GC原理---垃圾收集器
垃圾收集器
如果说收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现
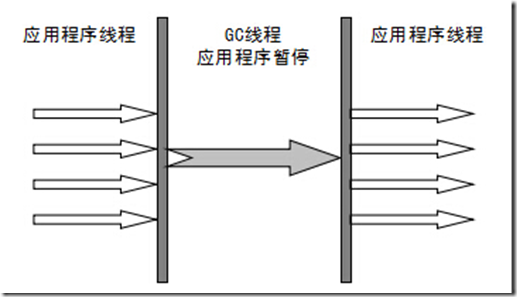
Serial收集器
- 串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会Stop The World(服务暂停)
- 参数控制:-XX:+UseSerialGC 串行收集器
ParNew收集器
- ParNew收集器其实就是Serial收集器的多线程版本。新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
- 参数控制:-XX:+UseParNewGC ParNew收集器
-XX:ParallelGCThreads 限制线程数量 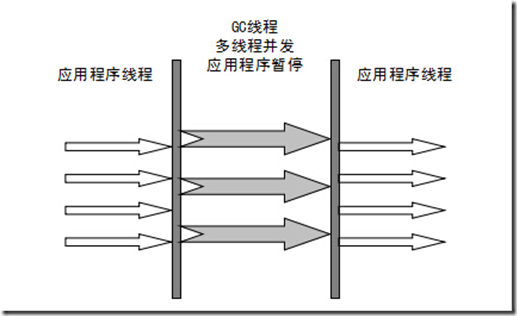
Parallel Scavenge收集器
- Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;
- 停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验,而高吞吐量则可以高效地利用CPU时间,主要适合在后台运算而不需要太多交互的任务。
- Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间 -XX:MaxGCPauseMillis以及直接设置吞吐量大小的-XX:GCTimeRatio。
- 新生代复制算法、老年代标记-压缩
- 参数控制:-XX:+UseParallelGC 使用Parallel收集器+ 老年代串行
Parallel Old 收集器
- Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供
- 参数控制: -XX:+UseParallelOldGC 使用Parallel收集器+ 老年代并行
CMS收集器
- CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
- 目前很大一部分的Java应用都集中在互联网站或B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。
- 从名字(包含“Mark Sweep”)上就可以看出CMS收集器是基于“标记-清除”算法实现的,它的运作过程相对于前面几种收集器来说要更复杂一些,整个过程分为4个步骤,包括:
- 初始标记(CMS initial mark)
并发标记(CMS concurrent mark)
重新标记(CMS remark)
并发清除(CMS concurrent sweep)
- 初始标记(CMS initial mark)
- 其中初始标记、重新标记这两个步骤仍然需要“Stop The World”(STW)。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,并发标记阶段就是进行GC Roots Tracing的过程,而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
- 由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行。老年代收集器(新生代使用ParNew)
- 优点:并发收集、低停顿
- 缺点:产生大量空间碎片、并发阶段会降低吞吐量
- .CMS收集器对CPU资源非常敏感。默认启动的回收线程数是(CPU+3)/4. 当CPU 4个以上时,并发回收垃圾收集线程不少于25%的CPU资源。
Serial Old收集器
Serial Old是Serial收集器的老年代版本,它同样是一个单线程收集器。给Client模式下的虚拟机使用。
新生代采用复制算法,暂停所有用户线程;
老年代采用标记-整理算法,暂停所有用户线程;
G1收集器
- 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
- 可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
- 使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合
- G1将新生代,老年代的物理空间划分取消了。
在java 8中,持久代也移动到了普通的堆内存空间中,改为元空间。
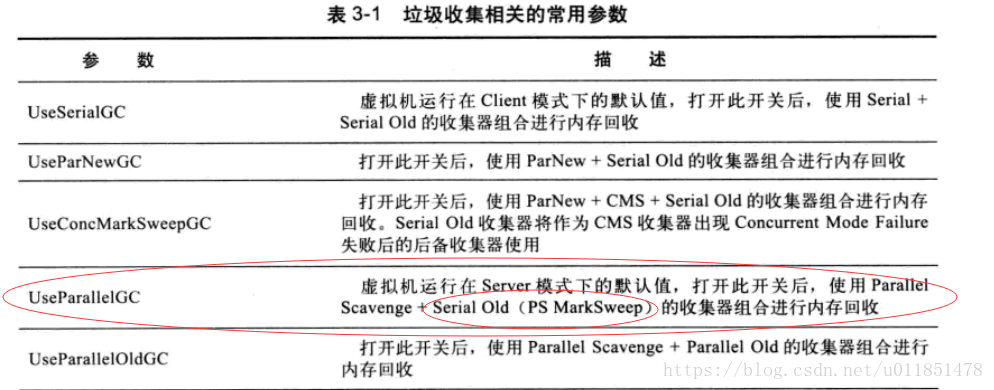
jdk8环境下,默认使用 Parallel Scavenge(新生代)+ Serial Old(老年代)
- java -XX:+PrintCommandLineFlags -version
GC原理---垃圾收集器的更多相关文章
- jvm系列(三):java GC算法 垃圾收集器
GC算法 垃圾收集器 概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计 ...
