吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的
复习配置hadoop初始化环境
复习配置hdfs的配置文件
学会配置hadoop的配置文件
了解yarn的原理
实验原理
1.yarn是什么
前面安装好了hdfs文件系统,我们可以根据需求进行数据的读写操作。hdfs解决了大数据的存储,接下来的问题就是根据实际的业务需求进行计算。目前大数据的计算业务主要有离线计算、实时计算、交互式查询、机器学习、图计算。例如storm是处理实时计算的,hadoop的mapreduce是处理批处理计算业务的。hive则是进行交互式查询的。这么多计算框架在一起,难免会引起资源管理的混乱问题,yarn则是用于管理计算资源的,计算资源主要是内存和CPU,默认是管理内存。
Apache YARN(Yet Another Resource Negotiato的缩写)是Hadoop的集群资源管理系统。YARN被引入Hadoop2。最初是为了改善MapReduce的实现,但它具有足够的通用性,同样可以支持其他的分布式计算模式。
YARN提供请求好而是用进群资源的API,但这些API很少直接使用于用户代码。相反,用户代码用的是分布式计算框架提供的更高层API,这些API建立在YARN之上且向用户隐藏了资源管理细节。
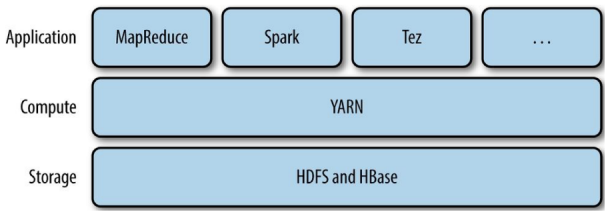
MapReduce、Spark、Tez这样的计算框架均以Yarn应用程序的形式运行于集群计算层(Yarn)和集群存储层(HDFS或HBase)之上,而Pig、Hive、Crunch则运行于MapReduce、Spark或Tez之上,并没有与Yarn直接交互。
Yarn的核心服务由两个组件提供:
Resource Manager:每个集群一个实例,用于管理整个集群的资源使用;
Node Manager:每个集群多个实例,用于自身Container的启动和监测(每个Node Manager上可能有多个Container)。
注:根据Yarn配置的不同,Container可能是一个Unix进程或者一个Linux cgroup实例,在受限的资源范围内(如内存、CPU等)执行特定应用程序的代码。
2.yarn资源调度的方式
目前yarn调度主要有两种:先进先出的调度模式和队列调度模式,分别是Google和Yahoo开源设计的,前者按照提交的顺序调度,后者则将用户划分为队列,给每个队列一定的资源。
yarn将集群资源抽象成一个个容器Container,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
3.yarn的安装
yarn的配置文件主要是mapred-site.xml、yarn-site.xml,配置这个文件的相关属性即可。
4.yarn配置
(1)mapred-site.xml文件配置内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
(2)yarn-site.xml文件需要配置的内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager的节点地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node6</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
实验环境
1.操作系统
服务器1:Linux_Centos
服务器2:Linux_Centos
服务器3:Linux_Centos
服务器4:Linux_Centos
操作机:Windows_7
服务器1默认用户名:root,密码:123456
