9 个鲜为人知的 Python 数据科学库
除了 pandas、scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧。
Python 是一种令人惊叹的语言。事实上,它是世界上增长最快的编程语言之一。它一次又一次地证明了它在各个行业的开发者和数据科学者中的作用。Python 及其库的整个生态系统使其成为全世界用户的恰当选择,无论是初学者还是高级用户。它成功和受欢迎的原因之一是它的一组强大的库,使它如此动态和快速。
在本文中,我们将看到 Python 库中的一些数据科学工具,而不是那些常用的工具,如 pandas、scikit-learn 和 matplotlib。虽然像 pandas、scikit-learn 这样的库是机器学习中最常想到的,但是了解这个领域的其他 Python 库也是非常有帮助的。
Wget
提取数据,尤其是从网络中提取数据,是数据科学家的重要任务之一。Wget 是一个免费的工具,用于从网络上非交互式下载文件。它支持 HTTP、HTTPS 和 FTP 协议,以及通过 HTTP 代理进行访问。因为它是非交互式的,所以即使用户没有登录,它也可以在后台工作。所以下次你想下载一个网站或者网页上的所有图片,wget 会提供帮助。
安装:
$ pip install wget例子:
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532 filename 'razorback.mp3'钟摆
对于在 Python 中处理日期时间感到沮丧的人来说, Pendulum 库是很有帮助的。这是一个 Python 包,可以简化日期时间操作。它是 Python 原生类的一个替代品。有关详细信息,请参阅其文档。
安装:
$ pip install pendulum例子:
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
3不平衡学习
当每个类别中的样本数几乎相同(即平衡)时,大多数分类算法会工作得最好。但是现实生活中的案例中充满了不平衡的数据集,这可能会影响到机器学习算法的学习和后续预测。幸运的是,imbalanced-learn 库就是为了解决这个问题而创建的。它与 scikit-learn 兼容,并且是 scikit-learn-contrib 项目的一部分。下次遇到不平衡的数据集时,可以尝试一下。
安装:
pip install -U imbalanced-learn
# or
conda install -c conda-forge imbalanced-learn例子:
有关用法和示例,请参阅其文档 。
FlashText
在自然语言处理(NLP)任务中清理文本数据通常需要替换句子中的关键词或从句子中提取关键词。通常,这种操作可以用正则表达式来完成,但是如果要搜索的术语数达到数千个,它们可能会变得很麻烦。
Python 的 FlashText 模块,基于 FlashText 算法,为这种情况提供了一个合适的替代方案。FlashText 的最佳部分是运行时间与搜索项的数量无关。你可以在其 文档 中读到更多关于它的信息。
安装:
$ pip install flashtext例子:
提取关键词:
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']替代关键词:
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'有关更多示例,请参阅文档中的 用法 一节。
模糊处理
这个名字听起来很奇怪,但是 FuzzyWuzzy 在字符串匹配方面是一个非常有用的库。它可以很容易地实现字符串匹配率、令牌匹配率等操作。对于匹配保存在不同数据库中的记录也很方便。
安装:
$ pip install fuzzywuzzy例子:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 简单的匹配率
fuzz.ratio("this is a test", "this is a test!")
97
# 部分的匹配率
fuzz.partial_ratio("this is a test", "this is a test!")