- GC算法 垃圾收集器
GC算法 垃圾收集器 参考:http://www.cnblogs.com/ityouknow/p/5614961.html 概述 垃圾收集 Garbage Collection 通常被称为“GC”,它 ...
- Java GC算法 垃圾收集器
GC算法 垃圾收集器 概述 垃圾收集 Garbage Collection 通常被称为"GC",它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. ...
- jvm系列(三):GC算法 垃圾收集器
原文出处:纯洁的微笑 这篇文件将给大家介绍GC都有哪几种算法,以及JVM都有那些垃圾回收器,它们的工作原理. 概述 垃圾收集 Garbage Collection 通常被称为"GC" ...
- jvm系列三、java GC算法 垃圾收集器
原文链接:http://www.cnblogs.com/ityouknow/p/5614961.html 概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 ...
- Java虚拟机(二):Java GC算法 垃圾收集器
概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟机栈.本地方 ...
- JVM活学活用——GC算法 垃圾收集器
概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟机栈.本地方 ...
- JVM GC之垃圾收集器
简述 如果说收集算法时内存回收的方法论,那么垃圾收集器就是内存回收的具体实现.这里我们讨论的垃圾收集器是基于JKD1.7之后的Hotspot虚拟机,这个虚拟机包含的所有收集器如图: Serial 收集 ...
- GC原理---垃圾收集算法
垃圾收集算法 Mark-Sweep(标记-清除算法) 标记清除算法分为两个阶段,标记阶段和清除阶段.标记阶段任务是标记出所有需要回收的对象,清除阶段就是清除被标记对象的空间. 优缺点:实现简单,容易产 ...
随机推荐
- slim的中间件
slim中间件的作用简单来说就是过滤数据,request过来的数据要经过中间件才能到达内部,然后内部数据要到达外部的时候,也要经过中间件,正常通过才能到达外部
- DQN 强化学习
pytorch比tenserflow简单. 所以我们模仿用tensorflow写的强化学习. 学习资料: 本节的全部代码 Tensorflow 的 100行 DQN 代码 我制作的 DQN 动画简介 ...
- Python3 collections模块的使用
collections 介绍 collections是Python内建的一个集合模块,提供了许多有用的集合类和方法. 可以把它理解为一个容器,里面提供Python标准内建容器 dict , list ...
- Cocos Creator | 飞刀大乱斗开发教程系列(一)
预览效果 具体内容 ■ 这一期,主要讲解主页下方列表选项如何实现.也就是游戏开始后,加载所有现有的英雄列表,这一功能的实现,如下图部分. ■ 列表使用 ScrollView 实现,横向滚动,设置好上下 ...
- $NOIp$做题记录
虽然去年做了挺多了也写了篇一句话题解了但一年过去也忘得差不多了$kk$ 所以重新来整理下$kk$ $2018(4/6$ [X]积木大赛 大概讲下$O(n)$的数学方法. 我是从分治类比来的$QwQ$. ...
- [系列] Go 如何解析 JSON 数据?
概述 最近掉进需求坑了,刚爬上来,评估排期出现了严重问题,下面三张图很符合当时的心境. 谈需求 估排期 开始干 为啥会这样,我简单总结了下: 与第三方对接. 跨团队对接. 首次用 Go 做项目. 业务 ...
- Oracle:存储过程的使用
Oracle:存储过程的使用 以sys身份登录,创建用户c##zs,密码111,分配dba角色 以c##zs身份登录,导入数据表 编写存储过程,根据学生学号,查询出学生所选课程成绩等级, 打印结果示例 ...
- Kafka原理及应用(一)
一. Kafka简介 (1) 消息中间件的两种实现模式 JMS (Java Message Service) 对消息的发送和接收定义了两种模式: 点对点模式:消息的生产和消费者均只有一个,消息由生产者 ...
- 用本地自定义域名访问远程服务器,并支持websocket和cookie
场景 在公司会有很多测试的机器,或者一些OA服务,Confluence,Jenkins,各种中间件的后台等等,都使用HTTP访问,且由于是内网机器没有域名,输入IP又要输入不同端口,访问起来比较麻烦. ...
- Java线程池学习总结
一 使用线程池的好处 池化技术相比大家已经屡见不鲜了,线程池.数据库连接池.Http 连接池等等都是对这个思想的应用.池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率. 线程池提供了 ...