PHP 爬虫——QueryList
前言:
来了个任务说要做个电影网站,要写个壳,数据直接从别人那扒。行吧!那就要学习下PHP爬虫了。占个博客,以后补充。http://study.querylist.cc/archives/6/
之前开发抓取网页上的东西,无非就是curl+正则。用curl去请求所要扒取的页面,然后通过正则匹配去提取你所需要的内容。
但是查了下现在PHP爬虫可以通过使用QueryList来实现。可以通过CSS的DOM选择器来实现。
特性:
- 拥有与jQuery完全相同的CSS3 DOM选择器
- 拥有与jQuery完全相同的DOM操作API
- 拥有通用的列表采集方案
- 拥有强大的HTTP请求套件,轻松实现如:模拟登陆、伪造浏览器、HTTP代理等意复杂的网络请求
- 拥有乱码解决方案
- 拥有强大的内容过滤功能,可使用jQuey选择器来过滤内容
- 拥有高度的模块化设计,扩展性强
- 拥有富有表现力的API
- 拥有高质量文档
- 拥有丰富的插件
- 拥有专业的问答社区和交流群
内容:
因为要做一个电影网站,所以这次利用QueryList来爬取电影网资源,这次爬取的是——玩的嗨TV, 网址:http://tv.wandhi.com/movielist/all/3.html。
首先,选取这网站主要是它是个解析站,去破解各大网站的电影资源供给观看,建站也比较简易,没有啥限制防盗链啥的。当然所能爬取到的资源也比较少,也主要是电影播放资源丰富吧。
主要爬取....(采集好像比较好听点)。本次主要采集了玩的嗨TV的电影列表页面和电影播放页面。
安装:
安装QueryList相当的简单,打开项目目录,运行compose命令进行安装
composer require jaeger/guerylist
(注意点 PHP版本需要在7.0以上)
在控制器中引入相应的类就可以开始使用了
use QL\QueryList;
使用:
先贴个小代码
/**
* 采集电影首页
*/
public function film_list($page = ){
$path = '/movielist/all/'.$page.'.html';
$rules = [
'link' => ['.lazy', 'href'],
'img' => ['.title>h5>a', 'src'],
'name' => ['.lazy', 'title'],
'score' => ['.score', 'html'],
'actor' => ['.subtitle', 'html'],
];
$data = QueryList::Query($this->url . $path, $rules)->data;
return $data;
}
从代码中可以很清楚的看出,使用QueryList的Query方法,参数为采集地址和采集规则。
采集地址就是你所要采集页面的网址。
采集规则是一个数组,结构“名字”=>[“css DOM选择器”,‘DOM属性’];
这样就可以采集到页面数据。
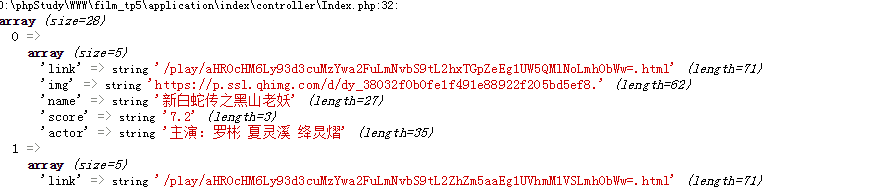
1、电影列表页面
页面结构如下:

爬取结果:
2、电影播放页面
页面结构:

主要采集这两个数据进行拼接就能获得视频的播放地址。
采集结果:

