爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1、谷歌浏览器的使用
下载谷歌浏览器
安装谷歌访问助手
终于用上谷歌浏览器了。。。。。激动
问题:处理页面动态加载数据的爬取
-1.selenium
-2.phantomJs
1.selenium
二.selenium 什么是selenium?
是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作。 环境搭建 安装selenum:pip install selenium 获取某一款浏览器的驱动程序(以谷歌浏览器为例) 谷歌浏览器驱动下载地址:http://chromedriver.storage.googleapis.com/index.html 下载的驱动程序必须和浏览器的版本统一,大家可以根据http://blog.csdn.net/huilan_same/article/details/51896672中提供的版本映射表进行对应


下载好后选择相应版本解压后粘贴到项目文件夹下

把谷歌浏览器设置成默认的浏览器
import selenium
print(selenium.__file__)
ModuleNotFoundError: No module named 'selenium'
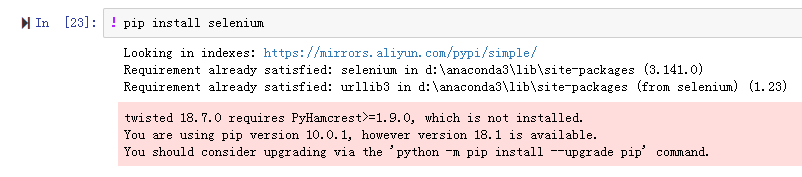
在jupyter下载模块:
------------------------------------------------------------------------------------------

运行成功
-----------------------------------------------------------------------------
#使用下面的方法,查找指定的元素进行操作即可
find_element_by_id 根据id找节点
find_elements_by_name 根据name找
find_elements_by_xpath 根据xpath查找
find_elements_by_tag_name 根据标签名找
find_elements_by_class_name 根据class名字查找
# # #编码流程:
from selenium import webdriver
# 操作速度快 引入sleep观看效果
from time import sleep
#创建一个浏览器对象 executable_path是驱动的路径
bro = webdriver.Chrome(executable_path='./chromedriver')
#get方法可以指定一个url,让浏览器进行请求
bro.get('https://www.baidu.com') # 让百度进行指定词条的搜索
text = bro.find_element_by_id('kw') # 定位到了text文本框
text.send_keys('人名币') # send_keys表示向文本框中录入指定内容
sleep(1)
button = bro.find_element_by_id('su')
button.click()# 点击操作
sleep(3)
bro.quit()#关闭浏览器 # import selenium
# print(selenium.__file__)
2、phantomJs
- PhantomJS是一款无界面的浏览器,其自动化操作流程和上述操作谷歌浏览器是一致的。由于是无界面的,为了能够展示自动化操作流程,PhantomJS为用户提供了一个截屏的功能,使用save_screenshot函数实现。
下载驱动程序,放在当前目录下


from selenium import webdriver bro = webdriver.PhantomJS(executable_path='C:/Users/Administrator/爬虫/动态加载下的爬虫/phantomjs-2.1.1-windows/bin/phantomjs') # 打开浏览器
bro.get('https://www.baidu.com') # 截屏的操作
bro.save_screenshot('./1.png') # 让百度进行指定词条的搜索
text = bro.find_element_by_id('kw') # 定位到了text文本框
text.send_keys('人名币') # send_keys表示向文本框中录入指定内容
# 截屏操作
bro.save_screenshot('./2.png')
bro.quit()


使用selenium+phantomJs处理页面动态加载数据的爬取
- 需求:获取豆瓣电影中动态加载出更多电影详情数据
from selenium import webdriver
from time import sleep
bro = webdriver.PhantomJS(executable_path='C:/Users/Administrator/爬虫/动态加载下的爬虫/phantomjs-2.1.1-windows/bin/phantomjs')
url = 'https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action='
bro.get(url)
sleep(1)
bro.save_screenshot('./3.png')
# 向下拖动滚轮
# 编写js代码,让页面中的滚轮滑动到底部
js = 'window.scrollTo(0,document.body.scrollHeight)' # 如何让浏览器对象执行js代码
bro.execute_script(js)
sleep(1)
bro.save_screenshot('./4.png')
# 获取加载数据后的页面: page_source获取浏览器当前数据
page_text = bro.page_source # 解析数据 print(page_text)

