

然后走入strategy的default
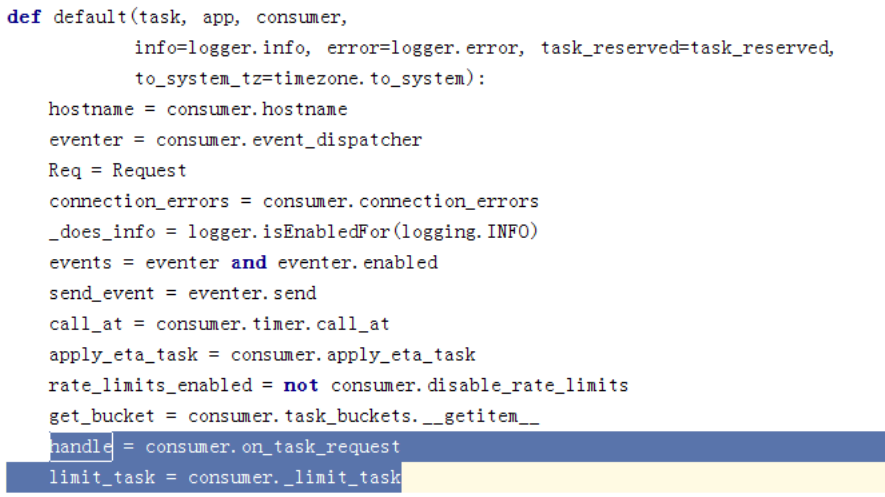
这里取了consumer的on_task_request,就是我们传入的池执行的逻辑,_limit_task是这样的:

做了一些判断,符合条件再执行。

这个文件是strategy的default的下半个文件,做了一些流量控制,然后执行limit_task或者直接执行handler。
这边因为使用的gevent,所以就走到gevent的apply_async,
这边是起一个协程处理,这样就将任务交给了gevent。

具体上面是执行流程,具体在哪里执行的呢?

这边注册了callback,create_task_handler从strategy这边取值取值执行
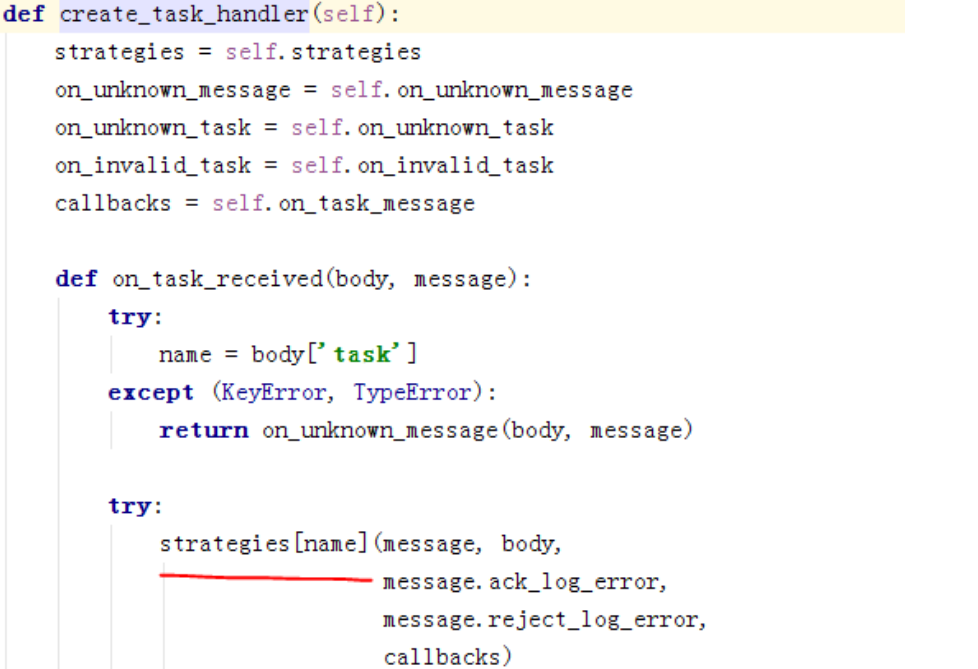
Qos对ack的处理部分:
Kombu的transport的redis.py里的额basic_consume,调用channel的basic_consume;
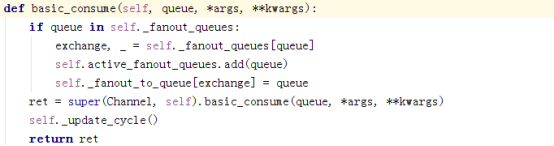
在Kombu.transport.virtual.__init__.py文件中

