Sentinel 发布里程碑版本,添加集群流控功能
自去年10月底发布GA版本后,Sentinel在近期发布了另一个里程碑版本v1.4(最新的版本号是v1.4.1),加入了开发者关注的集群流控功能。
集群流控简介
为什么要使用集群流控呢?假设我们希望给某个用户限制调用某个 API 的总 QPS 为 50,但机器数可能很多(比如有 100 台)。这时候我们很自然地就想到,找一个 server 来专门来统计总的调用量,其它的实例都与这台 server 通信来判断是否可以调用。这就是最基础的集群流控的方式。
那么这个 server 如何部署呢?最直观的方式就是作为独立的 token server 进程启动,独立部署:
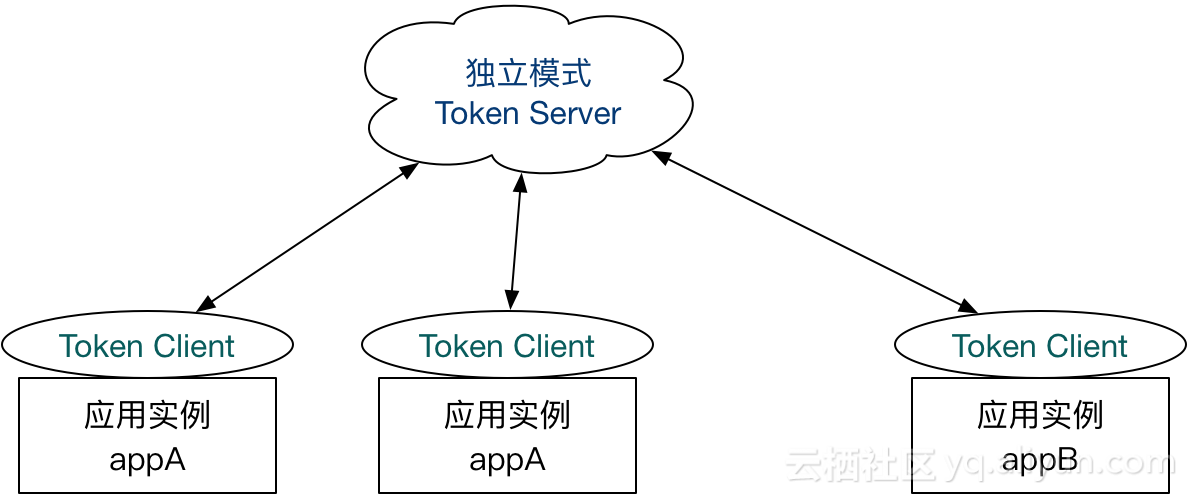
另一种就是嵌入模式(Embedded),即作为内置的 token server 与服务在同一进程中启动,无需单独部署:
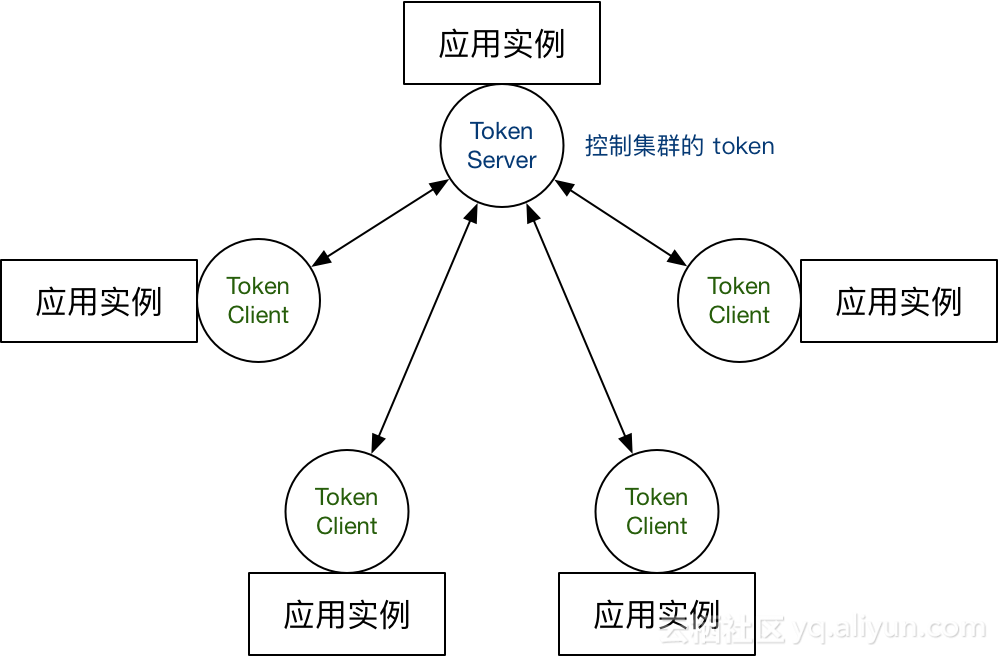
另外集群流控还可以解决流量不均匀导致总体限流效果不佳的问题。假设集群中有 10 台机器,我们给每台机器设置单机限流阈值为 10 QPS,理想情况下整个集群的限流阈值就为 100 QPS。不过实际情况下流量到每台机器可能会不均匀,会导致总量没有到的情况下某些机器就开始限流: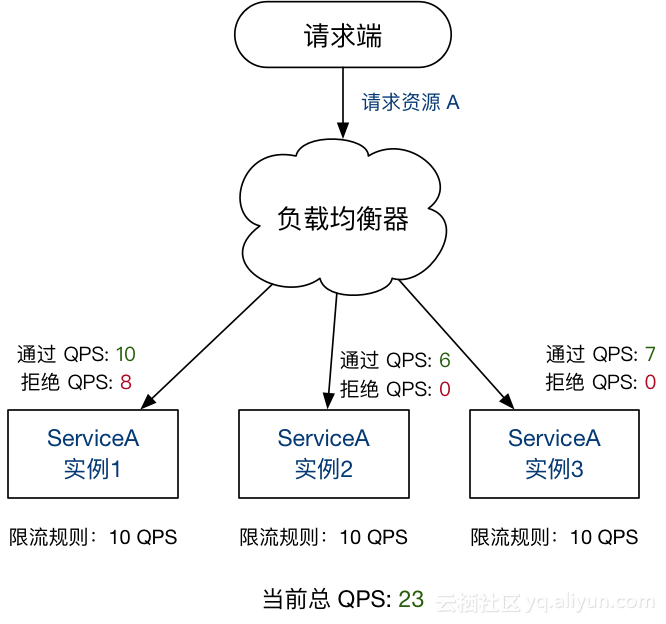
因此仅靠单机维度去限制的话会无法精确地限制总体流量。而集群流控可以精确地控制整个集群的调用总量,结合单机限流兜底,可以更好地发挥流量控制的效果。
Sentinel 1.4.0 开始引入了集群流控模块,主要分为两个部分:Token Client 和 Token Server:
- Token Client 即集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。Sentinel 集群流控的通信底层采用 Netty 实现。
