zookeeper入门之介绍与安装
一:zookeeper是什么
What is ZooKeeper?
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
有道中文翻译:ZooKeeper是一个集中的服务,用于维护配置信息、命名、提供分布式同步和提供组服务。所有这些服务都以某种形式由分布式应用程序使用。每次实现它们时,都需要做大量工作来修复不可避免的bug和竞争条件。由于难以实现这些服务,应用程序最初通常会节省这些服务,这使得它们在出现更改时变得脆弱,并且难以管理,即使处理正确,这些服务的不同实现在部署应用程序时也会导致管理复杂性。
看图:
1.1节点
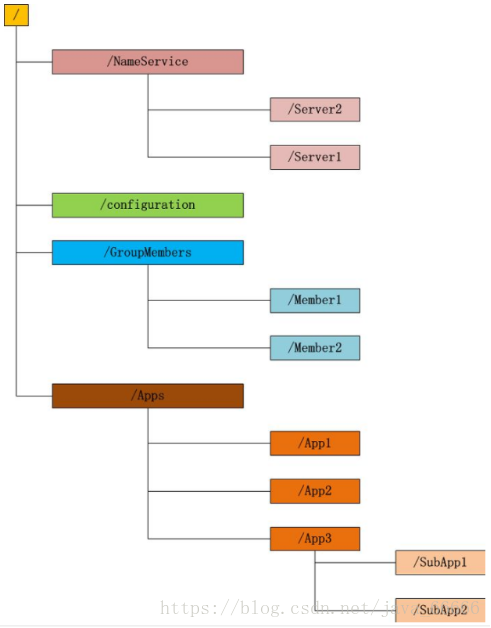
每个子目录项如 NameService 都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
1.2、 监听通知机制(watch机制)
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
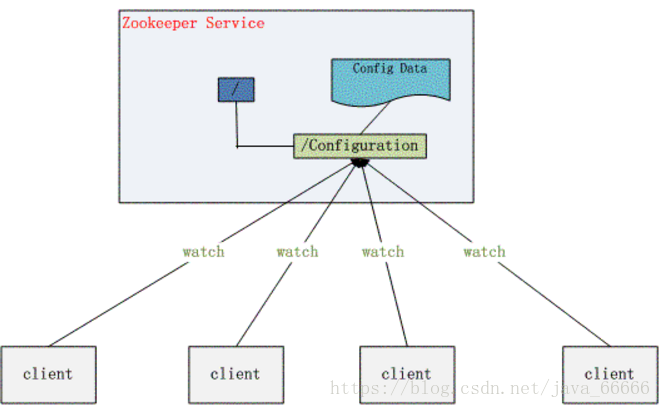
1.3总结之说人话:zookeeper=文件系统+监听通知机制
二:能做什么
zookeeper功能非常强大,可以实现诸如分布式应用配置管理、统一命名服务、状态同步服务、集群管理等功能,我们这里拿比较简单的分布式应用配置管理为例来说明。
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
三.下载及配置
解压好了之后,进入conf文件夹,会发现有2个文件,log4j.properties和zoo_sample.cfg这2个文件。对于zoo_sample.cfg文件,需要先将文件名字修改成zoo.cfg文件才行,接下来修改里面配置,如下所示,给出了注释和简单的配置信息。

1 # ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。
2 tickTime=2000
3
4 # Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作。
5 initLimit=10
6
7 # 在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。
8 syncLimit=5
9
10 # 存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。
11 dataDir=D:/Program Service Files/zookeeper-3.5.0-alpha/data
12
13 # 事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。
14 dataLogDir=D:/Program Service Files/zookeeper-3.5.0-alpha/dataLog
15
16 # 客户端连接server的端口,即对外服务端口,一般设置为2181吧。
17 clientPort=2181
18
19 # 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。
20 #maxClientCnxns=60
21
22 #
23 # Be sure to read the maintenance section of the
24 # administrator guide before turning on autopurge.