对数据进行拼接就可以获得视频播放地址。
总结:这次采集相对简单。QueryList还有提供了许多深层的方法,后面可以在进行测试使用。主要是进行了简易的采集,获取了所需的数据,电影网也足够了
结语:离职的最后一天,你会做些什么?
PHP 爬虫——QueryList的更多相关文章
- PHP爬虫之queryList
根据queryList 自己花了一个下午的时间写了一个爬星座数据的类,完全手写.附上代码 <?php require '../vendor/autoload.php'; use QL\Query ...
- PHP简单爬虫 基于QueryList采集库 和 ezsql数据库操作类
QueryList是一个基于phpQuery的PHP通用列表采集类,得益于phpQuery,让使用QueryList几乎没有任何学习成本,只要会CSS3选择器就可以轻松使用QueryList了,它让P ...
- Thinkphp5与QueryList,也可以实现采集(爬虫)页面功能
QueryList 是什么 QueryList是一套用于内容采集的PHP工具,它使用更加现代化的开发思想,语法简洁.优雅,可扩展性强.相比传统的使用晦涩的正则表达式来做采集,QueryList使用了更 ...
- php 爬虫框架
发现两款不错的爬虫框架,极力推荐下: phpspider 一款优秀的PHP开发蜘蛛爬虫 官方下载地址:https://github.com/owner888/phpspider 官方开发手册:http ...
- php爬虫学习笔记1 PHP Simple HTML DOM Parser
常用爬虫. 0. Snoopy是什么? (下载snoopy) Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务. Snoopy的一些特点: * ...
- 第一个get请求的爬虫程序
一:urllib库: urllib是Python自带的一个用于爬虫的库,器主要作用就是可以通过代码模拟浏览器发送请求.其被用到子模块在Python3中的urllib.request和urllib.pa ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- QueryList 来做采集
示例代码 先来感受一下使用 QueryList 来做采集是什么样子. 1 采集百度搜索结果列表的标题和链接.大理石平台价格 采集代码: $data = QueryList::get('https:// ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
随机推荐
- JMX RMI 攻击利用
攻击者通过构造恶意的MBean,调用 getMBeansFromURL 从远程服务器获取 MBean,通过MLet标签提供恶意的MBean对象下载. 前提条件: 允许远程访问,没有开启认证 (com. ...
- java通过反射调用有参数的方法
public static void eachCfg(Class Initclass,String taskType){ Field[] fields = Initclass.getDeclaredF ...
- 关于 clock tree
1. create_clock 时,不要定义在 hierarchical pin 上,否则 cts 时会忽略这个 clock ,详见 CTS-811 Warning,解法是将其定义到实际存在的 p ...
- C内存管理相关内容--取自高质量C++&C编程指南
1.内存分配方式 内存分配方式有三种: (1)从静态存储区域分配.内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在.例如全局变量,static变量. (2) 在栈上创建.在执行函数 ...
- day80
昨日回顾 上节回顾: 中间件: -django请求生命周期: -中间件:对全局请求的修改,和全局响应的修改 -process_request:从上往下执行 -process_response:从下往上 ...
- JAVA程序员必看的15本书-JAVA自学书籍推荐
作为Java程序员来说,最痛苦的事情莫过于可以选择的范围太广,可以读的书太多,往往容易无所适从.我想就我自己读过的技术书籍中挑选出来一些,按照学习的先后顺序,推荐给大家,特别是那些想不断提高自己技术水 ...
- Docker容器运行GUI程序的配置方法
0.环境说明 Ubuntu 16.04 docker 1.35 1.Docker的“可视化” Docker本身的工作模式是命令行的,因为主要的使用场景可能是做服务器后端方面的比较多. 但有时候我们会有 ...
- Python3入门(八)——面向对象OOP
一.概述 老生常谈了,万物皆对象.Python作为一门面向对象的语言,也不例外 直接看一个简单的类定义和实例化类的示例: class Student: pass stu = Student() // ...
- FakeID签名漏洞分析及利用(一)
作者:申迪 转载请注明出处: http://blogs.360.cn/360mobile BlueBox于7月30日宣布安卓从2010年以来一直存在一个apk签名问题[1],并且会在今年Black ...
- # 20155218 徐志瀚 EXP7 网络欺诈
20155218 徐志瀚 EXP7 网络欺诈 1. URL攻击 1.在终端中输入命令netstat -tupln |grep 80,查看80端口是否被占用 发现没有被占用: 2.输入指令service ...