Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html
一、简介
1.1 概述
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如机器学习、图计算等,对流数据进行处理。
Spark Streaming处理的数据流图:

Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。

Spark Streaming为这种持续的数据流提供了的一个高级抽象,即:discretized stream(离散数据流)或者叫DStream。DStream既可以从输入数据源创建得来,如:Kafka、Flume或者Kinesis,也可以从其他DStream经一些算子操作得到。其实在内部,一个DStream就是包含了一系列RDDs。
本文档将向你展示如何用DStream进行Spark Streaming编程。Spark Streaming支持Scala、Java和Python(始于Spark 1.2),本文档的示例包括这三种语言。
注意:对Python来说,有一部分API尚不支持,或者是和Scala、Java不同。本文档中会用高亮形式来注明这部分 Python API。
1.2 一个小栗子
在深入Spark Streaming编程细节之前,我们先来看看一个简单的小栗子以便有个感性认识。假设我们在一个TCP端口上监听一个数据服务器的数据,并对收到的文本数据中的单词计数。以下你所需的全部工作:
首先,我们需要导入Spark Streaming的相关class的一些包,以及一些支持StreamingContext隐式转换的包(这些隐式转换能给DStream之类的class增加一些有用的方法)。StreamingContext 是Spark Streaming的入口。我们将会创建一个本地 StreamingContext对象,包含两个执行线程,并将批次间隔设为1秒。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // 从Spark 1.3之后这行就可以不需要了 // 创建一个local StreamingContext,包含2个工作线程,并将批次间隔设为1秒
// master至少需要2个CPU核,以避免出现任务饿死的情况
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds())
利用这个上下文对象(StreamingContext),我们可以创建一个DStream,该DStream代表从前面的TCP数据源流入的数据流,同时TCP数据源是由主机名(如:hostnam)和端口(如:9999)来描述的。
// 创建一个连接到hostname:port的DStream,如:localhost:9999
val lines = ssc.socketTextStream("localhost", )
这里的 lines 就是从数据server接收到的数据流。其中每一条记录都是一行文本。接下来,我们就需要把这些文本行按空格分割成单词。
// 将每一行分割成多个单词
val words = lines.flatMap(_.split(" "))
flatMap 是一种 “一到多”(one-to-many)的映射算子,它可以将源DStream中每一条记录映射成多条记录,从而产生一个新的DStream对象。在本例中,lines中的每一行都会被flatMap映射为多个单词,从而生成新的words DStream对象。然后,我们就能对这些单词进行计数了。
import org.apache.spark.streaming.StreamingContext._ // Spark 1.3之后不再需要这行
// 对每一批次中的单词进行计数
val pairs = words.map(word => (word, ))
val wordCounts = pairs.reduceByKey(_ + _) // 将该DStream产生的RDD的头十个元素打印到控制台上
wordCounts.print()
words这个DStream对象经过map算子(一到一的映射)转换为一个包含(word, 1)键值对的DStream对象pairs,再对pairs使用reduce算子,得到每个批次中各个单词的出现频率。最后,wordCounts.print() 将会每秒(前面设定的批次间隔)打印一些单词计数到控制台上。
注意,执行以上代码后,Spark Streaming只是将计算逻辑设置好,此时并未真正的开始处理数据。要启动之前的处理逻辑,我们还需要如下调用:
ssc.start() // 启动流式计算
ssc.awaitTermination() // 等待直到计算终止
完整的代码可以在Spark Streaming的例子 NetworkWordCount 中找到。
如果你已经有一个Spark包(下载在这里downloaded,自定义构建在这里built),就可以执行按如下步骤运行这个例子。
首先,你需要运行netcat(Unix-like系统都会有这个小工具),将其作为data server
$ nc -lk
然后,在另一个终端,按如下指令执行这个例子
$ ./bin/run-example streaming.NetworkWordCount localhost