100更多的例子可以在 FuzzyWuzy 的 GitHub 仓库得到。
PyFlux
时间序列分析是机器学习中最常遇到的问题之一。PyFlux 是 Python 中的开源库,专门为处理时间序列问题而构建的。该库拥有一系列优秀的现代时间序列模型,包括但不限于 ARIMA、GARCH 以及 VAR 模型。简而言之,PyFlux 为时间序列建模提供了一种概率方法。这值得一试。
安装:
pip install pyflux例子:
有关用法和示例,请参阅其 文档。
IPyvolume
交流结果是数据科学的一个重要方面,可视化结果提供了显著优势。 IPyvolume 是一个 Python 库,用于在 Jupyter 笔记本中可视化 3D 体积和形状(例如 3D 散点图),配置和工作量极小。然而,它目前处于 1.0 之前的阶段。一个很好的类比是这样的: IPyVolumee volshow 是 3D 阵列,Matplotlib 的 imshow 是 2D 阵列。你可以在其 文档 中读到更多关于它的信息。
安装:
Using pip
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume例子:
动画:
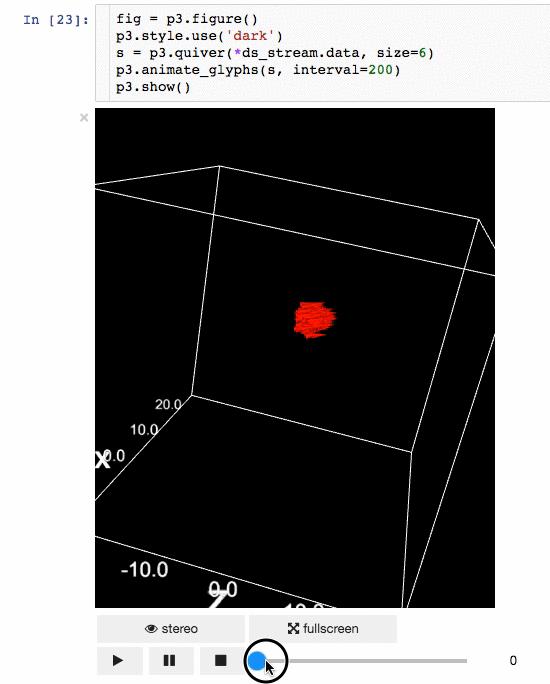
体绘制:
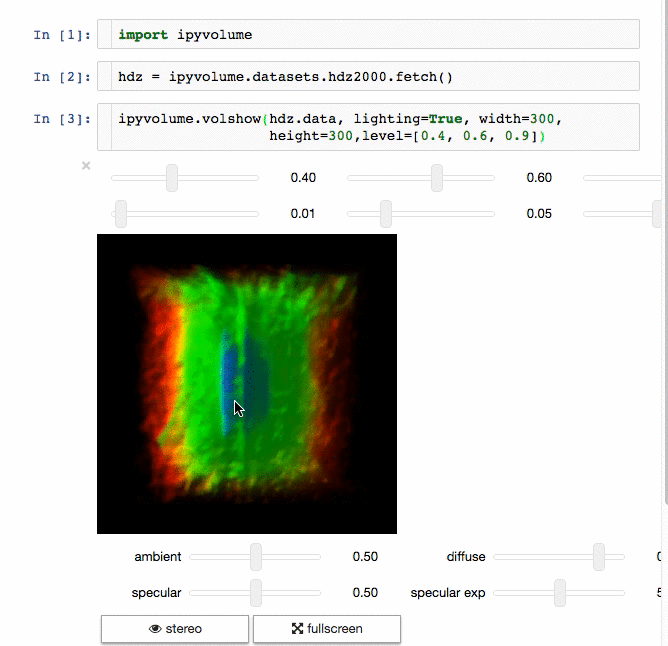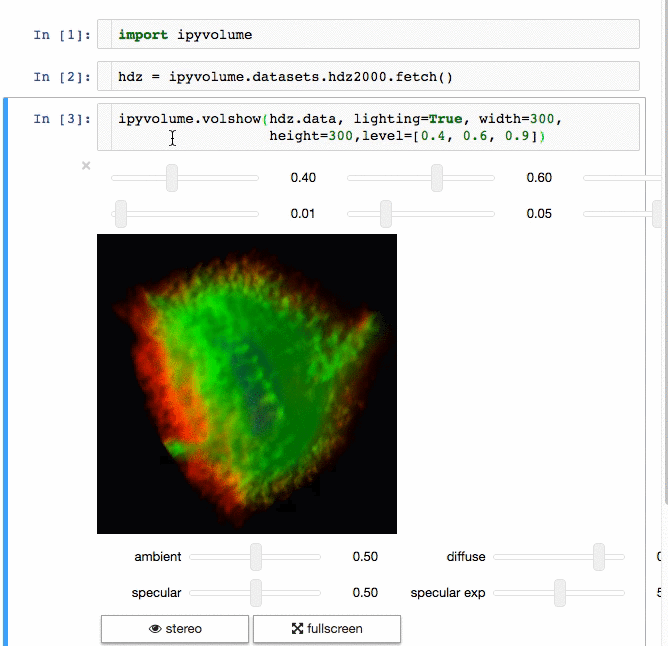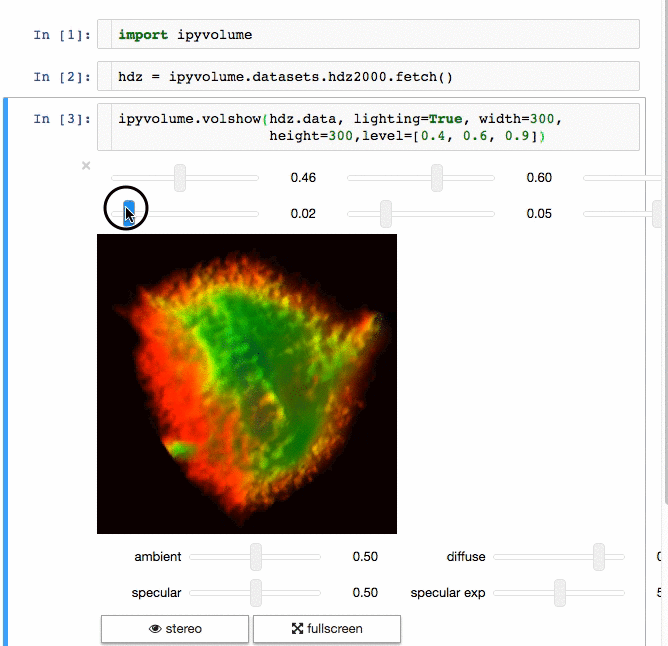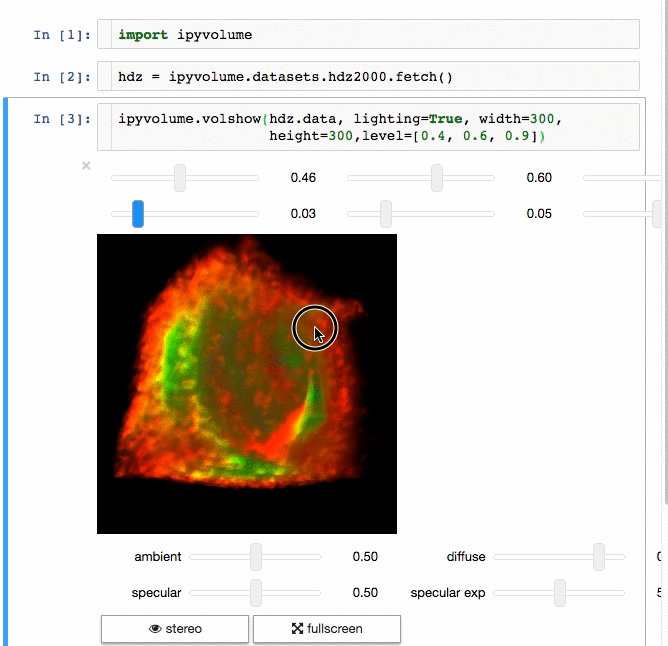
Dash
Dash 是一个用于构建 Web 应用程序的高效 Python 框架。它构建于 Flask、Plotty.js 和 Response.js 之上,将下拉菜单、滑块和图形等流行 UI 元素与你的 Python 分析代码联系起来,而不需要JavaScript。Dash 非常适合构建可在 Web 浏览器中呈现的数据可视化应用程序。有关详细信息,请参阅其 用户指南 。