服务器2默认用户名:root,密码:123456
服务器3默认用户名:root,密码:123456
服务器4默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。
5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。


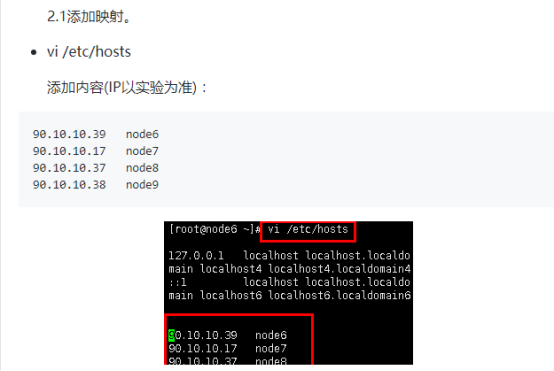
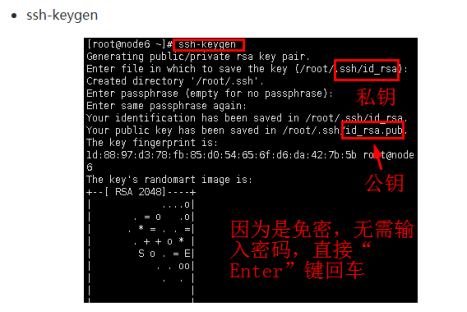
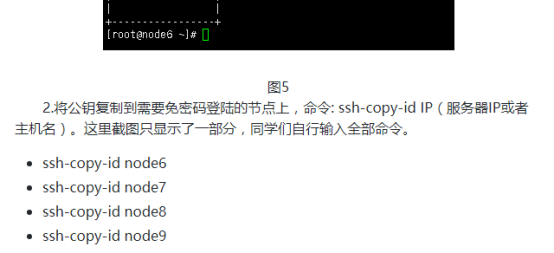
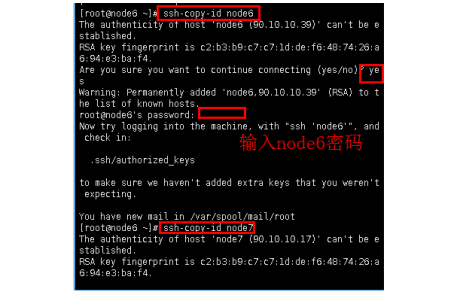
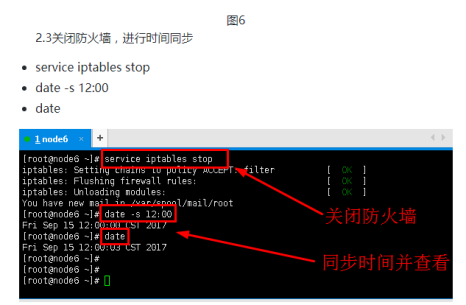
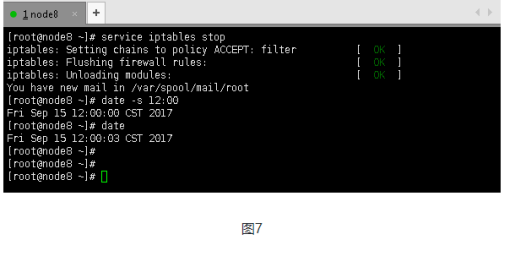

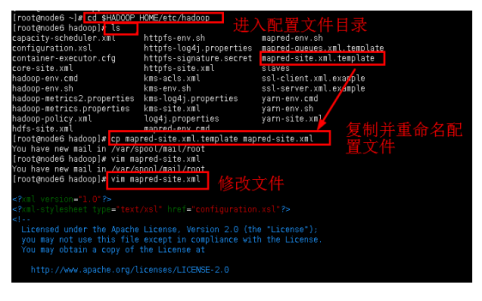
添加内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>


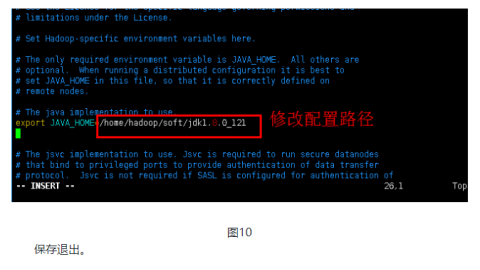
3.4配置同目录下的master文件(目录下没有此文件,直接新建并添加内容),添加管理节点的地址(每台节点都需要执行)。
vim master
添加内容:
node 6 //以node6为主节点
配置同目录下的slaves文件,添加工作节点的地址(每台节点都需要执行)。
vim slaves
添加datanode:
node7
node8
node9
这里只显示了命令和需要添加的内容,具体操作就不再演示。
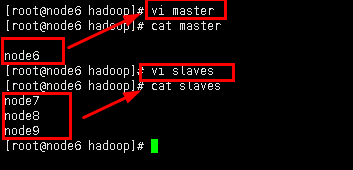
3.5同目录下,yarn-site.xml文件需要配置的内容:
vim yarn-site.xml
添加内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node6</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
前一个是nodemanager的内容,可以暂时不做了解,后面是resourcemanager的节点地址。其中第一个照写,第二个配置resourcemanager位置,一般情况下这个节点就是hdfs的namenode节点(node6)。
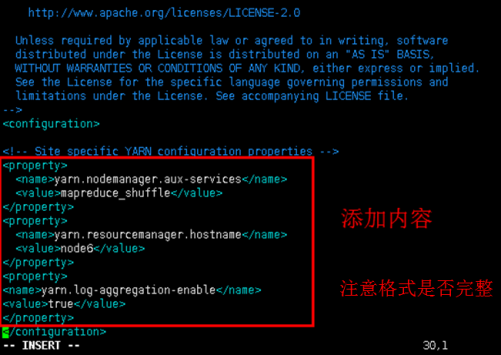
将none6 中的yarn配置文件直接复制到node7、node8、node9。(注意命令空格问题)
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop/yarn-site.xml root@node7:/home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop/yarn-site.xml root@node8:/home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop/yarn-site.xml root@node9:/home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop
注:也可以以同样方法node6上修改的配置文件复制到其他工作节点。注意要命令文件名称的修改。
步骤4:启动yarn集群并检查其启动情况
4.1启动yarn命令,程序为sbin目录下的start-yarn.sh。
cd ../..