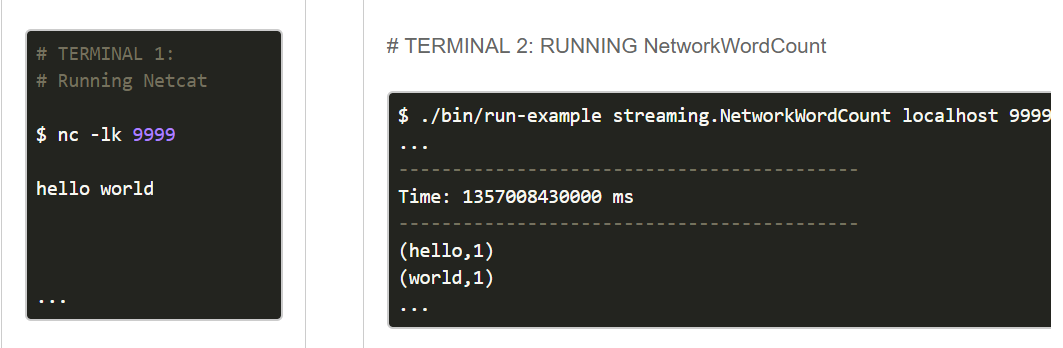
好了,现在你尝试可以在运行netcat的终端里敲几个单词,你会发现这些单词以及相应的计数会出现在启动Spark Streaming例子的终端屏幕上。看上去应该和下面这个示意图类似:
二、基本概念
下面,我们在之前的小栗子基础上,继续深入了解一下Spark Streaming的一些基本概念。
2.1 链接依赖项
和Spark类似,Spark Streaming也能在Maven库中找到。如果你需要编写Spark Streaming程序,你就需要将以下依赖加入到你的SBT或Maven工程依赖中。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.</artifactId>
<version>1.6.</version>
</dependency>
还有,对于从Kafka、Flume以及Kinesis这类数据源提取数据的流式应用来说,还需要额外增加相应的依赖项,下表列出了各种数据源对应的额外依赖项:
| 数据源 | Maven工件 |
|---|---|
| Kafka | spark-streaming-kafka_2.10 |
| Flume | spark-streaming-flume_2.10 |
| Kinesis | spark-streaming-kinesis-asl_2.10 [Amazon Software License] |
| spark-streaming-twitter_2.10 | |
| ZeroMQ | spark-streaming-zeromq_2.10 |
| MQTT | spark-streaming-mqtt_2.10 |
最新的依赖项信息(包括源代码和Maven工件)请参考Maven repository。
2.2 初始化StreamingContext
要初始化任何一个Spark Streaming程序,都需要在入口代码中创建一个StreamingContext对象。
A StreamingContext object can be created from a SparkConf object.
而StreamingContext对象需要一个SparkConf对象作为其构造参数。
import org.apache.spark._
import org.apache.spark.streaming._ val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds())
上面代码中的 appName 是你给该应用起的名字,这个名字会展示在Spark集群的web UI上。而 master 是Spark, Mesos or YARN cluster URL,如果支持本地测试,你也可以用”local[*]”为其赋值。通常在实际工作中,你不应该将master参数硬编码到代码里,而是应用通过spark-submit的参数来传递master的值(launch the application with spark-submit )。不过对本地测试来说,”local[*]”足够了(该值传给master后,Spark Streaming将在本地进程中,启动n个线程运行,n与本地系统CPU core数相同)。注意,StreamingContext在内部会创建一个 SparkContext 对象(SparkContext是所有Spark应用的入口,在StreamingContext对象中可以这样访问:ssc.sparkContext)。
StreamingContext还有另一个构造参数,即:批次间隔,这个值的大小需要根据应用的具体需求和可用的集群资源来确定。详见Spark性能调优( Performance Tuning)。
StreamingContext对象也可以通过已有的SparkContext对象来创建,示例如下:
import org.apache.spark.streaming._ val sc = ... // 已有的SparkContext
val ssc = new StreamingContext(sc, Seconds())
context对象创建后,你还需要如下步骤:
- 创建DStream对象,并定义好输入数据源。
- 基于数据源DStream定义好计算逻辑和输出。
- 调用streamingContext.start() 启动接收并处理数据。
- 调用streamingContext.awaitTermination() 等待流式处理结束(不管是手动结束,还是发生异常错误)
- 你可以主动调用 streamingContext.stop() 来手动停止处理流程。
需要关注的重点:
- 一旦streamingContext启动,就不能再对其计算逻辑进行添加或修改。
- 一旦streamingContext被stop掉,就不能restart。
- 单个JVM虚机同一时间只能包含一个active的StreamingContext。
- StreamingContext.stop() 也会把关联的SparkContext对象stop掉,如果不想把SparkContext对象也stop掉,可以将StreamingContext.stop的可选参数 stopSparkContext 设为false。
