PHP 爬虫——QueryList
前言:
来了个任务说要做个电影网站,要写个壳,数据直接从别人那扒。行吧!那就要学习下PHP爬虫了。占个博客,以后补充。http://study.querylist.cc/archives/6/
之前开发抓取网页上的东西,无非就是curl+正则。用curl去请求所要扒取的页面,然后通过正则匹配去提取你所需要的内容。
但是查了下现在PHP爬虫可以通过使用QueryList来实现。可以通过CSS的DOM选择器来实现。
特性:
- 拥有与jQuery完全相同的CSS3 DOM选择器
- 拥有与jQuery完全相同的DOM操作API
- 拥有通用的列表采集方案
- 拥有强大的HTTP请求套件,轻松实现如:模拟登陆、伪造浏览器、HTTP代理等意复杂的网络请求
- 拥有乱码解决方案
- 拥有强大的内容过滤功能,可使用jQuey选择器来过滤内容
- 拥有高度的模块化设计,扩展性强
- 拥有富有表现力的API
- 拥有高质量文档
- 拥有丰富的插件
- 拥有专业的问答社区和交流群
内容:
因为要做一个电影网站,所以这次利用QueryList来爬取电影网资源,这次爬取的是——玩的嗨TV, 网址:http://tv.wandhi.com/movielist/all/3.html。
首先,选取这网站主要是它是个解析站,去破解各大网站的电影资源供给观看,建站也比较简易,没有啥限制防盗链啥的。当然所能爬取到的资源也比较少,也主要是电影播放资源丰富吧。
主要爬取....(采集好像比较好听点)。本次主要采集了玩的嗨TV的电影列表页面和电影播放页面。
安装:
安装QueryList相当的简单,打开项目目录,运行compose命令进行安装
composer require jaeger/guerylist
(注意点 PHP版本需要在7.0以上)
在控制器中引入相应的类就可以开始使用了
use QL\QueryList;
使用:
先贴个小代码
/**
* 采集电影首页
*/
public function film_list($page = ){
$path = '/movielist/all/'.$page.'.html';
$rules = [
'link' => ['.lazy', 'href'],
'img' => ['.title>h5>a', 'src'],
'name' => ['.lazy', 'title'],
'score' => ['.score', 'html'],
'actor' => ['.subtitle', 'html'],
];
$data = QueryList::Query($this->url . $path, $rules)->data;
return $data;
}
从代码中可以很清楚的看出,使用QueryList的Query方法,参数为采集地址和采集规则。
采集地址就是你所要采集页面的网址。
采集规则是一个数组,结构“名字”=>[“css DOM选择器”,‘DOM属性’];
这样就可以采集到页面数据。
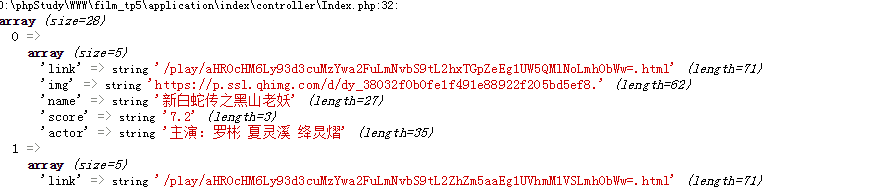
1、电影列表页面
页面结构如下:

爬取结果:
2、电影播放页面
页面结构:

主要采集这两个数据进行拼接就能获得视频的播放地址。
采集结果:

对数据进行拼接就可以获得视频播放地址。
总结:这次采集相对简单。QueryList还有提供了许多深层的方法,后面可以在进行测试使用。主要是进行了简易的采集,获取了所需的数据,电影网也足够了
结语:离职的最后一天,你会做些什么?
PHP 爬虫——QueryList的更多相关文章
- PHP爬虫之queryList
根据queryList 自己花了一个下午的时间写了一个爬星座数据的类,完全手写.附上代码 <?php require '../vendor/autoload.php'; use QL\Query ...
- PHP简单爬虫 基于QueryList采集库 和 ezsql数据库操作类
QueryList是一个基于phpQuery的PHP通用列表采集类,得益于phpQuery,让使用QueryList几乎没有任何学习成本,只要会CSS3选择器就可以轻松使用QueryList了,它让P ...
- Thinkphp5与QueryList,也可以实现采集(爬虫)页面功能
QueryList 是什么 QueryList是一套用于内容采集的PHP工具,它使用更加现代化的开发思想,语法简洁.优雅,可扩展性强.相比传统的使用晦涩的正则表达式来做采集,QueryList使用了更 ...
- php 爬虫框架
发现两款不错的爬虫框架,极力推荐下: phpspider 一款优秀的PHP开发蜘蛛爬虫 官方下载地址:https://github.com/owner888/phpspider 官方开发手册:http ...
- php爬虫学习笔记1 PHP Simple HTML DOM Parser
常用爬虫. 0. Snoopy是什么? (下载snoopy) Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务. Snoopy的一些特点: * ...
- 第一个get请求的爬虫程序
一:urllib库: urllib是Python自带的一个用于爬虫的库,器主要作用就是可以通过代码模拟浏览器发送请求.其被用到子模块在Python3中的urllib.request和urllib.pa ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- QueryList 来做采集
示例代码 先来感受一下使用 QueryList 来做采集是什么样子. 1 采集百度搜索结果列表的标题和链接.大理石平台价格 采集代码: $data = QueryList::get('https:// ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
随机推荐
- BZOJ3534:[SDOI2014]重建(矩阵树定理)
Description T国有N个城市,用若干双向道路连接.一对城市之间至多存在一条道路. 在一次洪水之后,一些道路受损无法通行.虽然已经有人开始调查道路的损毁情况,但直到现在几乎没有消息传回. 幸运 ...
- rhel7.6上安装Oracle 19.2.0.0 RAC
1. 软硬件检查 2. 安装前环境配置 3. 安装GI su - grid -- 解压软件包 unzip -q /ups/soft/V981627-01.zip -d ${ORACLE_HOME} - ...
- 2018-2019-2 20165302 Exp5 MSF基础应用
1.实验目的 掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路 2.实验内容 一个主动攻击实践; (1分) MS17-010 一个针对浏览器的攻击:(1分) ms14_064 一个 ...
- 高斯-克吕格投影与UTM投影
高斯-克吕格投影与UTM投影 高斯-克吕格(Gauss-Kruger)投影与UTM投影(Universal Transverse Mercator,通用横轴墨卡托投影)都是横轴墨卡托投影的变种,目前一 ...
- Python2.7-shelve
shelve模块,持久化对象数据,可以说是 pickle 模块的封装,用于把像字典一样的以键-值存储的数据持久化存储,像操作数据库.当我们写程序的时候如果不想用关系数据库那么重量级的东东去存储数据,不 ...
- Android 截取屏幕图片并保存
Android市场上有很多屏幕截图软件,把当前屏幕截取出来并保存,这一节我们就来看看屏幕截图的具体实现. 操作步骤: 1.创建一片屏幕大小的缓冲区,用于存放屏幕大小的图片 Bitmap bitmap ...
- redis的使用,相比memcached
redis支持数据持久化,不像memcached断电或者重启就丢失数据了. 支持持久化主要有两种方式,在redis.conf配置文件里配置. 1. 使用.rdb格式存储,配置save参数(save N ...
- 关于开发React Native的注意事项
今天在写一个简单的RN的Demo时,一连出现了好几个错误,最后幸亏得以解决,在这里把我踩过的坑以及解决办法分享出来: 1.运行出现错误:Could not connect to development ...
- Base64Util 工具类
package com.org.utils; import java.io.ByteArrayOutputStream; public class Base64Util { private stati ...
- Json.NET如何避免循环引用
Json.NET在将对象序列化为Json字符串的时候,如果对象有循环引用的属性或字段,那么会导致Json.NET抛出循环引用异常. 有两种方法可以解决这个问题: 1.在对象循环引用的属性上打上[Jso ...