第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了。
然后进入虚拟环境创建一个scrapy工程:
(third_project) bigni@bigni:~/python_file/python_project/pachong$ scr
scrapy screendump script scriptreplay
(third_project) bigni@bigni:~/python_file/python_project/pachong$ scrapy startproject ArticleSpider
New Scrapy project 'ArticleSpider', using template directory '/home/bigni/.virtualenvs/third_project/lib/python3.5/site-packages/scrapy/templates/project', created in:
/home/bigni/python_file/python_project/pachong/ArticleSpider You can start your first spider with:
cd ArticleSpider
scrapy genspider example example.com
(third_project) bigni@bigni:~/python_file/python_project/pachong$
我用pycharm进入创建好的scrapy项目,这个目录结构比较简单,而且有些地方很像Django

Spiders文件夹:我们可以在Spiders文件夹下编写我们的爬虫文件,里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。__init__.py:项目的初始化文件。
items.py:通过文件的注释我们了解到这个文件的作用是定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py:Spider中间件,在这个文件里我们可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。
pipelines.py:在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py:提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。
创建爬虫模板:
好比在Django中创建一个APP,在次创建一个爬虫
命令:
#注意:必须在该工程目录下
#创建一个名字为blogbole,爬取root地址为blog.jobbole.com 的爬虫;爬伯乐在线
scrapy genspider jobbole blog.jobbole.com
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy genspider jobbole blog.jobbole.com
Created spider 'jobbole' using template 'basic' in module:
ArticleSpider.spiders.jobbole
然后可以在spiders里看到新生成的文件jobbole.py

jobbole.py的内容如下:
# -*- coding: utf-8 -*-
import scrapy class JobboleSpider(scrapy.Spider):
# 爬虫名字
name = 'jobbole'
# 运行爬取的域名
allowed_domains = ['blog.jobbole.com']
# 开始爬取的URL
start_urls = ['http://blog.jobbole.com/'] # 爬取函数
def parse(self, response):
pass
在终端上执行 :scrapy crawl jobbole 测试下,其中jobbole是spidername
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$ scrapy crawl jobbole
2017-08-27 22:24:21 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: ArticleSpider)
2017-08-27 22:24:21 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'ArticleSpider', 'NEWSPIDER_MODULE': 'ArticleSpider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['ArticleSpider.spiders']}
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.telnet.TelnetConsole']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-08-27 22:24:21 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-08-27 22:24:21 [scrapy.core.engine] INFO: Spider opened
2017-08-27 22:24:21 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-08-27 22:24:21 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-08-27 22:24:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/robots.txt> (referer: None)
2017-08-27 22:24:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/> (referer: None)
2017-08-27 22:24:26 [scrapy.core.engine] INFO: Closing spider (finished)
2017-08-27 22:24:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 438,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 22537,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 8, 27, 14, 24, 26, 588459),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'memusage/max': 50860032,
'memusage/startup': 50860032,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 8, 27, 14, 24, 21, 136475)}
2017-08-27 22:24:26 [scrapy.core.engine] INFO: Spider closed (finished)
(third_project) bigni@bigni:~/python_file/python_project/pachong/ArticleSpider/ArticleSpider$
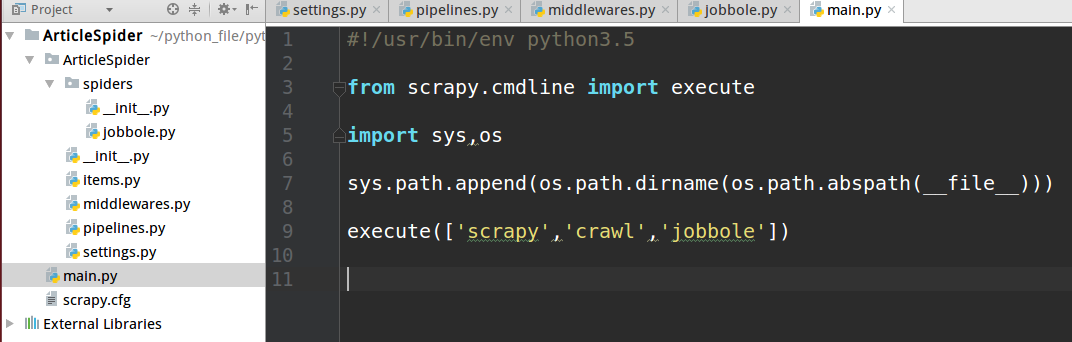
在pycharm 调试scrapy 执行流程,在项目里创建一个python文件,把项目路径写进sys.path,调用execute方法,传个数组,效果和上面在终端运行效果一样
PS:setting配置文件里建议把robotstxt协议停掉,否则scrapy会过滤某些url
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
第五篇 scrapy安装及目录结构,启动spider项目的更多相关文章
- 02、Scrapy 安装、目录结构及启动
1.从豆瓣源去快速安装Scrapy开发环境 C:\Users\licl11092>pip install -i https://pypi.douban.com/simple/ scrapy 2. ...