- 一个SparkContext对象可以和多个StreamingContext对象关联,只要先对前一个StreamingContext.stop(sparkContext=false),然后再创建新的StreamingContext对象即可。
2.3 离散数据流 (DStreams)
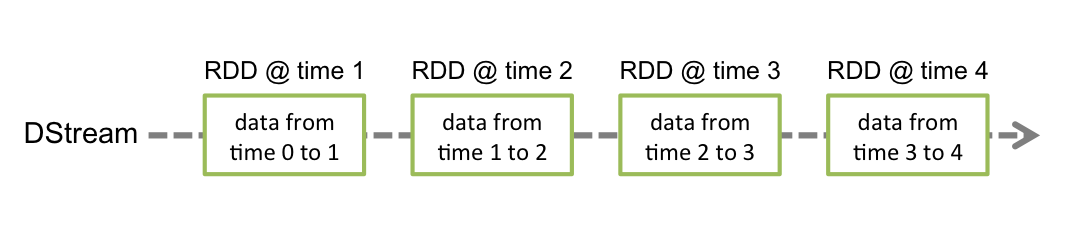
离散数据流(DStream)是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连续的RDD组成的,每个RDD都是不可变、分布式的数据集(详见Spark编程指南 – Spark Programming Guide)。每个RDD都包含了特定时间间隔内的一批数据,如下图所示:
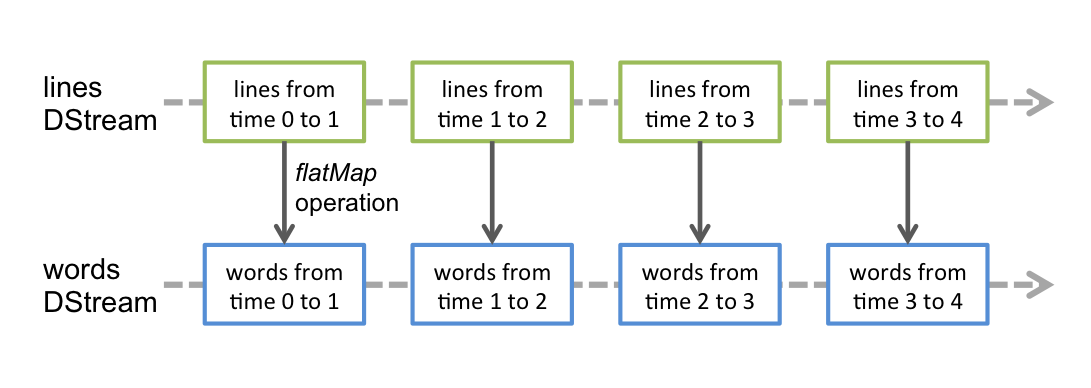
任何作用于DStream的算子,其实都会被转化为对其内部RDD的操作。例如,在前面的例子中,我们将 lines 这个DStream转成words DStream对象,其实作用于lines上的flatMap算子,会施加于lines中的每个RDD上,并生成新的对应的RDD,而这些新生成的RDD对象就组成了words这个DStream对象。其过程如下图所示:
底层的RDD转换仍然是由Spark引擎来计算。DStream的算子将这些细节隐藏了起来,并为开发者提供了更为方便的高级API。后续会详细讨论这些高级算子。
2.4 输入DStream和接收器
输入DStream代表从某种流式数据源流入的数据流。在之前的例子里,lines 对象就是输入DStream,它代表从netcat server收到的数据流。每个输入DStream(除文件数据流外)都和一个接收器(Receiver – Scala doc, Java doc)相关联,而接收器则是专门从数据源拉取数据到内存中的对象。
Spark Streaming主要提供两种内建的流式数据源:
- 基础数据源(Basic sources): 在StreamingContext API 中可直接使用的源,如:文件系统,套接字连接或者Akka actor。
- 高级数据源(Advanced sources): 需要依赖额外工具类的源,如:Kafka、Flume、Kinesis、Twitter等数据源。这些数据源都需要增加额外的依赖,详见依赖链接(linking)这一节。
本节中,我们将会从每种数据源中挑几个继续深入讨论。
注意,如果你需要同时从多个数据源拉取数据,那么你就需要创建多个DStream对象(详见后续的性能调优这一小节)。多个DStream对象其实也就同时创建了多个数据流接收器。但是请注意,Spark的worker/executor 都是长期运行的,因此它们都会各自占用一个分配给Spark Streaming应用的CPU。所以,在运行Spark Streaming应用的时候,需要注意分配足够的CPU core(本地运行时,需要足够的线程)来处理接收到的数据,同时还要足够的CPU core来运行这些接收器。
要点
- 如果本地运行Spark Streaming应用,记得不能将master设为”local” 或 “local[1]”。这两个值都只会在本地启动一个线程。而如果此时你使用一个包含接收器(如:套接字、Kafka、Flume等)的输入DStream,那么这一个线程只能用于运行这个接收器,而处理数据的逻辑就没有线程来执行了。因此,本地运行时,一定要将master设为”local[n]”,其中 n > 接收器的个数(有关master的详情请参考Spark Properties)。
- 将Spark Streaming应用置于集群中运行时,同样,分配给该应用的CPU core数必须大于接收器的总数。否则,该应用就只会接收数据,而不会处理数据。
基础数据源
前面的小栗子中,我们已经看到,使用ssc.socketTextStream(…) 可以从一个TCP连接中接收文本数据。而除了TCP套接字外,StreamingContext API 还支持从文件或者Akka actor中拉取数据。
文件数据流(File Streams): 可以从任何兼容HDFS API(包括:HDFS、S3、NFS等)的文件系统,创建方式如下:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
Spark Streaming将监视该dataDirectory目录,并处理该目录下任何新建的文件(目前还不支持嵌套目录)。注意:
- 各个文件数据格式必须一致。
- dataDirectory中的文件必须通过moving或者renaming来创建。
- 一旦文件move进dataDirectory之后,就不能再改动。所以如果这个文件后续还有写入,这些新写入的数据不会被读取。
对于简单的文本文件,更简单的方式是调用 streamingContext.textFileStream(dataDirectory)。
另外,文件数据流不是基于接收器的,所以不需要为其单独分配一个CPU core。
Python API fileStream目前暂时不可用,Python目前只支持textFileStream。