安装:
pip install dash==0.29.0 # The core dash backend
pip install dash-html-components==0.13.2 # HTML components
pip install dash-core-components==0.36.0 # Supercharged components
pip install dash-table==3.1.3 # Interactive DataTable component (new!)例子:
下面的示例显示了一个具有下拉功能的高度交互的图表。当用户在下拉列表中选择一个值时,应用程序代码将数据从 Google Finance 动态导出到 Pandas 数据框架中。
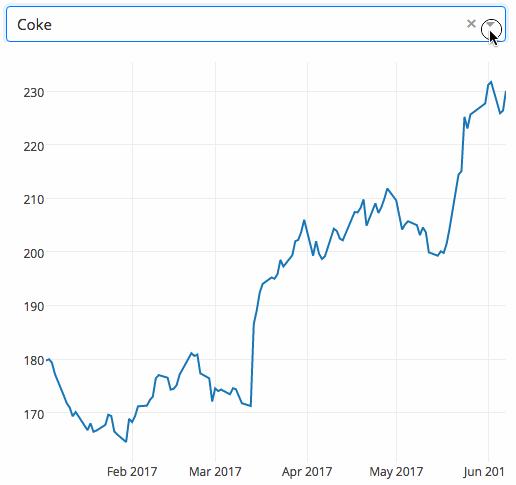
Gym
从 OpenAI 而来的 Gym 是开发和比较强化学习算法的工具包。它与任何数值计算库兼容,如 TensorFlow 或 Theano。Gym 是一个测试问题的集合,也称为“环境”,你可以用它来制定你的强化学习算法。这些环境有一个共享的接口,允许您编写通用算法。
安装:
pip install gym例子:
以下示例将在 CartPole-v0 环境中,运行 1000 次,在每一步渲染环境。
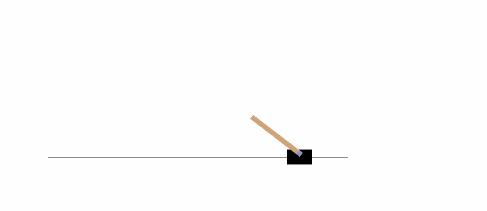
你可以在 Gym 网站上读到 其它的环境 。
结论
这些是我挑选的有用但鲜为人知的数据科学 Python 库。如果你知道另一个要添加到这个列表中,请在下面的评论中提及。
9 个鲜为人知的 Python 数据科学库的更多相关文章
- 20个最有用的Python数据科学库
核心库与统计 1. NumPy(提交:17911,贡献者:641) 一般我们会将科学领域的库作为清单打头,NumPy 是该领域的主要软件库之一.它旨在处理大型的多维数组和矩阵,并提供了很多高级的数学函 ...