- vuejs目录结构启动项目安装nodejs命令,api配置信息思维导图版
vuejs目录结构启动项目安装nodejs命令,api配置信息思维导图版 vuejs技术交流QQ群:458915921 有兴趣的可以加入 vuejs 目录结构 build build.js check ...
- 02_Weblogic课程之安装篇:RedHat下JDK安装,RedHat下Weblogic安装,目录结构,环境变量设置
1 Weblogic的安装方式有三种: 一.GUI方式安装 (java –jar wls1035_generic.jar [-mode=gui])这是默认的 二.Console方式安装 ...
- Scrapy基础(二)————Scrapy的安装和目录结构
Scrapy安装: 1,首先进入虚拟环境 2,使用国内豆瓣源进行安装,快! pip install -i https://pypi.douban.com/simple/ scrapy 3,特殊情 ...
- ant design pro(一)安装、目录结构、项目加载启动【原始、以及idea开发】
一.概述 1.1.脚手架概念 编程领域中的“脚手架(Scaffolding)”指的是能够快速搭建项目“骨架”的一类工具.例如大多数的React项目都有src,public,webpack配置文件等等, ...
- 001-ant design pro安装、目录结构、项目加载启动【原始、以及idea开发】
一.概述 1.1.脚手架概念 编程领域中的“脚手架(Scaffolding)”指的是能够快速搭建项目“骨架”的一类工具.例如大多数的React项目都有src,public,webpack配置文件等等, ...
- Maven进价:Maven的安装和目录结构
一.在windows上安装Maven 1.下载 下载地址:http://maven.apache.org/download.html 下载最新版本 maven3.2.5 2.解压 解压地址:F:\Ja ...
- linux下mysql安装、目录结构、配置
1.准备安装程序(官方网站下载) 服务端:MySQL-server-community-5.1.44-1.rhel4.i386.rpm 客户端:MySQL-client-community-5.1.4 ...
- DedeCMS安装及目录结构
一.安装DedeCMS 1.下载DedeCMS安装包,我下载的版本是DedeCMS-V5.7-UTF8-SP1.tar.gz 官方下载地址 2.解压DedeCMS-V5.7-UTF8-SP1.tar. ...
随机推荐
- CSRF如何防御
总结网上所说,细细的归纳下 CSRF利用的时网站对用户网页浏览器的信任.在受害人不知情的情况下以 受害人的名义伪造请求发送给攻击者的站点. 1.首先XSS漏洞先防护好(一般是通过过滤器更改特殊字符) ...
- js基本函数和基本方法
日期时间函数(需要用变量调用): var b = new Date(); //获取当前时间 b.getTime() //获取时间戳 b.getFullYear() //获取年份 b.getMonth( ...
- 关于java使用json不能够使用报没有导包的问题,以及前后台交互json数据的使用
博客搬迁,给你带来的不便,敬请谅解! http://www.suanliutudousi.com/2017/12/02/%e5%85%b3%e4%ba%8ejava%e4%bd%bf%e7%94%a8 ...
- Spring Enable高级应用及原理
Enable* 之前的文章用到了一些Enable*开头的注解,比如EnableAsync.EnableScheduling.EnableAspectJAutoProxy.EnableCaching等, ...
- 数据结构与算法简记--redis有序集合实现-跳跃表
跳表 定义 为一个值有序的链表建立多级索引,比如每2个节点提取一个节点到上一级,我们把抽出来的那一级叫做索引或索引层.如下图所示,其中down表示down指针,指向下一级节点.以此类推,对于节点数为n ...
- ivew Upload 上传图片组件
1. 先展示一个效果图 2.代码详解 <!-- 封面缩略图 --> <div class="pop-up-div pic"> <div class=& ...
- Python之元组、列表and 字典
序列: 元组和字符串都是不可变的哦 你看,数据空间不一样了 元组的话,你可以联想到C里面的结构体变量啊,为了包容不同的数据类型: 也可以这样取值哦: 列表:列表是可修改的哦~ 不然数据大了再另外开辟空 ...
- Spark和pyspark的配置安装
如何安装Spark和Pyspark构建Spark学习环境[MacOs] JDK环境 Python环境 Spark引擎 下载地址:Apache-Spark官网 MacOs下一般安装在/usr/local ...
- ORACLE PL、SQL编程
PL(Procedural Language)过程化的编程语言,是在SQL的基础上增加的部分,如:变量的使用.流程控制等, 重点学习Oracle和MySQL创建存储过程及流程控制的异同. 一.存储过程 ...
- Web开发进阶
1.可靠性 可扩展性,服务降级,负载均衡 应用扩展 1.垂直扩展,方式:提升机器硬件,缺点,成本昂贵,扩展能力有限 2.水平扩展,方式:增加节点,优点:升级过程平花,硬件成本低,理论上无线扩展,确 ...