- Token Server 即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)。
Sentinel 集群流控支持限流规则和热点规则两种规则。集群流控支持两种形式的阈值计算方式:
- 集群总体模式:即限制整个集群内的某个资源的总体 QPS 不超过此阈值。
- 单机均摊模式:单机均摊模式下配置的阈值等同于单机能够承受的限额,Token Server 会根据连接数来计算总的阈值(比如独立模式下有 3 个 client 连接到了 token server,然后配的单机均摊阈值为 10,则计算出的集群总量就为 30),按照计算出的总的阈值来进行限制。这种方式根据当前的连接数实时计算总的阈值,对于机器经常进行变更的环境非常适合。
部署方式
Sentinel 集群流控服务端支持独立模式(Alone)以及嵌入模式(Embedded)。两者的优缺点对比:
- 独立模式作为独立的 token server 进程启动,独立部署,隔离性好,但是需要额外的部署操作。独立模式适合作为 Global Rate Limiter 给整个集群提供流控服务。
- 嵌入模式作为内置的 token server 嵌入到应用进程中。嵌入模式下集群中各个实例都是对等的,token server 和 client 可以随时进行转变,无需单独部署,灵活性比较好。但缺点就是隔离性不佳,
需要限制 token server 的总 QPS,防止影响应用本身。嵌入模式适合某个应用集群内部的流控。
Sentinel 提供 API 来对 client / server 进行配置以及指定模式,但是机器多的时候不方便进行管理。一般我们需要通过 Sentinel 控制台的集群流控管理功能来统一管理某个应用集群下所有的 token server 和 token client,灵活进行分配。