- 基于自定义Actor的数据流(Streams based on Custom Actors): DStream可以由Akka actor创建得到,只需调用 streamingContext.actorStream(actorProps, actor-name)。详见自定义接收器(Custom Receiver Guide)。actorStream暂时不支持Python API。
- RDD队列数据流(Queue of RDDs as a Stream): 如果需要测试Spark Streaming应用,你可以创建一个基于一批RDD的DStream对象,只需调用 streamingContext.queueStream(queueOfRDDs)。RDD会被一个个依次推入队列,而DStream则会依次以数据流形式处理这些RDD的数据。
关于套接字、文件以及Akka actor数据流更详细信息,请参考相关文档:StreamingContext for Scala,JavaStreamingContext for Java, and StreamingContext for Python。
高级数据源
Python API 自 Spark 1.6.1 起,Kafka、Kinesis、Flume和MQTT这些数据源将支持Python。
使用这类数据源需要依赖一些额外的代码库,有些依赖还挺复杂的(如:Kafka、Flume)。因此为了减少依赖项版本冲突问题,各个数据源DStream的相关功能被分割到不同的代码包中,只有用到的时候才需要链接打包进来。例如,如果你需要使用Twitter的tweets作为数据源,你需要以下步骤:
- Linking: 将spark-streaming-twitter_2.10工件加入到SBT/Maven项目依赖中。
- Programming: 导入TwitterUtils class,然后调用 TwitterUtils.createStream 创建一个DStream,具体代码见下放。
- Deploying: 生成一个uber Jar包,并包含其所有依赖项(包括 spark-streaming-twitter_2.10及其自身的依赖树),再部署这个Jar包。部署详情请参考部署这一节(Deploying section)。
import org.apache.spark.streaming.twitter._ TwitterUtils.createStream(ssc, None)
注意,高级数据源在spark-shell中不可用,因此不能用spark-shell来测试基于高级数据源的应用。如果真有需要的话,你需要自行下载相应数据源的Maven工件及其依赖项,并将这些Jar包部署到spark-shell的classpath中。
下面列举了一些高级数据源:
- Kafka: Spark Streaming 1.6.1 可兼容 Kafka 0.8.2.1。详见Kafka Integration Guide。
- Flume: Spark Streaming 1.6.1 可兼容 Flume 1.6.0 。详见Flume Integration Guide。
- Kinesis: Spark Streaming 1.6.1 可兼容 Kinesis Client Library 1.2.1。详见Kinesis Integration Guide。
- Twitter: Spark Streaming TwitterUtils 使用Twitter4j 通过 Twitter’s Streaming API 拉取公开tweets数据流。认证信息可以用任何Twitter4j所支持的方法(methods)。你可以获取所有的公开数据流,当然也可以基于某些关键词进行过滤。示例可以参考TwitterPopularTags 和 TwitterAlgebirdCMS。
自定义数据源
Python API 自定义数据源目前还不支持Python。
输入DStream也可以用自定义的方式创建。你需要做的只是实现一个自定义的接收器(receiver),以便从自定义的数据源接收数据,然后将数据推入Spark中。详情请参考自定义接收器指南(Custom Receiver Guide)。
2.5 接收器可靠性
从可靠性角度来划分,大致有两种数据源。其中,像Kafka、Flume这样的数据源,它们支持对所传输的数据进行确认。系统收到这类可靠数据源过来的数据,然后发出确认信息,这样就能够确保任何失败情况下,都不会丢数据。因此我们可以将接收器也相应地分为两类:
- 可靠接收器(Reliable Receiver) – 可靠接收器会在成功接收并保存好Spark数据副本后,向可靠数据源发送确认信息。
- 不可靠接收器(Unreliable Receiver) – 不可靠接收器不会发送任何确认信息。不过这种接收器常用语于不支持确认的数据源,或者不想引入数据确认的复杂性的数据源。
自定义接收器指南(Custom Receiver Guide)中详细讨论了如何写一个可靠接收器。
三、DStream支持的transformation算子
和RDD类似,DStream也支持从输入DStream经过各种transformation算子映射成新的DStream。DStream支持很多RDD上常见的transformation算子,一些常用的见下表:
| Transformation算子 | 用途 |
|---|---|
| map(func) | 返回会一个新的DStream,并将源DStream中每个元素通过func映射为新的元素 |
