scrpy--分布式爬虫
原来的scrapy中的Scheduler维护的是当前机器中的任务队列(存放着Request对象以及回调函数等信息) + 当前的去重队列(存放访问过的url地址)
实现分布式的关键就是需要找一台专门的主机在上面运行一个共享的队列,比如redis。然后重写scrapy的Scheduler,让新的Scheduler到共享的队列中存取Request,并且去除重复的Request请求
1、共享队列
2、重写Scheduler,让它不论是去重还是执行任务都去访问共享队列中的内容
3、为Scheduler专门定制去重规则(利用redis的集合类型)
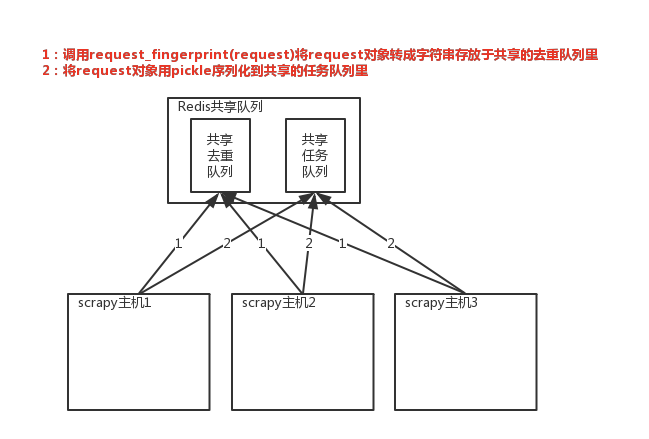
# 在scrapy中使用redis的共享去重队列 # 1、在settings中配置redis链接
REDIS_HOST='localhost' # 主机名称
REDIS_PORT='' # 端口号
REDIS_URL='redis://user:pass@hostname:9001' # 连接url,优先于上面的配置
REDIS_PARAMS={} # redis连接参数
REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接redis的python模块
REDIS_ENCODING = 'utf-8' # redis的编码类型 # 2、让scrapy使用共享的去重队列
# 使用scrapy_redis提供的去重功能,其实是利用redis的集合来实现的
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 3、需要指定Redis中集合的Key名称,Key=存放不重复Request字符串的集合
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
# scrapy_redis去重+调度实现分布式采集 # settings中的配置 SCHEDULER = 'scrapy_redis.scheduler.Scheduler' # 调度器将不重复的任务用pickle序列化后放入共享的任务队列中,默认是
使用优先级队列(默认),别的还有PriorityQueue(有序集合),FifoQueue(列表),LifoQueue(列表)。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 对保存到redis中的request对象进行序列化,默认是通过pickle来进行序列化的
SCHEDULER_SERIALIZER = 'scrapy_redis.picklecompat' # 调度器中请求任务序列化后存放在redis中的key
SCHEDULER_QUEUE_KEY = '%(spider)s:requests'
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True # 是否在开始之前清空调度器和去重记录,True=清空,False=不清空
SCHEDULER_FLUSH_ON_START = False # 去调度器中获取数据的时候,要是是空的话最多等待的时间(最后没数据、未获取到数据)。如果没有的话就立刻返回会造成空循环次数过多,cpu的占有率会直线飙升
SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去重规则,在redis中保存的时候相对应的key
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放到去重队列中
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.REPDupeFilter'
数据的持久化
# 当从目标站点解析出我们想要的内容以后保存成item对象,就会由引擎交给pipeline来进行数据持久化操作/保存到指定的数据库中,scrapy_redis提供了一个pipeline组件,可以帮助我们将item存储到redis中 # 将item持久化保存到redis的时候,指定key和序列化函数
REDIS_ITEMS_KEY = '%(spider)s:items'
REDIS_ITEMS_SERIALIZER = 'json.dumps'
# 从redis中获取起始的URL
scrapy程序爬虫目标站点,一旦爬取完成以后就结束了,万一目标站点内容更新了,拿着时候我们要是还想在此采集的话,就需要重新启动这个scrapy项目,这就会变的非常麻烦,scrapy_redis提供了一种让scrapy项目从redis中获取起始的url,如果没有scrapy就会过一段时间再来取而不会直接结束,所以我们只想要写一个简单的程序脚本,定期的往redis队列中放入一个起始的url就可以了 # 编写脚本的时候,设置起始url从redis中的Key进行获取