配置
配置是集群流控中比较重要的一部分。Sentinel 集群流控的配置主要包含几部分:
集群规则配置
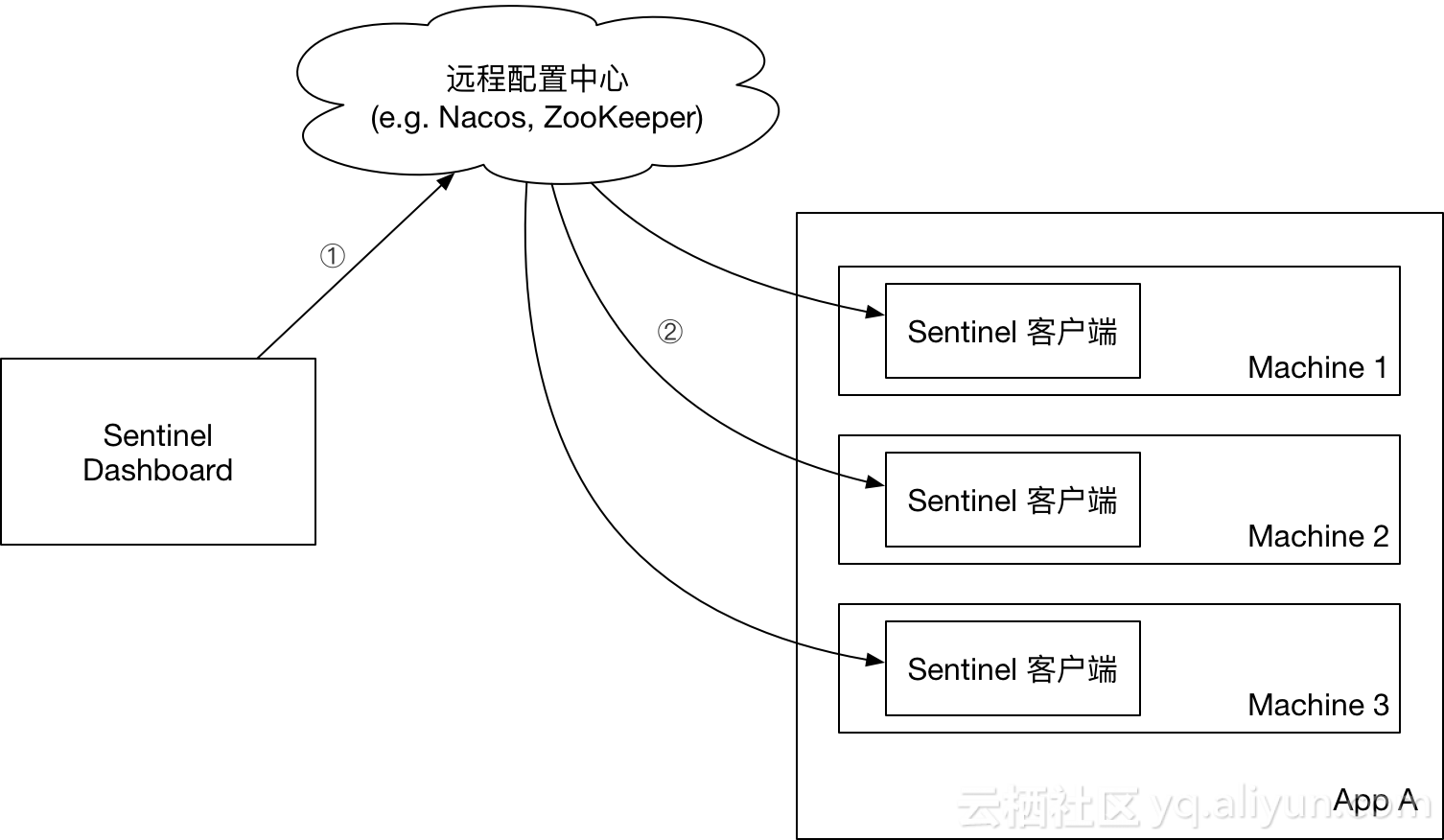
集群规则配置需要借助动态规则源。以集群流控规则为例,对于客户端,我们可以用之前的方式向FlowRuleManager 注册动态规则源。而对于 Token Server,我们需要向集群规则管理器 ClusterFlowRuleManager 注册规则源。我们推荐的方式是在应用端注册动态规则源,然后在 Sentinel 控制台直接推送规则到配置中心,即 push 模式:
Token Server / Client 的分配
以嵌入模式为例,一个比较好的实践是:结合流量分布和实时负载情况来在服务集群中选取几台较为空闲的机器作为 Token Server,其它的机器作为 Token Client,划分成几组,分别归属各自的 Token Server 管理。最后组成一个映射表,类似于:
// ip: token server IP, port: token server port, clientSet: 所管辖的 token client 集合
[{"clientSet":["112.12.88.66@8729","112.12.88.67@8727"],"ip":"112.12.88.68","machineId":"112.12.88.68@8728","port":11111}]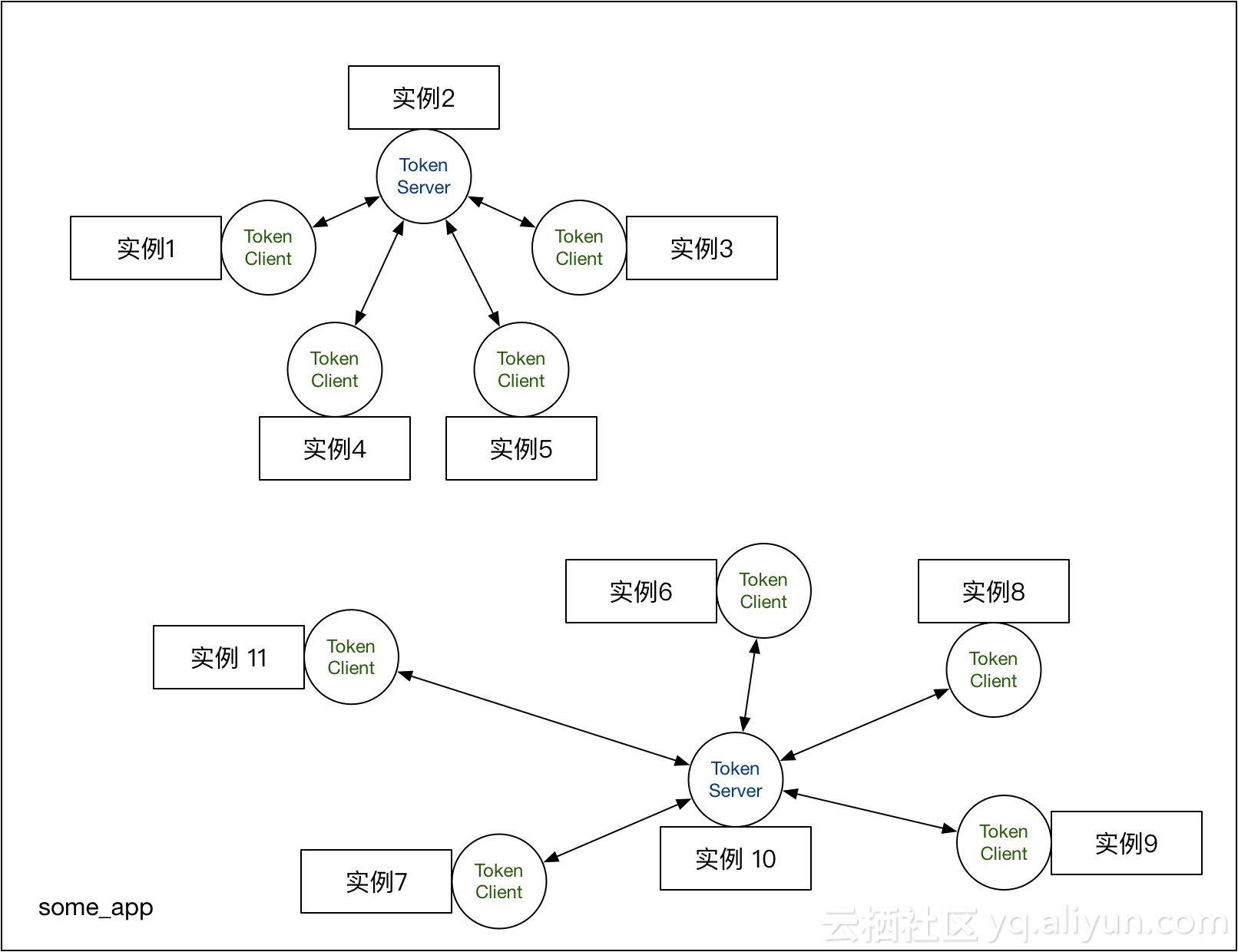
然后像 Token Client / Token Server 通信配置、集群流控模式等配置源都可以监听这个分配映射表对应的数据源,来解析自己的身份和相关通信配置。当分配映射表变更时每台机器对应的身份和配置也会实时变更,实时生效。Sentinel 1.4.1 改进了 Sentinel 控制台集群流控的管理页面,可以直接以应用维度来分配 Token Server。可以参考本文后面的指引来使用。