25 #
26 # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
27 #
28 # The number of snapshots to retain in dataDir
29 #autopurge.snapRetainCount=3
30 # Purge task interval in hours
31 # Set to "0" to disable auto purge feature
32 #autopurge.purgeInterval=1 配置详解:
1:tickTime:心跳时间,为了确保连接存在的,以毫秒为单位,最小超时时间为两个心跳时间
2:initLimit:多少个心跳时间内,允许其他server连接并初始化数据,如果ZooKeeper管理的数据较大,则应相应增大这个值
3:clientPort:服务的监听端口
4:dataDir:用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里(注意:一个配置文件只能包含一个dataDir字样,即使它被注释掉了。)
5:dataLogDir:用于单独设置transaction log的目录,transaction log分离可以避免和普通log还有快照的竞争
6:syncLimit:多少个tickTime内,允许follower同步,如果follower落后太多,则会被丢弃。
7:server.A=B:C:D:
A是一个数字,表示这个是第几号服务器,B是这个服务器的ip地址
C第一个端口用来集群成员的信息交换,表示的是这个服务器与集群中的Leader服务器交换信息的端口
D是在leader挂掉时专门用来进行选举leader所用
zookeeper入门之介绍与安装的更多相关文章
- Jenkins入门,介绍、安装
一.介绍 Jenkins: 三.安装 Jenkins: 第一种方式: 下载 windows 版本:进入 Jenkins 官网:https://jenkins.io/ 进入下 ...
- mycat入门_介绍与安装
利用闲暇时间接触了下mycat. 一.介绍 1.概述: 国内最活跃的.性能最好的开源数据库中间件,可以理解为数据库和应用层之间的一个代理组件. 2.作用: 读写分离.分表分库.主从切换. 3.原理: ...
- MongoDB入门(介绍、安装)
一.什么是MongoDB? MongoDB is a document database with the scalability and flexibility that you want with ...
- Vue.js 学习入门:介绍及安装
Vue.js 是什么? Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层 ...
- zookeeper介绍以及安装配置
Zookeeper启动时默认将Zookeeper.out输出到当前目录,不友好.改变位置有两种方法: 1:在当前用户下~/.bash_profile或在/etc/profile,添加ZOO_LOG_D ...
- Elasticsearch(es)介绍与安装
### RabbitMQ从入门到集群架构: https://zhuanlan.zhihu.com/p/375157411 可靠性高 ### Kafka从入门到精通: https://zhuanlan. ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- Python介绍、安装、使用
Python介绍.安装.使用 搬运工:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Python语言介绍 说到Python语言,就不得不说一下它的创始人Guido van Rossu ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
随机推荐
- win10创建本地用户
win+r,输入lusrmgr.msc win+i
- 抛弃VMware吧,使用Win10自带的Hyper-V创建虚拟机
个人博客 地址:https://www.wenhaofan.com/article/20190619221449 介绍 Hyper-V是微软提出的一种系统管理程序虚拟化技术,能够实现桌面虚拟化. 启动 ...
- 2020年Java 成长路线-flag
一.基础篇 JVM JVM内存结构 堆.栈.方法区.直接内存.堆和栈区别 Java内存模型 内存可见性.重排序.顺序一致性.volatile.锁.final 垃圾回收 内存分配策略.垃圾收集器(G1) ...
- 双向链表的简单Java实现-sunziren
写在前面,csdn的那篇同名博客就是我写的,我把它现在在这边重新发布,因为我实在不想用csdn了,那边的广告太多了,还有就是那个恶心人的“阅读更多”按钮,惹不起我躲得起. 在上次分享完单向链表的简单编 ...
- stringstream使用小结
1.头文件:#include<sstream> 2.stringstream是C++提供的串流(stream)物件 3.clear()重置流的标志状态:str()清空流的内存缓冲,重复使用 ...
- 谈一谈php反序列化
1.序列化与反序列化 php中有两个函数serialize()和unserialize() 序列化serialize(): 当在php中创建了一个对象后,可以通过serialize()把这个对象转变成 ...
- springMVC三大组件、spring主要jar包、
一.springMVC三大组件 处理器映射器 RequestMappingHandlerMapping 处理器适配器 RequestMappingHandlerAdapter 视图解析器 Int ...
- 订阅消息---由于微信小程序取消模板消息,限只能开发订阅消息
订阅消息开发步骤: 1.小程序管理后台添加订阅消息的模板 2.小程序前端编写调用(拉起)订阅授权 wx.requestSubscribeMessage({ tmplIds: ['34fwe1211xx ...
- ELK学习实验015:日志的自定义index配置
前面使用json格式收集了nginx的日志,但是再index的显示是filebeat-*,现在使用自定义的index进行配置 但是再使用filebeat的7.4版本以后,有一个巨坑,就是按照网络的很多 ...
- 基于EFCore3.0+Dapper 封装Repository
Wei.Repository 基于EFCore3.0+Dapper 封装Repository,实现UnitOfWork,提供基本的CURD操作,可直接注入泛型Repository,也可以继承Repos ...