WEB 自动化思路
前期做了一个关键字驱动模型的WEB自动化项目,特意写文章归纳和总结下。
框架架构图
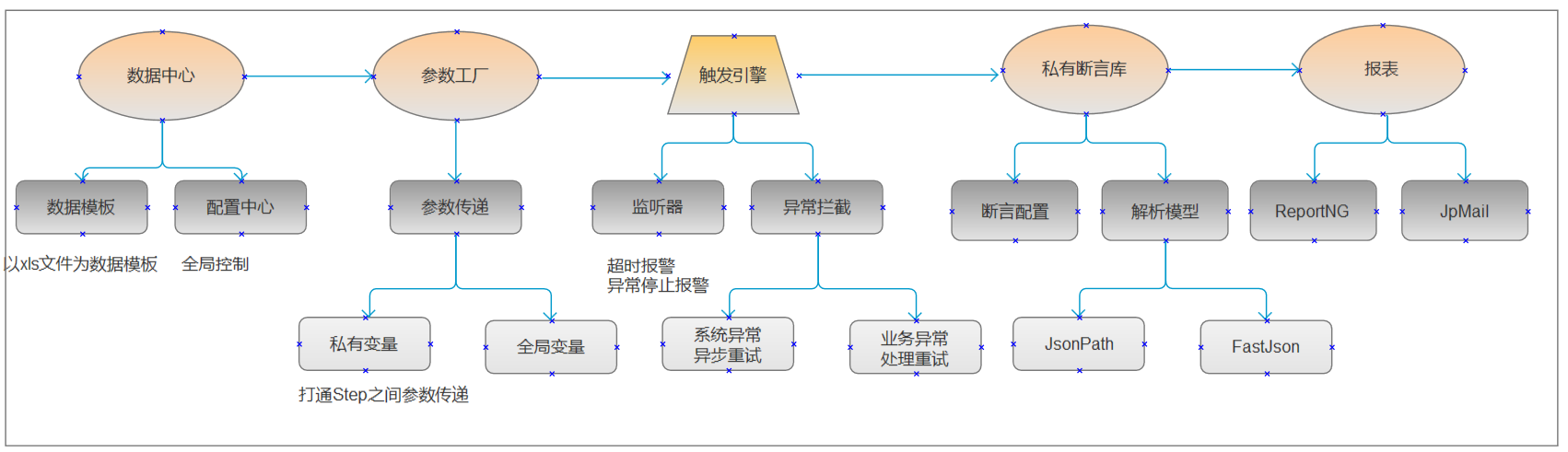
已经实现的部分:
1. 读写excel数据模板
2.配置中心,支持properties,xml格式的配置文件
3.参数传递没做,一般不建议在用例里面使用,比较麻烦。 不过添加了WEB页面 字符串和数值传递的方法
4. 设置了全局变量
5.监听器没做,错误重试在部分重要用例有做retry,提供了retry 方法
6. 断言有调用原生的Assert, 自己有封装了一些基本的验证方法。用例调用了TestNg
7. Json提供了多种方法,按照json层次访问数据; 遍历json; string转json , xml 转Json 等等
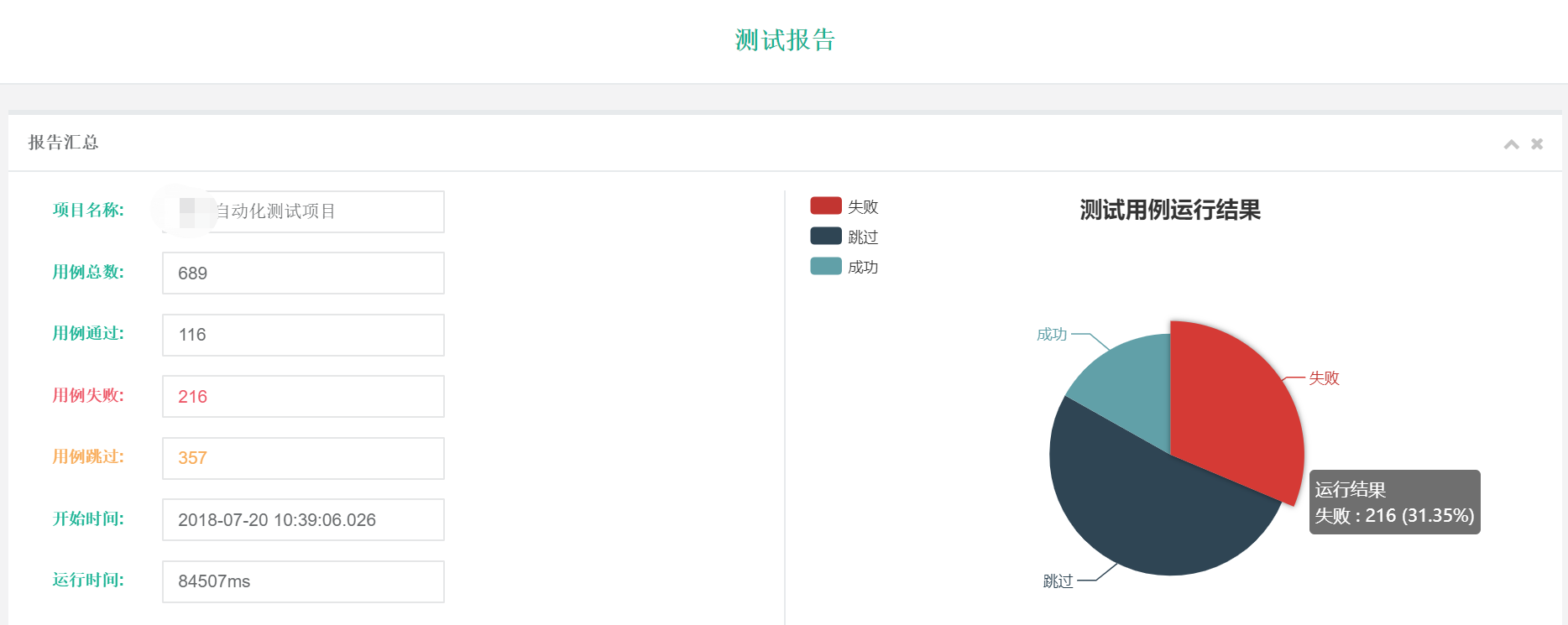