这里维护了一个dict:self._delivered,一个set:self._dirty和一个int:prefetch_count,
如果no_ack为False在执行consume后会向self._delivered中添加一条数据,
ack后会向self._dirty中添加一条数据,然后,后面会将self._dirty逐条删除,并同时删除self._delivered中的数据,如果没有ack,则不会删除:


每次拉任务的时候会调用can_consume:
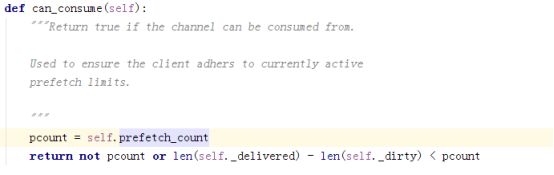
比较prefetch_count和self._delivered减self._dirty的值,如果小于预取限制,则允许,否则不允许。
celery源码解读的更多相关文章
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读 总结(干货)(下)
承接上一篇AFNetworking 3.0 源码解读 总结(干货)(上) 21.网络服务类型NSURLRequestNetworkServiceType 示例代码: typedef NS_ENUM(N ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
随机推荐
- D4下午
开始学图论辣 图的基本模型 图是点和边组成的集合体,G = <V, E> v是点集,e是边集 还有就是有向图无向图啥的 算了太水了不写了 提几个没大见过的吧 环 环上任意两点间可以随意到达 ...
- sun.misc.BASE64Encoder 不建议使用java.sun自带包中的内容
import sun.misc.BASE64Decoder; 在项目中,设计到64位编码的.有时开发会用到JDK中自带的BASE64工具.但sun公司是建议不这样做的.尤其是更新了JDK版本,项目甚至 ...
- Selenium 2自动化测试实战11(键盘事件)
一.键盘事件 1.Keys()类提供了键盘上几乎所有按键的方法,如下实例: #coding:utf-8 from selenium.webdriver.common.keys import Keys ...
- 关机报 at-spi-bus-launcher
查看是否有autostart文件夹,有则不建立 mkdir -v ~/.config/autostart 可直接修改/etc/xdg/autostart/at-spi-dbus-bus.desktop ...
- spring + spring-data-redist + Redis 单机、集群(cluster模式,哨兵模式)
一.单机redis配置 1. 配置redis连接池 <bean id="jedisPoolConfig" class="redis.clients.jedis.Je ...
- linux环境下安装yaf
一.ubuntu环境 1.首先到http://pecl.php.net/get/yaf下载最新版本的yaf,我的是yaf-2.2.9.tgz. 2.解压 tar -zxvf yaf-2.2.9.tgz ...
- P1551 亲戚
这里是题面啊~ 这道题我就不多说了,基本(好吧没有基本)就是一道模板题,读入+并查集+输出,完美结束 #include<set> #include<map> #include& ...
- mariadb数据库基础
1.数据库介绍 简单的说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织,存储的,我们可以通过数据库提供的多种方法来管理数据库里的数据 ...
- python基础--面向对象之绑定非绑定方法
# 类中定义的函数分为两大类, #一,绑定方法(绑定给谁,谁来调用就自动将它本身当做第一个参数传入) # 1,绑定到类的方法:用classmethod装饰器装饰的方法. # 对象也可以掉用,仍将类作为 ...
- Dubbo-zooKeeper入门讲解
1.Dubbo-zooKeeper史上最简单入门实例 2.Dubbo官方文档