其它配置
其它的配置比如 Token Server 的命名空间集合(namespace set,用于指定该 Token Server 可以为哪些应用/分组服务)、最大允许的总 QPS 等,既可以通过 Sentinel 预留的 HTTP API 来变更配置,也可以通过注册动态配置源来进行配置。
快速使用集群流控
下面我们来看一下如何快速使用集群流控功能。接入集群流控模块的步骤如下:
(1)引入集群流控依赖
这里我们以嵌入模式来运行 token server,即在应用集群中指定某台机器作为 token server,其它的机器指定为 token client。
首先我们引入集群流控相关依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-cluster-client-default</artifactId>
<version>1.4.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-cluster-server-default</artifactId>
<version>1.4.1</version>
</dependency>(2)配置动态规则源
要想使用集群流控功能,我们需要在应用端配置动态规则源,并通过 Sentinel 控制台实时进行推送。流程如下所示:
以流控规则为例,假设我们使用 ZooKeeper 作为配置中心,则可以向客户端 FlowRuleManager 注册 ZooKeeper 动态规则源:
ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new ZookeeperDataSource<>(remoteAddress, path, source -> JSON.parseObject(source, new TypeReference<List<FlowRule>>() {}));
FlowRuleManager.register2Property(flowRuleDataSource.getProperty());另外我们还需要针对 Token Server 注册集群规则数据源。由于嵌入模式下 token server 和 client 可以随时变换,因此我们只需在每个实例都向集群流控规则管理器 ClusterFlowRuleManager 注册动态规则源即可。Token Server 抽象出了命名空间(namespace)的概念,可以支持多个应用/服务,因此我们需要注册一个自动根据 namespace 创建动态规则源的生成器:
// Supplier 会根据 namespace 生成的动态规则源,类型为 SentinelProperty<List<FlowRule>>,针对不同的 namespace 生成不同的规则源(监听不同 namespace 的 path).
// 默认 namespace 为应用名(project.name)
// ClusterFlowRuleManager 针对集群限流规则,ClusterParamFlowRuleManager 针对集群热点规则,配置方式类似
ClusterFlowRuleManager.setPropertySupplier(namespace -> {
return new SomeDataSource(address, dataIdPrefix + namespace).getProperty();
});(3)控制台进行改造适配动态规则源