8. 测试报告采用的方法为: 定制一个Js 的模板template, 然后将testng中产生的数据传入到模板,再转换成html 。 报告中包含详细信息和汇总数据,这里要感谢张飞提供的原生Template
如图(以接口自动化测试报告为例,WEB自动化测试需要修改下详细数据的显示模式,归并步骤和通过结果等等,但是大体是可以沿用的):

框架介绍
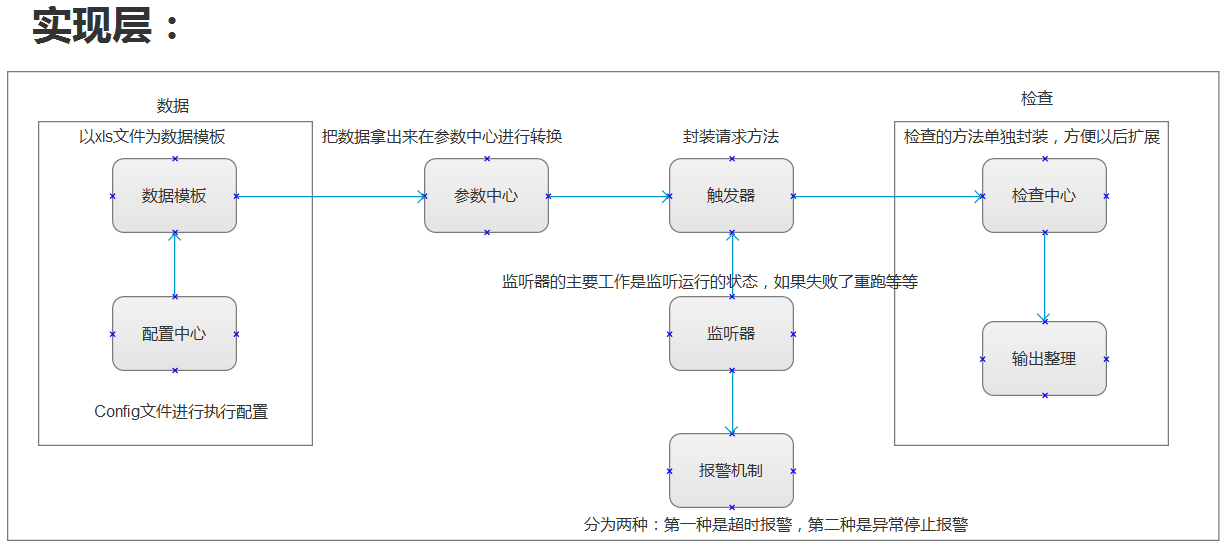
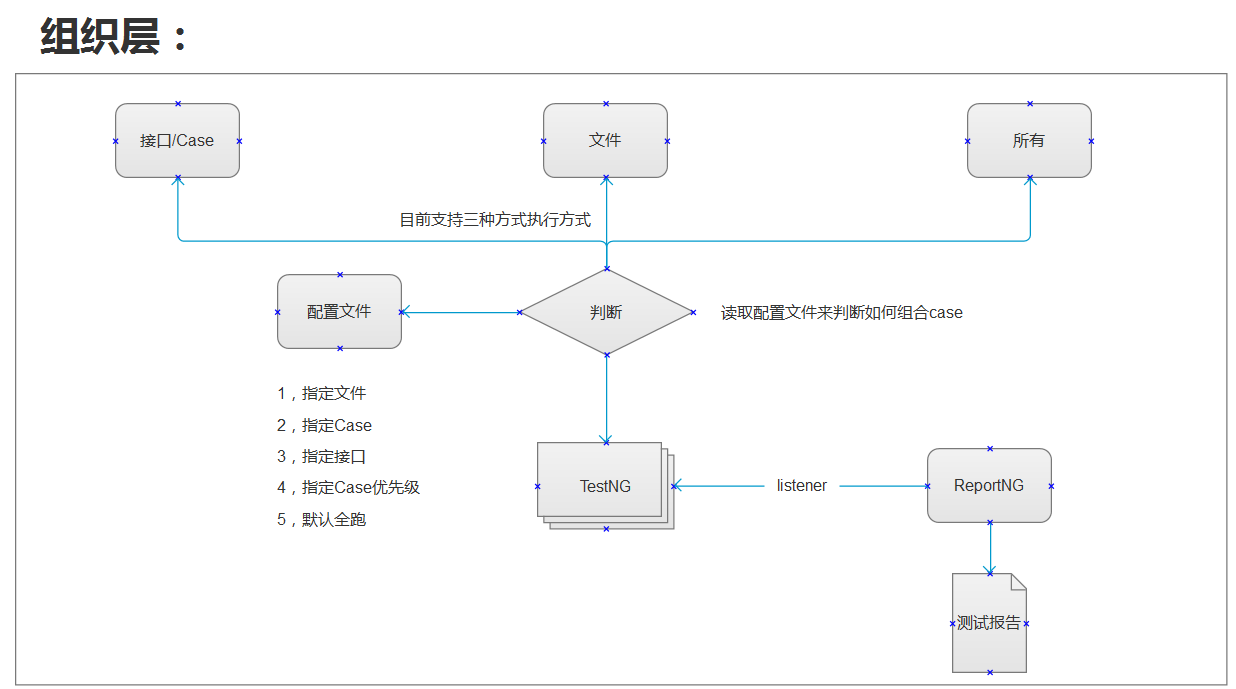
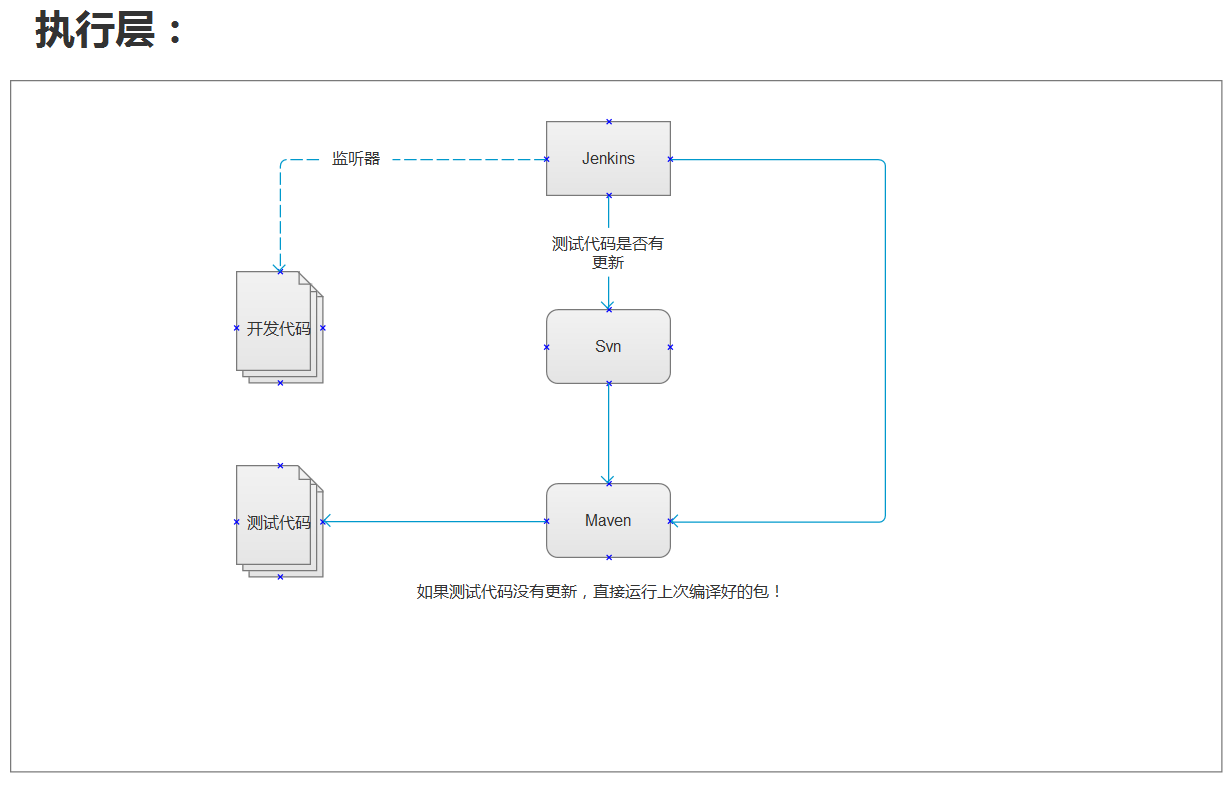
目前由于服务器没到位,执行层还未实现!
框架优势:
1 编写Case效率
易编写,在Excel内编写负责 粘贴非常简单方便,全局替换也非常方便。