- [python]-数据科学库Numpy学习
一.Numpy简介: Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.这样为了保存一个简单的[1,2,3],需要有3 ...
- python中令人惊艳的小众数据科学库
Python是门很神奇的语言,历经时间和实践检验,受到开发者和数据科学家一致好评,目前已经是全世界发展最好的编程语言之一.简单易用,完整而庞大的第三方库生态圈,使得Python成为编程小白和高级工程师 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- Python数据科学手册Seaborn马拉松可视化里时分秒转化为秒数的问题
Python数据科学手册Seaborn马拉松可视化里时分秒转化为秒数的问题 问题描述: 我实在是太懒了,问题描述抄的网上的哈哈哈:https://www.jianshu.com/p/6ab7afa05 ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
随机推荐
- spring中ApplicationContextAware接口描述
项目中使用了大量的工厂类,采用了简单工厂模式: 通过该工厂类可以获取指定的处理器bean,这些处理器bean我们是从spring容器中获取的,如何获取,是通过实现ApplicationContextA ...
- Percona XtraDB Cluster高可用与状态快照传输(PXC 5.7 )
Percona XtraDB Cluster(下称PXC)高可用集群支持任意节点在运行期间的重启,升级或者意外宕机,即它解决了单点故障问题.那在这个意外宕机或者重启期间,该节点丢失的数据如何再次进行同 ...
- mysql之 表数据存放路径非datadir目录
假如,新建一张表,并让该表的存储路径 不是默认的/path/to/datadir/dbname .而是 指定存储的位置 应该如何处理? 方法一shell> mkdir /Generalt1she ...
- js过滤输入的emoji表情
因为emoji表情是Unicode编码, 在某些流浪器上会显示乱码, 有的数据库字节不够也无法存储, 网上有很多解决此类问题的办法, 最简单的莫过于将emoji表情替换成文本, 比如 [表情][表情] ...
- egg 官方文档之:框架扩展(Application、Context、Request、Response、Helper的访问方式及扩展)
地址:https://eggjs.org/zh-cn/basics/extend.html Application app 对象指的是 Koa 的全局应用对象,全局只有一个,在应用启动时被创建. 访问 ...
- java zip 压缩文件
zip压缩:ZipOutputStream.ZipFile.ZipInputStream 三个类的作用 一段 java zip 压缩的代码: File dir = new File("C ...
- 读懂 PetaLinux:让 Linux 在 Zynq 上轻松起“跑”(转)
对于Zynq这样一个“ARM+可编程逻辑”异构处理系统我们已经不陌生,其创新性大家也有目共睹.不过想要让更多的应用享受到这一“创新”带来的红利,让其真正“落地”则需要大量系统性的工作,去营造一个完善的 ...
- JS 从HTML页面获取自定义属性值
<select id="nextType" data-parameter="@Model.NextType"> <option value=& ...
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
- Hiero的spreadsheet中添加tag属性列
Hiero在对剪辑线上的item进行管理的时候,往往会添加能多tag,而在管 理面板spreadsheet中却无法对tag进行查询,这是一件很麻烦的事,Hiero Development Guide中 ...