sbin/strat-yarn.sh
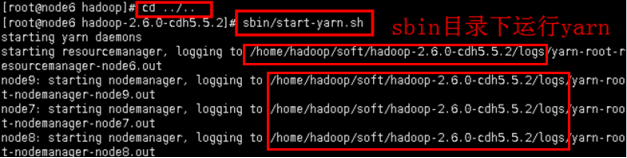
启动之后,会提示四个日志文件的地址,如果出现异常,可以查看这些配置文件进行分析。
4.2通过jps命令,看到有相应的进程。
jps

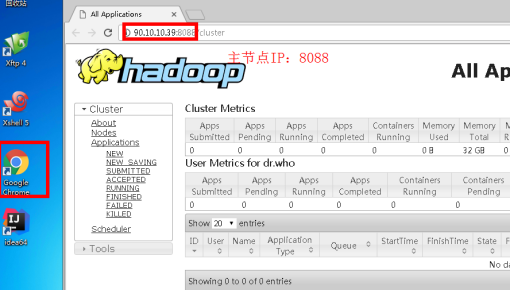
4.3打开浏览器,输入resourcemanager的IP,加上端口8088。
吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase微博案例
实验目的 熟悉hbase表格设计的方法 熟悉hbase的javaAPI 通过API理解掌握hbase的数据的逻辑视图 了解MVC的服务端设计方式 实验原理 上次我们已经初步设计了学生选课案例的,具体功 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
随机推荐
- C++不同类中的特征标相同的同名函数
转载请注明出处,版权归作者所有 lyzaily@126.com yanzhong.lee 作者按: 从这篇文章中,我们主要会认识到一下几点: ...
- 网络最大流(EK)
以前在oi中见到网络流的题都是直接跳过,由于本蒟蒻的理解能力太弱,导致网络流的学习不断推迟甚至被安排在了tarjan之后,原本计划于学习完最短路后就来学网络流的想法也随之破灭,在看完众多大佬 的博客后 ...
- HTML5与HTML4的区别-----文档结构
HTML5在结构和语法上做了大量的简化.当然,也提供了语义化的标签 结构上区别: 1.简化了文档声明语句 HTML5仅规定了一种: <!DOCTYPE html> 2. ...
- iRedmail的php由5.4升级到5.6
安装ireadmail时,自带的php是5.4,打算升级到5.6. 升级前注意备份原来的/etc/php-fpm.d下的www.conf,文件内容如下: [inet] user = nginx gro ...
- DFS判断图是否有环
利用_DFS_来判断无向图是否存在环的条件思路,我看一次_DFS_是否能访问到之前访问到的节点,如果能够访问到,就说明图存在环,那么关键问题就是判断是一次DFS?,追根到_DFS_算法的实现细节, ...
- Python - os.walk()详细使用
os.walk() 方法简单介绍 主要用来遍历一个目录内各个子目录和子文件 是一个简单易用的文件.目录遍历器,可以帮助我们高效的处理文件.目录方面的事情. 方法参数介绍 os.walk(top[, t ...
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- .NET Core之单元测试(四):Fluent Assertions的使用
目录 什么是Fluent Assertions 待测试API 测试用例 什么是Fluent Assertions Fluent Assertions 是 .NET 平台下的一组扩展方法,用于单元测试中 ...
- Gridview的stretchMode等属性详解
<GridView android:id="@+id/grid"android:layout_width="fill_parent"android:lay ...
- android编译/反编译常用工具及项目依赖关系
项目依赖关系 apktool:依赖smali/baksmali,XML部分 AXMLPrinter2 JEB:dx 工具依赖 AOSP , 反编译dex 依赖 apktool dex2jar:依赖 A ...