易维护,无需每个人写代码脚本,在用例模板内可维护性高很多。
易交接,自动化模板基本都能看懂,思路一目了然。
2. 框架轻便灵活,无缝对接 持续集成,持续交付
3. 与TestNG +Maven+Jenkins 搭建持续集成链路,非常简单。
缺陷:
1. 一直想将页面元素与用例解耦,还没做,方案有:
a. 让测试人员将page element存储到另外一个excel,然后循环执行用例的时候去这个excel文件里面获取对应元素的定位信息。不过这无疑增加了IO消耗,
执行效率低下
b. 在程序里面设置一个xml文件来储存page element,然后写一个读取xml文件的方法来支撑用例运行
2. 开发的页面UI元素编写不规范,目前写用例和调试非常的困难。。。相信这也是大部分不成熟团队的疼点,只能通过和开发一直沟通规范了。
注: 文中的部分图片借用了 TesterHome 的 @testly (testly) 大大,我的思路和他类似~,但是不会画图。
WEB 自动化思路的更多相关文章
- Web自动化框架之五一套完整demo的点点滴滴(excel功能案例参数化+业务功能分层设计+mysql数据存储封装+截图+日志+测试报告+对接缺陷管理系统+自动编译部署环境+自动验证false、error案例)
标题很大,想说的很多,不知道从那开始~~直接步入正题吧 个人也是由于公司的人员的现状和项目的特殊情况,今年年中后开始折腾web自动化这块:整这个原因很简单,就是想能让自己偷点懒.也让减轻一点同事的苦力 ...
- Web自动化框架搭建——前言
1.web测试功能特性 a.功能逻辑测试(功能测试),这一块所有系统都是一致的,比如数据的添加.删除.修改:功能测试案例设计感兴趣和有时间的话可以另外专题探讨: b.浏览器兼容性测试,更重要的是体验这 ...