谷歌无头浏览器
- 由于PhantomJs最近已经停止了更新和维护,所以推荐大家可以使用谷歌的无头浏览器,是一款无界面的谷歌浏览器。
- 代码展示:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time # 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 驱动路径
path = r'C:\Users\ZBLi\Desktop\1801\day05\ziliao\chromedriver.exe' # 创建浏览器对象
browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options) # 上网
url = 'http://www.baidu.com/'
browser.get(url)
time.sleep(3) browser.save_screenshot('baidu.png') browser.quit()
爬虫--selenuim和phantonJs处理网页动态加载数据的爬取的更多相关文章
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- (五)selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取 一 图片懒加载 自己理解------就是在打开一个页面的时候,图片数量特别多,图片加载会增加服务器的压力,所以我们在这个时候,就会用到- ...
- selenuim和phantonJs处理网页动态加载数据的爬取
一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding:utf-8 -* ...
- 6-----selenuim和phantonJs处理网页动态加载数据的爬取
动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding ...
- AppCan学习笔记----关闭页面listview动态加载数据
AppCan页面关闭 AppCan 的页面是由两个HTML组成,如果要完全关闭的话需要在主HTML eg.index.html中关闭,关闭方法:appcan.window.close(-1); 管道 ...
- [JS前端开发] js/jquery控制页面动态加载数据 滑动滚动条自动加载事件
页面滚动动态加载数据,页面下拉自动加载内容 相信很多人都见过瀑布流图片布局,那些图片是动态加载出来的,效果很好,对服务器的压力相对来说也小了很多 有手机的相信都见过这样的效果:进入qq空间,向下拉动空 ...
- 微信小程序(五) 利用模板动态加载数据
利用模板动态加载数据,其实是对上一节静态数据替换成动态数据:
- mui 动态加载数据出现的问题处理 (silder轮播组件 indexedList索引列表 下拉刷新不能继续加载数据)
mui-slider 问题:动态给mui的图片轮播添加图片,轮播不滚动. 解决:最后把滚动轮播图片的mui(".mui-slider").slider({interval: 300 ...
- ASP.NET MVC动态加载数据
ASP.NET MVC动态加载数据,一般的做法是使用$.each方法来循环产生tabel: 你可以在html时先写下非动态的部分: Source Code 上图中,有一行代码: <tbody ...
随机推荐
- 学习笔记之C / C++
面试总结之C/C++ - 浩然119 - 博客园 https://www.cnblogs.com/pegasus923/p/5558919.html 学习笔记之C++ How to Program(p ...
- C# 读写 ini 配置文件
虽说 XML 文件越发流行,但精简的 ini 配置文件还是经常会用到,在此留个脚印. 当然,文中只是调用系统API,不会报错,如有必要,也可以直接以流形式读取 ini文件并解析. /// <su ...
- phpmyadmin在nginx环境下配置错误
location ~ \.css { add_header Content-Type text/css; } location ~ \.js { ...
- 00011 - find中的-print0和xargs中-0的奥妙
默认情况下, find 每输出一个文件名, 后面都会接着输出一个换行符 ('\n'), 因此我们看到的 find 的输出都是一行一行的: [bash-4.1.5] ; ls -l total 0 -r ...
- BCGcontrolBar(六) RibbonBar编辑
BCGcontrolBar 可以使用 Ribbon Designer方便的对 Ribbon条进行编辑 文件位置为 C:\Program Files\BCGSoft\BCGControlBarPro\D ...
- MySQL客户端管理
mysql -P3306 -h localhost -u root -p 分别是:端口 服务器 用户名 有密码(这里可以先不用输入,带这个参数表示有密码,密码在打开客户端后输入,也可以在这里直接输入 ...
- sql-datediff
SQL中DateDiff的用法 DATEDIFF返回跨两个指定日期的日期和时间边界数. 语法DATEDIFF ( datepart , startdate , enddate ) 参数datepart ...
- CS229 6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特征提取方面完全是用的无监督的方法,对于有标记的数据,可以结合有监督学习来对上述方法得到的参数进行微调,从而得到一个更加准确的参数a. 在self-taug ...
- ViewPager的addOnPageChangeListener和setOnPageChangeListener的区别,ViewPager改变数据后IndexOutOfBoundsException
我的ViewPager数据改变后,在切换界面刷新数据时:OnPageChangeListener中的数据IndexOutOfBoundsException,我们来看源码探一下究竟: 代码时这样写的: ...
- 二、Html5元素、属性、格式化