| flatMap(func) | 和map类似,不过每个输入元素不再是映射为一个输出,而是映射为0到多个输出 |
| filter(func) | 返回一个新的DStream,并包含源DStream中被func选中(func返回true)的元素 |
| repartition(numPartitions) | 更改DStream的并行度(增加或减少分区数) |
| union(otherStream) | 返回新的DStream,包含源DStream和otherDStream元素的并集 |
| count() | 返回一个包含单元素RDDs的DStream,其中每个元素是源DStream中各个RDD中的元素个数 |
| reduce(func) | 返回一个包含单元素RDDs的DStream,其中每个元素是通过源RDD中各个RDD的元素经func(func输入两个参数并返回一个同类型结果数据)聚合得到的结果。func必须满足结合律,以便支持并行计算。 |
| countByValue() | 如果源DStream包含的元素类型为K,那么该算子返回新的DStream包含元素为(K, Long)键值对,其中K为源DStream各个元素,而Long为该元素出现的次数。 |
| reduceByKey(func, [numTasks]) | 如果源DStream 包含的元素为 (K, V) 键值对,则该算子返回一个新的也包含(K, V)键值对的DStream,其中V是由func聚合得到的。注意:默认情况下,该算子使用Spark的默认并发任务数(本地模式为2,集群模式下由spark.default.parallelism 决定)。你可以通过可选参数numTasks来指定并发任务个数。 |
| join(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中源DStream和otherDStream中每个K都对应一个 (K, (V, W))键值对元素。 |
| cogroup(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中每个元素类型为包含(K, Seq[V], Seq[W])的tuple。 |
| transform(func) | 返回一个新的DStream,其包含的RDD为源RDD经过func操作后得到的结果。利用该算子可以对DStream施加任意的操作。 |
| updateStateByKey(func) | 返回一个包含新”状态”的DStream。源DStream中每个key及其对应的values会作为func的输入,而func可以用于对每个key的“状态”数据作任意的更新操作。 |
下面我们会挑几个transformation算子深入讨论一下。
3.1 updateStateByKey算子
updateStateByKey 算子支持维护一个任意的状态。要实现这一点,只需要两步:
- 定义状态 – 状态数据可以是任意类型。
- 定义状态更新函数 – 定义好一个函数,其输入为数据流之前的状态和新的数据流数据,且可其更新步骤1中定义的输入数据流的状态。
在每一个批次数据到达后,Spark都会调用状态更新函数,来更新所有已有key(不管key是否存在于本批次中)的状态。如果状态更新函数返回None,则对应的键值对会被删除。
举例如下。假设你需要维护一个流式应用,统计数据流中每个单词的出现次数。这里将各个单词的出现次数这个整型数定义为状态。我们接下来定义状态更新函数如下:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // 将新的计数值和之前的状态值相加,得到新的计数值
Some(newCount)
}
该状态更新函数可以作用于一个包括(word, 1) 键值对的DStream上(见本文开头的小栗子)。
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
该状态更新函数会为每个单词调用一次,且相应的newValues是一个包含很多个”1″的数组(这些1来自于(word,1)键值对),而runningCount包含之前该单词的计数。本例的完整代码请参考 StatefulNetworkWordCount.scala。
注意,调用updateStateByKey前需要配置检查点目录,后续对此有详细的讨论,见检查点(checkpointing)这节。
3.2 transform算子
transform算子(及其变体transformWith)可以支持任意的RDD到RDD的映射操作。也就是说,你可以用tranform算子来包装任何DStream API所不支持的RDD算子。例如,将DStream每个批次中的RDD和另一个Dataset进行关联(join)操作,这个功能DStream API并没有直接支持。不过你可以用transform来实现这个功能,可见transform其实为DStream提供了非常强大的功能支持。比如说,你可以用事先算好的垃圾信息,对DStream进行实时过滤。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // 包含垃圾信息的RDD
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // 将DStream中的RDD和spamInfoRDD关联,并实时过滤垃圾数据
...