我们只需简单对 Sentinel 控制台进行改造即可直接将流控规则推送至配置中心。从 Sentinel 1.4.0 开始,Sentinel 控制台提供 DynamicRulePublisher 和 DynamicRuleProvider 接口用于实现应用维度的规则推送和拉取,并提供了 Nacos 推送的示例(位于 test 目录下)。我们只需要实现自己的 DynamicRulePublisher 和 DynamicRuleProvider 接口并在 FlowControllerV2 类中相应位置通过 @Qualifier 注解指定对应的 bean name 即可,类似于:
@Autowired
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;Sentinel 控制台提供应用维度推送的页面(/v2/flow)。在上述配置完成后,我们可以在此页面向配置中心推送规则:
(4)控制台分配 Token Server
当上面的步骤都完成后,我们就可以在 Sentinel 控制台的“集群流控” Token Server 列表页面管理分配 token server 了。假设我们启动了三个应用实例,我们选择一个实例为 token server,其它两个为 token client:
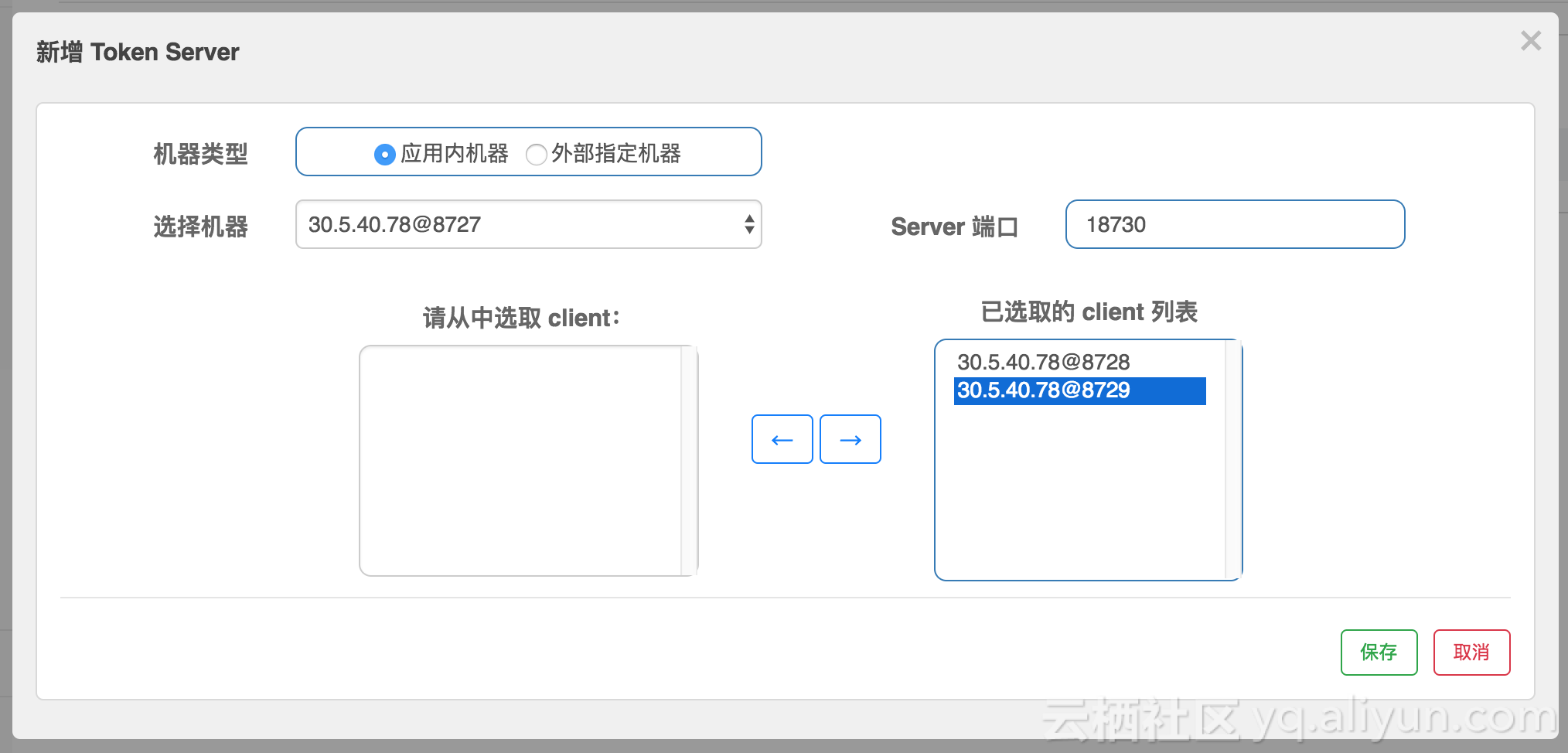
页面上机器的显示方式为 ip@commandPort,其中 commandPort 为应用端暴露给 Sentinel 控制台的端口。选择好以后,点击 保存 按钮,刷新页面即可以看到 token server 分配成功:
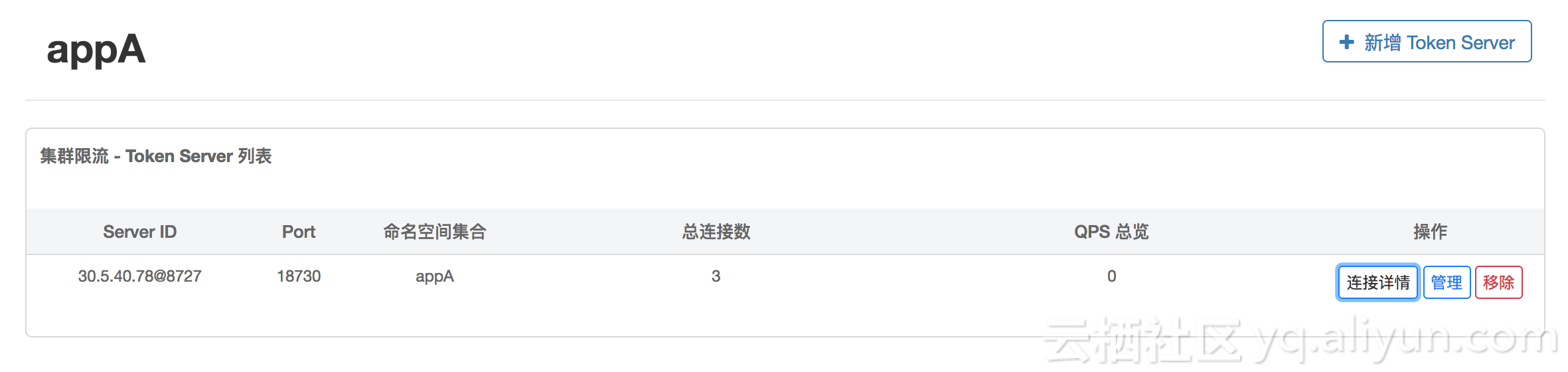
并且我们可以在页面查看 token server 的连接情况:
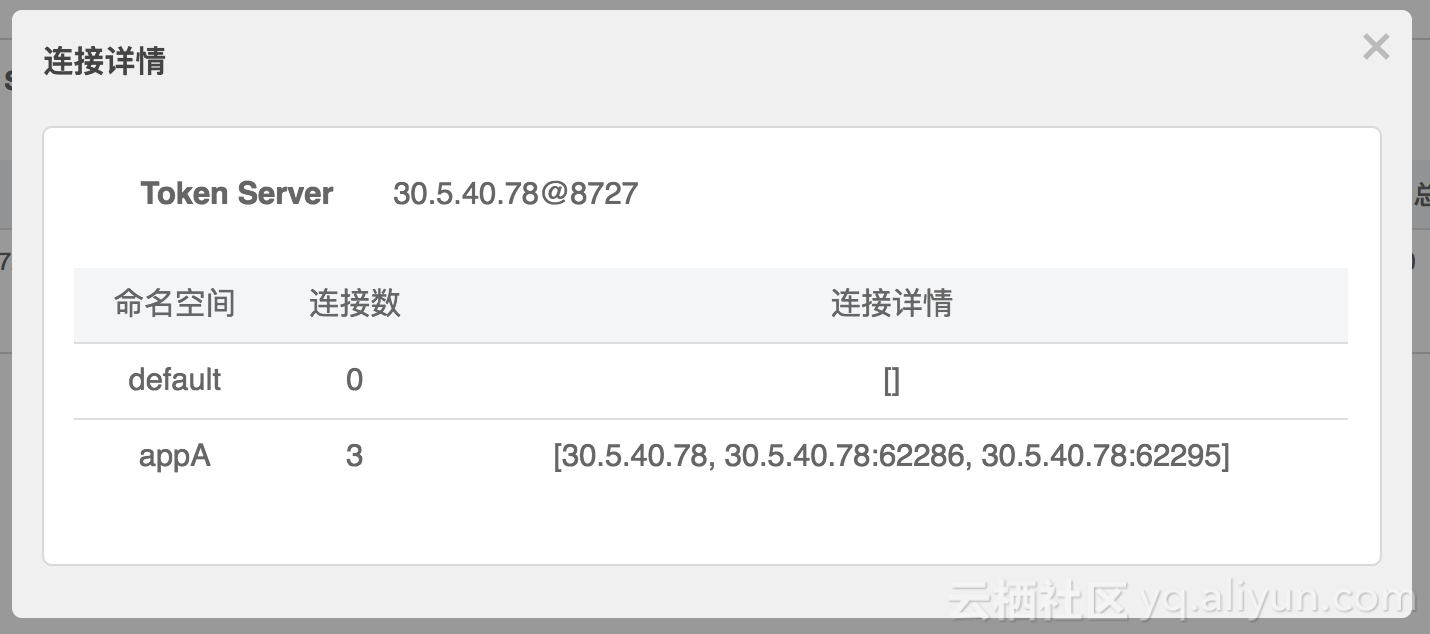
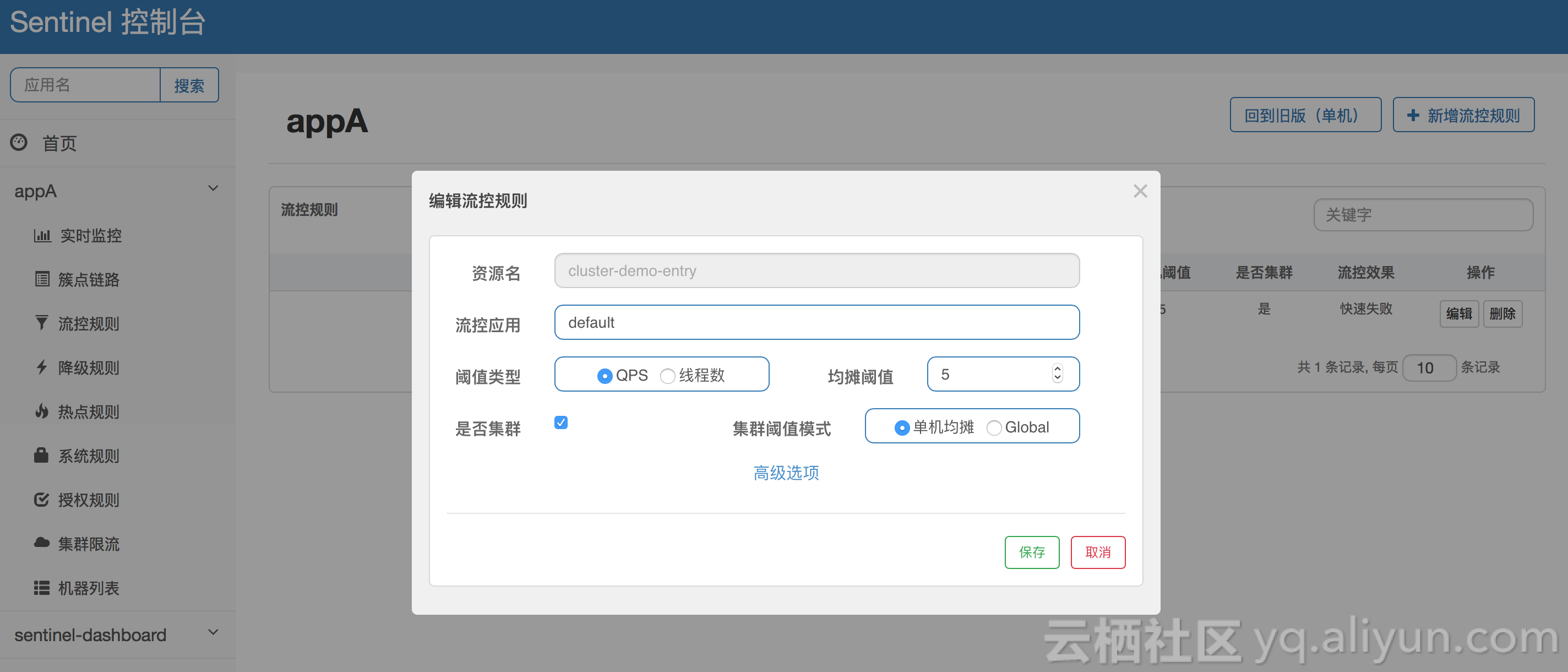
(5)配置规则,观察效果