REDIS_START_URLS_KEY = '%(name)s:start_urls' # 获取起始URL的时候,去集合中获取呢还是去列表中获取:True=集合, False=列表
REDIS_START_URLS_AS_SET = False # 获取起始URL的时候,要是为True的话,就会使用self.server.spop;False的话就是self.server.lpop
scrpy--分布式爬虫的更多相关文章
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 基于java的分布式爬虫
分类 分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行.由于并行爬行器需要分割下载任 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs)
Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs) Cola:一个分布式爬虫框架 发布时间:2013-06-17 14:58:27, 关注:+2034, 赞美: ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Golang分布式爬虫:抓取煎蛋文章|Redis/Mysql|56,961 篇文章
--- layout: post title: "Golang分布式爬虫:抓取煎蛋文章" date: 2017-04-15 author: hunterhug categories ...
- 纯手工打造简单分布式爬虫(Python)
前言 这次分享的文章是我<Python爬虫开发与项目实战>基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容. ...
- 分布式爬虫框架XXL-CRAWLER
<分布式爬虫框架XXL-CRAWLER> 一.简介 1.1 概述 XXL-CRAWLER 是一个分布式爬虫框架.一行代码开发一个分布式爬虫,拥有"多线程.异步.IP动态代理.分布 ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
随机推荐
- delphi里为程序任务栏右键菜单添加自定义菜单
本文讲解的是为自身程序的任务栏右键菜单里添加自己定义的菜单的方法: delphi添加任务栏右键菜单 procedure TForm1.FormCreate(Sender: TObject); var ...
- NX二次开发-time.h获取计算机本地时间
NX9+VS2012 #include <stdio.h> #include <time.h> char *wday[] = { "Sun", " ...
- 良田高拍仪集成vue项目
一.硬件及开发包说明: 产品型号为良田高拍仪S1800A3,集成b/s系统,适用现代浏览器,图片使用BASE64数据.开发包的bin文件下的video.flt文件需要和高拍仪型号的硬件id对应,这个可 ...
- luoguP5162 WD与积木
我怎么这么zz啊.... 法一: 枚举最后一层的方案:没了... 法二: 生成函数:没了. k*F^k(x),就是错位相减. 法三: 我的辣鸡做法:生成函数 求方案数,用的等比数列求和....多项式快 ...
- KiFastCallEntry() 机制分析
1. 概述 从 windows xp 和 windows 2003 开始使用了快速切入内核的方式提供系统服务例程的调用. KiFastCallEntry() 的实现是直接使用汇编语言,C 语言不能直接 ...
- 2019 IEEEXtreme 13.0 题解记录
比赛时间 2019.10.19 8:00 - 2019.10.20 8:00 比赛网站 https://csacademy.com/ieeextreme13 // 连续24小时做题真的是极限体验 // ...
- gdb常用功能
1,调试core dump 文件 ulimit -c 1024:设置coredump文件大小为1024,否则默认不会生成coredump文件 gdb -c core:gdb调试该cored ...
- ARM GNU 专有符号
1. @ 表示注释从当前位置到行尾的字符. 2. # 注释掉一整行. 3. ; 新行分隔符.
- Android Studio Gradle无法获取pom文件
错误提示: Error:Execution failed for task ':app:lintVitalRelease'. > Could not resolve all artifacts ...
- Yii2 在php 7.2环境下运行,提示 Cannot use ‘Object’ as class name
出错原因是: Object是php7.2中的保留类名,不可以使用Object作为类的名称. The object name was previously soft-reserved in PHP 7. ...