})
注意,这里transform包含的算子,其调用时间间隔和批次间隔是相同的。所以你可以基于时间改变对RDD的操作,如:在不同批次,调用不同的RDD算子,设置不同的RDD分区或者广播变量等。
3.3 基于窗口(window)的算子
Spark Streaming同样也提供基于时间窗口的计算,也就是说,你可以对某一个滑动时间窗内的数据施加特定tranformation算子。如下图所示:
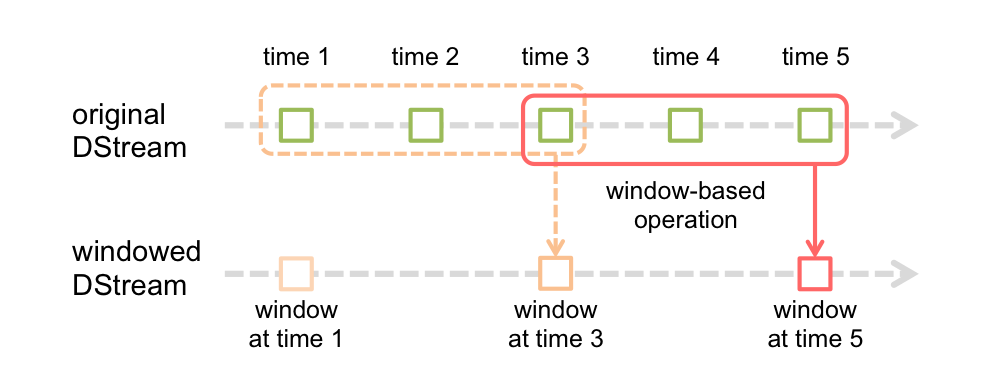
如上图所示,每次窗口滑动时,源DStream中落入窗口的RDDs就会被合并成新的windowed DStream。在上图的例子中,这个操作会施加于3个RDD单元,而滑动距离是2个RDD单元。由此可以得出任何窗口相关操作都需要指定一下两个参数:
- (窗口长度)window length – 窗口覆盖的时间长度(上图中为3)
- (滑动距离)sliding interval – 窗口启动的时间间隔(上图中为2)
注意,这两个参数都必须是DStream批次间隔(上图中为1)的整数倍.
下面咱们举个栗子。假设,你需要扩展前面的那个小栗子,你需要每隔10秒统计一下前30秒内的单词计数。为此,我们需要在包含(word, 1)键值对的DStream上,对最近30秒的数据调用reduceByKey算子。不过这些都可以简单地用一个 reduceByKeyAndWindow搞定。
// 每隔10秒归约一次最近30秒的数据
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(), Seconds())
以下列出了常用的窗口算子。所有这些算子都有前面提到的那两个参数 – 窗口长度 和 滑动距离。
| Transformation窗口算子 | 用途 |
|---|---|
| window(windowLength, slideInterval) | 将源DStream窗口化,并返回转化后的DStream |
| countByWindow(windowLength,slideInterval) | 返回数据流在一个滑动窗口内的元素个数 |
| reduceByWindow(func, windowLength,slideInterval) | 基于数据流在一个滑动窗口内的元素,用func做聚合,返回一个单元素数据流。func必须满足结合律,以便支持并行计算。 |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | 基于(K, V)键值对DStream,将一个滑动窗口内的数据进行聚合,返回一个新的包含(K,V)键值对的DStream,其中每个value都是各个key经过func聚合后的结果。 注意:如果不指定numTasks,其值将使用Spark的默认并行任务数(本地模式下为2,集群模式下由 spark.default.parallelism决定)。当然,你也可以通过numTasks来指定任务个数。 |
| reduceByKeyAndWindow(func, invFunc,windowLength,slideInterval, [numTasks]) | 和前面的reduceByKeyAndWindow() 类似,只是这个版本会用之前滑动窗口计算结果,递增地计算每个窗口的归约结果。当新的数据进入窗口时,这些values会被输入func做归约计算,而这些数据离开窗口时,对应的这些values又会被输入 invFunc 做”反归约”计算。举个简单的例子,就是把新进入窗口数据中各个单词个数“增加”到各个单词统计结果上,同时把离开窗口数据中各个单词的统计个数从相应的统计结果中“减掉”。不过,你的自己定义好”反归约”函数,即:该算子不仅有归约函数(见参数func),还得有一个对应的”反归约”函数(见参数中的 invFunc)。和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。注意,这个算子需要配置好检查点(checkpointing)才能用。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于包含(K, V)键值对的DStream,返回新的包含(K, Long)键值对的DStream。其中的Long value都是滑动窗口内key出现次数的计数。 和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。 |
3.4 Join相关算子
最后,值得一提的是,你在Spark Streaming中做各种关联(join)操作非常简单。
流-流(Stream-stream)关联
一个数据流可以和另一个数据流直接关联。
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
上面代码中,stream1的每个批次中的RDD会和stream2相应批次中的RDD进行join。同样,你可以类似地使用 leftOuterJoin, rightOuterJoin, fullOuterJoin 等。此外,你还可以基于窗口来join不同的数据流,其实现也很简单,如下;)
val windowedStream1 = stream1.window(Seconds())