接下来我们配置一条集群限流规则,限制 com.alibaba.csp.sentinel.demo.cluster.app.service.DemoService:sayHello(java.lang.String) 资源的集群总 QPS 为 10,选中“是否集群”选项,阈值模式选择总体阈值:
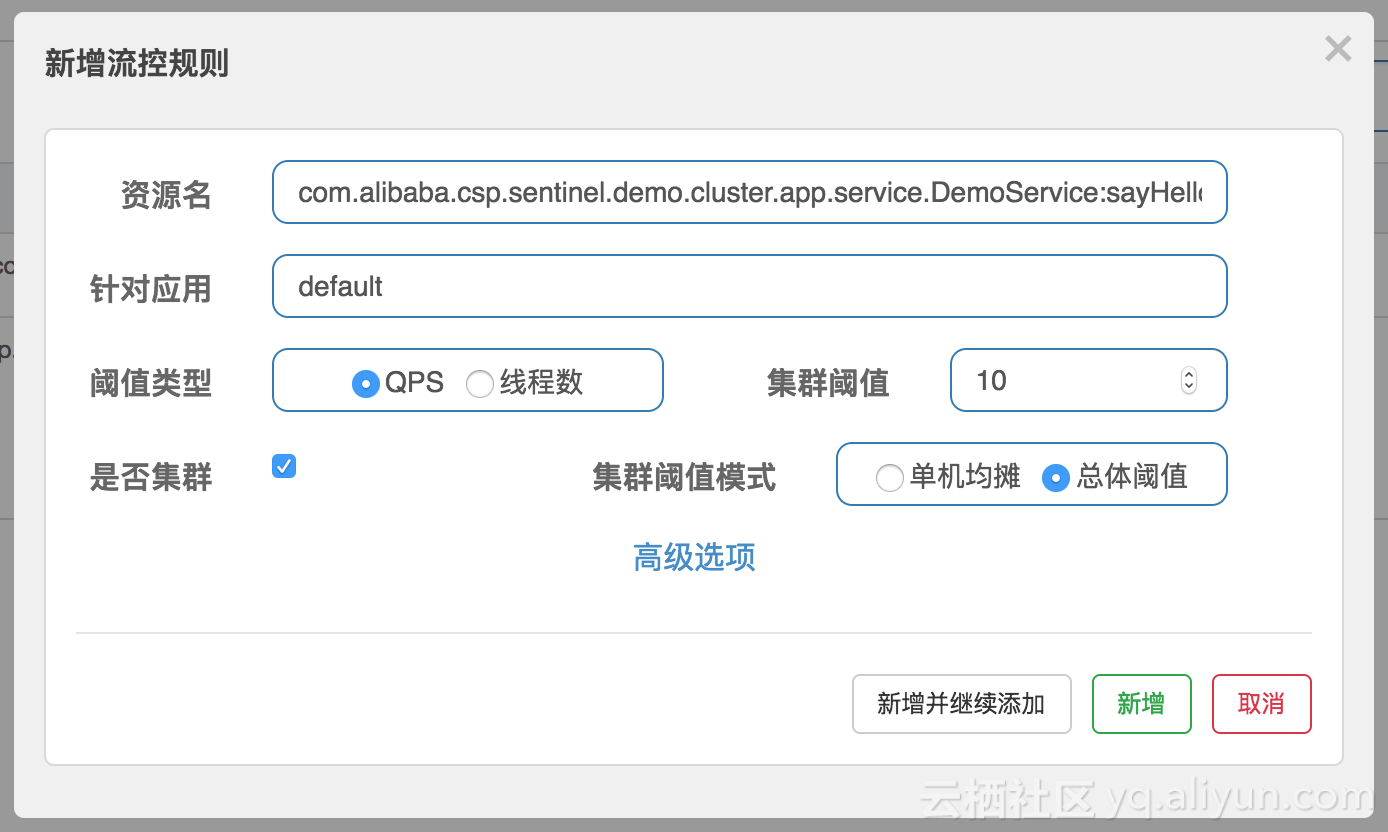
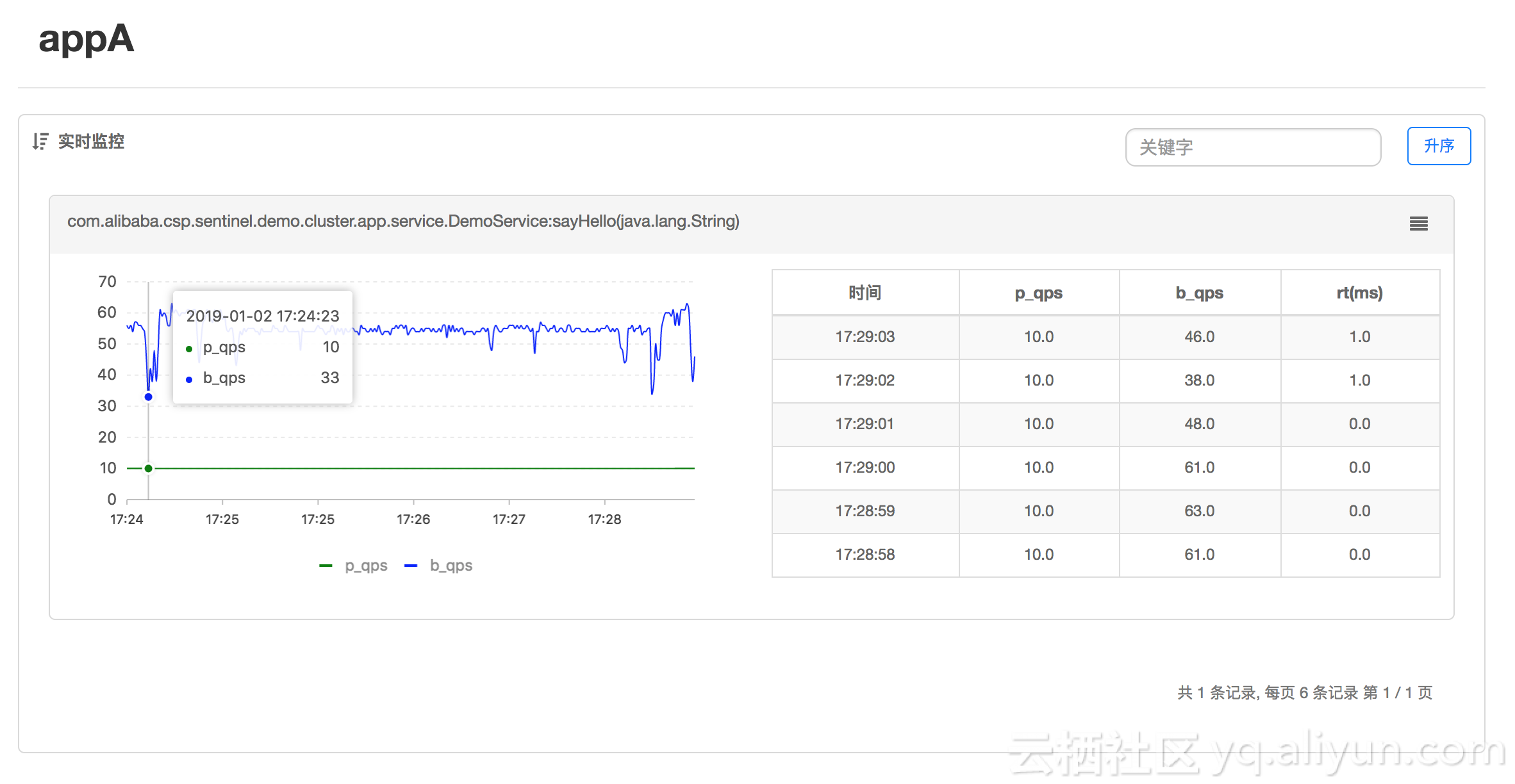
模拟流量同时请求这三台机器,过一段时间后观察效果。可以在监控页面看到对应资源的集群维度的总 QPS 稳定在 10:
总结
集群流控能够精确地控制整个集群的 QPS,结合单机限流兜底,可以更好地发挥流量控制的效果。还有更多的场景等待大家发掘,比如:
- 在 API Gateway 处统计某个 API 的总访问量,并对某个 API 或服务的总 QPS 进行限制
- Service Mesh 中对服务间的调用进行全局流控
- 集群内对热点商品的总访问频次进行限制
尽管集群流控比较好用,但它不是万能的,只有在确实有必要的场景下才推荐使用集群流控。
另外若在生产环境使用集群限流,管控端还需要关注以下的问题:
- Token Server 自动管理(分配/选举 Token Server)
- Token Server 高可用,在某个 server 不可用时自动 failover 到其它机器
未来我们还计划实现集群流控多语言版本的客户端,并对接 Service Mesh,让 Sentinel 集群流控可以在更多场景下使用。
Sentinel 发布里程碑版本,添加集群流控功能的更多相关文章
- sentinel 集群流控原理
为什么需要集群流控呢?假设需要将某个API的总qps限制在100,机器数可能为50,这时很自然的想到使用一个专门的server来统计总的调用量,其他实例与该server通信来判断是否可以调用,这就是基 ...