- Web自动化之Headless Chrome概览
Web自动化 这里所说的Web自动化是所有跟页面相关的自动化,比如页面爬取,数据抓取,页面内容检测,页面功能测试,页面加载性能测试,页面回归测试等等,当前主要由如下几种解决方式: 文本数据获取 这就是 ...
- 爬虫实战:爬虫之 web 自动化终极杀手 ( 上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:陈象 导语: 最近写了好几个简单的爬虫,踩了好几个深坑,在这里总结一下,给大家在编写爬虫时候能给点思路.本次爬虫内容有:静态页面的爬 ...
- Web自动化框架LazyUI使用手册(3)--单个xpath抓取插件详解(selenium元素抓取,有此插件,便再无所求!)
概述 前面的一篇博文粗略介绍了基于lazyUI的第一个demo,本文将详细描述此工具的设计和使用. 元素获取插件:LazyUI Elements Extractor,作为Chrome插件,用于抓取页面 ...
- WEB自动化(Python+selenium)的API
在做Web自动化过程中,汇总了Python+selenium的API相关方法,给公司里的同事做了第二次培训,分享给大家 ...
- web 自动化遇到 shadowDOM 节点你会操作吗?
本文转载自: http://www.lemfix.com/topics/971 近期有同学在做web自动化的时候,发现页面上有些元素,在selenium中无法通过xpath来定位,各种原因找了半天,都 ...
- Web自动化遇到shadowDOM节点操作(还没试)
近期有同学在做web自动化的时候,发现页面上有些元素,在selenium中无法通过xpath来定位,各种原因找了半天,都没找到解决方案. 最后发现元素在一个叫做shadow-root的节点下面. 如下 ...
- web自动化测试总结
web自动化: 1.测试用例(操作步骤,熟读需求文档,web项目先用手工研究,前置条件,预期结果) 接口自动化测试中数据功能最适合作为数据驱动,数据放在excel中需要操作excel 为什么web自动 ...
随机推荐
- 读取配置文件properties的几种方式
介绍几种读取方式:参考:https://www.cnblogs.com/sebastian-tyd/p/7895182.html .基于ClassLoder读取配置文件 注意:该方式只能读取类路径下的 ...
- js window.open隐藏参数提交
1.采用form方式提交 var url = "page/public/exportExcel.jsp"; //create a form var tempForm = docum ...
- CustomJSProperties珍藏版。目的是减少客户端的代码数量,但是又能将服务器数据传输给客户端。关键是:数据是实时更新的!!!!
[这是帮助文档的说明] CustomJSProperties EventThe CustomJSProperties event fires each time a control callback ...
- DOS 格式化日期时间输出
if "%date:~5,2%" lss "10" (set mm=0%date:~6,1%) else (set mm=%date:~5,2%)if &quo ...
- 用 CentOS 7 打造合适的科研环境
这篇博文记录了我用 CentOS 7 搭建 地震学科研环境 的过程,供我个人在未来重装系统时参考.对于其他地震学科研人员,也许有借鉴意义. 阅读须知: 本文适用于个人电脑,不适用于服务器: 不推荐刚接 ...
- JS中Float类型加减乘除
//浮点数加法运算 function FloatAdd(arg1,arg2){ var r1,r2,m; try{r1=arg1.toString().split(".")[1]. ...
- 尚硅谷springboot学习10-@PropertySource,@ImportResource,@Bean
@PropertySource 使用指定的属性文件而不一定是application.xxx 同样可以注入相关内容 @ImportResource 导入Spring的配置文件,让配置文件里面的内容生效: ...
- C++复习:C++的类型转换
C++的类型转换 1 类型转换名称和语法 C风格的强制类型转换(Type Cast)很简单,不管什么类型的转换统统是: TYPE b = (TYPE)a C++风格的类型转换提供了4种类型转换操作符来 ...
- Think you can pronounce these 10 words correctly? You might be
Think you can pronounce these 10 words correctly? You might be surprised! Share Tweet Share Tagged ...
- 如何在Windows下安装MYSQL,并截图说明
说明 : window 下安装 mysql 虽然简单,但是细节不注意就会安装失败,特别是配置服务器时,Current Root Password:为空:如果输入密码了在后面安装会报错.(不知道设置这个 ...