val windowedStream2 = stream2.window(Minutes())
val joinedStream = windowedStream1.join(windowedStream2)
流-数据集(stream-dataset)关联
其实这种情况已经在前面的DStream.transform算子中介绍过了,这里再举个基于滑动窗口的例子。
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds())...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
实际上,在上面代码里,你可以动态地该表join的数据集(dataset)。传给tranform算子的操作函数会在每个批次重新求值,所以每次该函数都会用最新的dataset值,所以不同批次间你可以改变dataset的值。
完整的DStream transformation算子列表见API文档。Scala请参考 DStream 和 PairDStreamFunctions. Java请参考 JavaDStream 和 JavaPairDStream. Python见 DStream。
四、DStream输出算子
输出算子可以将DStream的数据推送到外部系统,如:数据库或者文件系统。因为输出算子会将最终完成转换的数据输出到外部系统,因此只有输出算子调用时,才会真正触发DStream transformation算子的真正执行(这一点类似于RDD 的action算子)。目前所支持的输出算子如下表:
| 输出算子 | 用途 |
|---|---|
| print() | 在驱动器(driver)节点上打印DStream每个批次中的头十个元素。 Python API 对应的Python API为 pprint() |
| saveAsTextFiles(prefix, [suffix]) | 将DStream的内容保存到文本文件。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream内容以序列化Java对象的形式保存到顺序文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream内容保存到Hadoop文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| foreachRDD(func) | 这是最通用的输出算子了,该算子接收一个函数func,func将作用于DStream的每个RDD上。 func应该实现将每个RDD的数据推到外部系统中,比如:保存到文件或者写到数据库中。 注意,func函数是在streaming应用的驱动器进程中执行的,所以如果其中包含RDD的action算子,就会触发对DStream中RDDs的实际计算过程。 |
4.1 使用foreachRDD的设计模式
DStream.foreachRDD是一个非常强大的原生工具函数,用户可以基于此算子将DStream数据推送到外部系统中。不过用户需要了解如何正确而高效地使用这个工具。以下列举了一些常见的错误。
通常,对外部系统写入数据需要一些连接对象(如:远程server的TCP连接),以便发送数据给远程系统。因此,开发人员可能会不经意地在Spark驱动器(driver)进程中创建一个连接对象,然后又试图在Spark worker节点上使用这个连接。如下例所示:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // 这行在驱动器(driver)进程执行
rdd.foreach { record =>
connection.send(record) // 而这行将在worker节点上执行
}
}
这段代码是错误的,因为它需要把连接对象序列化,再从驱动器节点发送到worker节点。而这些连接对象通常都是不能跨节点(机器)传递的。比如,连接对象通常都不能序列化,或者在另一个进程中反序列化后再次初始化(连接对象通常都需要初始化,因此从驱动节点发到worker节点后可能需要重新初始化)等。解决此类错误的办法就是在worker节点上创建连接对象。
然而,有些开发人员可能会走到另一个极端 – 为每条记录都创建一个连接对象,例如:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
一般来说,连接对象是有时间和资源开销限制的。因此,对每条记录都进行一次连接对象的创建和销毁会增加很多不必要的开销,同时也大大减小了系统的吞吐量。一个比较好的解决方案是使用 rdd.foreachPartition – 为RDD的每个分区创建一个单独的连接对象,示例如下:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这样一来,连接对象的创建开销就摊到很多条记录上了。
最后,还有一个更优化的办法,就是在多个RDD批次之间复用连接对象。开发者可以维护一个静态连接池来保存连接对象,以便在不同批次的多个RDD之间共享同一组连接对象,示例如下:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool 是一个静态的、懒惰初始化的连接池