- Sentinel 1.7.0 发布,支持 Envoy 集群流量控制
流控降级中间件Sentinel 1.7.0版本正式发布,引入了 Envoy 集群流量控制支持.properties 文件配置.Consul/Etcd/Spring Cloud Config 动态数据源 ...
- Mongo 3.6.1版本Sharding集群配置
Mongo低版本和高版本的sharding集群配置,细节不太一样.目前网上的配置文档大都是针对低版本的.本人在配置3.6.1版本的mongosharding集群的过程中,碰到不少问题,官方文档没有直观 ...
- 宝塔面板 + Rancher + 阿里云镜像仓库 + Docker + Kubernetes,添加集群、部署 web 应用
目录 一,安装宝塔面板(V 6.8) 二,使用宝塔安装 Docker,配置阿里云容器服务 三,安装 Rancher (Server) 四,管理 Rancher.添加集群 五,添加 Rancher 应用 ...
- 『NiFi 节点本地流与集群流不一致导致集群加入失败』问题解决
一.概述 在某些极端情况下,某些 NiFi 节点信息会由于用户强行 disconnect from cluster ,而出现 local flow 与 cluster 的 flow 不同步的问题. 此 ...
- Quartz.NET 3.0.7 + MySql 实现动态调度作业+动态切换版本+多作业引用同一程序集不同版本+持久化+集群(一)
原文:Quartz.NET 3.0.7 + MySql 实现动态调度作业+动态切换版本+多作业引用同一程序集不同版本+持久化+集群(一) 前端时间,接到领导任务,写了一个调度框架.今天决定把心路历程记 ...
- db2 数据库配置HADR+TSA添加集群节点
Db2配置HADR高可用+TSA添加集群节点 一.服务器资源 Master IP:10.78.10.1 数据库:dbclassSlave IP:10.78.10.2 数据库:dbclassVIP:10 ...
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
使用Docker Compose部署基于Sentinel的高可用Redis集群 https://yq.aliyun.com/articles/57953 Docker系列之(五):使用Docker C ...
- rancher 添加集群
用rancher的管理账户登录rancher控制台首先创建用户 jinzs,后面用户绑定到要添加的集群上的 其次点全局,出现集群列表 >点添加集群 这里集群名称任意,只要你知道,该名称要对应实际 ...
随机推荐
- Python实现二叉堆
Python实现二叉堆 二叉堆是一种特殊的堆,二叉堆是完全二元树(二叉树)或者是近似完全二元树(二叉树).二叉堆有两种:最大堆和最小堆.最大堆:父结点的键值总是大于或等于任何一个子节点的键值:最小堆: ...
- sql实现查询某个字段在哪个表里 及结构是什么
) --数据库名 ) set @dbname2='aab' select @str = ' SELECT 表名=d.name,字段名=a.name,序号=a.column_id, 标识=is_iden ...
- 解决centos7没有显示ipv4的问题
很多小伙伴再安装centos7的时候,都是一直默认安装.所以导致后来没有ipv4 那么到底什么原因呢,我最近找到了原因: 就是在这里没有选择: 将这个地方打开之后,就会有了,那么问题就是那个原因.如果 ...
- HTTP协议:响应消息
一.请求消息:客户端发送给服务器端的数据 数据格式: 1.请求行 2.请求头 3.请求空行 4.请求体 二.响应消息:服务器端发送给客户的数据 数据格式: 1.响应行: 1.组成:协议/版本 响应状态 ...
- spring MVC 全局的异常处理
1.使用SimpleMappingExceptionResolver实现异常处理 在Spring的配置文件applicationContext.xml中增加以下内容: <bean class=& ...
- Spark应用程序
- SpringBoot防止重复请求,重复表单提交超级简单的注解实现
1. 注解接口 /** * @description 防止表单重复提交注解 */@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.METHO ...
- 【JZOJ6271】锻造 (forging)
description analysis 首先看一下\(p=1\),即\(1\)以后的合成一定成功的情况 如果按照求期望值的一般做法求两把\(0\)合成\(1\)的期望,会画出一棵无穷大的树 这个的期 ...
- 校园商铺-2Logback配置与使用-2Logback配置
logback配置文件加载顺序 logback:程序在运行的时候,会按照一定的顺序去加载logbook相关的配置文件. 如果我们在配置里面制定了logbackConfigurationFile这个属性 ...
- exit与return的区别
===========================PHP的解释=========================================================== return ...