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // 将连接返还给连接池,以便后续复用之
}
}
注意,连接池中的连接应该是懒惰创建的,并且有确定的超时时间,超时后自动销毁。这个实现应该是目前发送数据最高效的实现方式。
其他要点:
- DStream的转化执行也是懒惰的,需要输出算子来触发,这一点和RDD的懒惰执行由action算子触发很类似。特别地,DStream输出算子中包含的RDD action算子会强制触发对所接收数据的处理。因此,如果你的Streaming应用中没有输出算子,或者你用了dstream.foreachRDD(func)却没有在func中调用RDD action算子,那么这个应用只会接收数据,而不会处理数据,接收到的数据最后只是被简单地丢弃掉了。
- 默认地,输出算子只能一次执行一个,且按照它们在应用程序代码中定义的顺序执行。
转自:https://yq.aliyun.com/articles/86239?spm=a2c4e.11153940.blogcont86244.110.4e80c973zadb30
Spark学习之路 (二十二)SparkStreaming的官方文档的更多相关文章
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- FastAPI 学习之路(十二)接口几个额外信息和额外数据类型
系列文章: FastAPI 学习之路(一)fastapi--高性能web开发框架 FastAPI 学习之路(二) FastAPI 学习之路(三) FastAPI 学习之路(四) FastAPI 学习之 ...
- Spark学习之路(十四)—— Spark Streaming 基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- Spark学习之路(十)—— Spark SQL 外部数据源
一.简介 1.1 多数据源支持 Spark支持以下六个核心数据源,同时Spark社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JDBC/ ...
- Spark学习之路 (十六)SparkCore的源码解读(二)spark-submit提交脚本
一.概述 上一篇主要是介绍了spark启动的一些脚本,这篇主要分析一下Spark源码中提交任务脚本的处理逻辑,从spark-submit一步步深入进去看看任务提交的整体流程,首先看一下整体的流程概要图 ...
随机推荐
- leetcode实践:通过链表存储两数之和
题目: 两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字.如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的 ...
- 了解java虚拟机—串行回收器(6)
串行回收器 串行回收器只有一个工作线程,串行回收器可以在新生代和老年代使用,根据作用于不同的堆和空间,分为新生代串行回收器和老年代串行回收器. 1.新生代串行回收器 串行收集器是所有垃圾回收器中最古老 ...
- springboot自定义banner生成器
http://patorjk.com/software/taag/#p=display&f=Graffiti&t=Type%20Something%20
- LINQ to Objects系列(4)表达式树
为了进一步加深对Lambda表达式的理解,我们需要掌握一个新的知识,Lambda表达式树,可能听名字看起来很高深和难以理解,但实际上理解起来并没有想象中那么难,这篇文章我想分以下几点进行总结. 1,表 ...
- 【10-2】复杂业务状态的处理(从状态者模式到FSM)
一.概述 我们平常在开发业务模块时,经常会遇到比较复杂的状态转换.比如说用户可能有新注册.实名认证中.已实名认证.禁用等状态,支付可能有等待支付.支付中.已支付等状态.OA系统里的状态处理就更多了. ...
- Maven构建的Spring项目需要哪些依赖?
Maven构建的Spring项目需要哪些依赖? <!-- Spring依赖 --> <!-- 1.Spring核心依赖 --> <dependency> <g ...
- thinkphp5+qrcode生成二维码
1.下载二维码插件Phpqrcode,地址 https://sourceforge.net/projects/phpqrcode/files/,把下载的文件夹放到\thinkphp\vendor下 2 ...
- layui table 行号
{type: 'numbers', title: '序号', width: '80'}
- linux下使用sublime-text写coffee遇到的编译问题
Traceback (most recent call last): File "/opt/sublime_text/sublime_plugin.py", line 556, i ...
- Fedora16的双显卡切换问题
症状:笔记本是Acer 4745G,安装了Fedora16+Win7 x64的双系统,每次开机后,独立显卡的风扇就开始狂转,同时笔记本的发热量极大,左侧出风口简直烫手.... 问题:Acer 4745 ...