python爬虫_入门
本来觉得没什么可写的,因为网上这玩意一搜一大把,不过爬虫毕竟是python的一个大亮点,不说说感觉对不起这玩意
基础点来说,python2写爬虫重点需要两个模块,urllib和urllib2,其实还有re
先介绍下模块的一些常用功能
urllib.urlopen('http://xxx.xxx.xxx') #打开一个网址,只是打开,和open差不多
urllib2.Request(url) #解析网址,这个可以省略,具体不是很懂,一些功能,比如加head头什么的也需要使用这个
urllib.urlretrieve(url,filename) #下载用,把url提供的东西down下来,并用filename保存
举个蜂鸟爬图片的例子,下面上伪代码:
1、url解析
2、打开url
3、读取url,就是read()
4、使用re.findall找到所有和图片有关系的地址,这里只jpg
5、循环下载
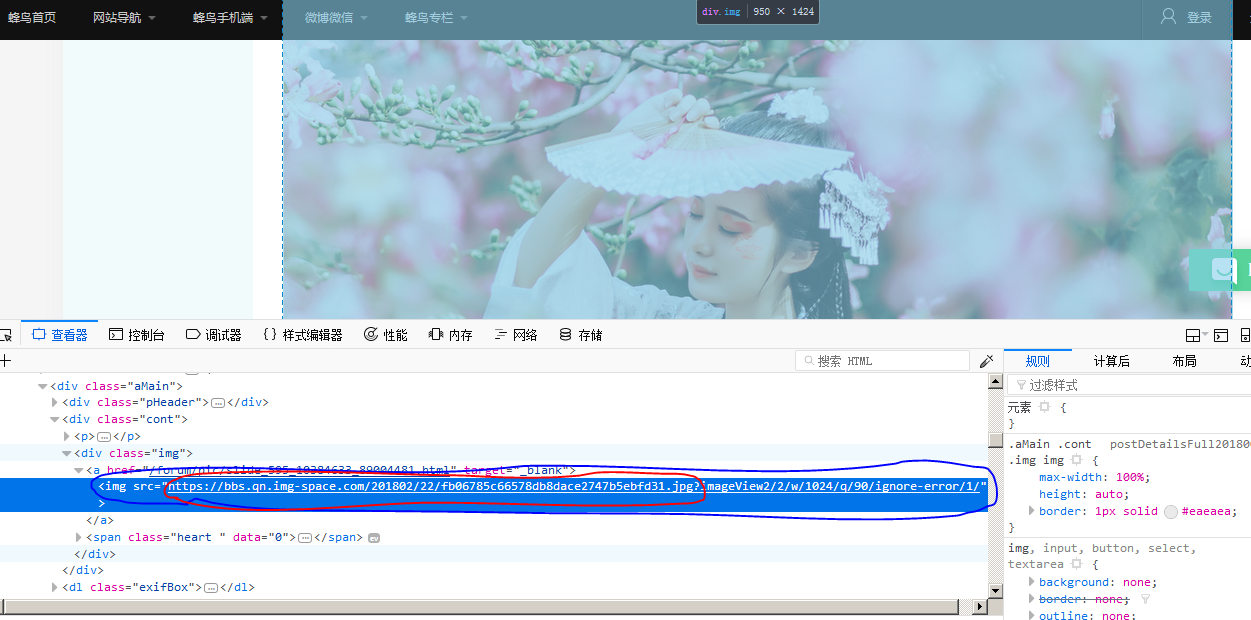
看图上,图片链接格式是src="http://index_url/page_num/image_name.jpg?XXXXXXX",那么如果需要下载的话一定是需要红圈部分,也就是http://index_url/page_num/image_name.jpg
分析之后后面的事就好办了,下面上代码
import urllib
import urllib2
import re #处理地址,并获取页面全部的图片地址
def get_image_url(url):
#url_format = urllib2.Request(url) #1
url_open = urllib.urlopen(url) #
url_read = url_open.read() #
re_value = re.compile('(?<=src\=\").*?\.jpg')
image_url_list = re.findall(re_value,url_read) #
return image_url_list #这个函数专门用来下载,前面两行是将图片连接中/前面的内容全部删除,留下后面的文件名用来保存文件的,try不说了,不清楚请翻回去看容错
def down_image(image_url):
rev = '^.*/'
file_name = re.sub(rev,'',image_url)
try:
urllib.urlretrieve(image_url,file_name)
except:
print 'download %s fail' %image_url
else:
print 'download %s successed' %image_url if __name__ == '__main__':
url = 'http://bbs.fengniao.com/forum/10384633.html'
image_url_list = get_image_url(url)
for image_url in image_url_list:
down_image(image_url) #
困死,睡觉去。。。。。有时间再说说翻页什么的,就能爬网站了
python爬虫_入门的更多相关文章
- python爬虫_入门_翻页
写出来的爬虫,肯定不能只在一个页面爬,只要要爬几个页面,甚至一个网站,这时候就需要用到翻页了 其实翻页很简单,还是这个页面http://bbs.fengniao.com/forum/10384633. ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
- Python爬虫教程——入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
随机推荐
- 深入理解.sync修饰符
原文地址:http://www.geeee.top/2019/04/17/vue-sync/ 转载请注明出处 .sync修饰符 一个组件上只能定义一个v-model,如果其他prop也要实现双向绑定的 ...
- 偏流角为什么是arcsin(w/V)
偏流角为什么是arcsin(w/V) 2015-10-22 风螺旋线 回答这个问题要从速度三角形说起(需要了解一点三角函数,但很基础,不用担心). 传统的速度三角形如下图所示: (背一段书) DA ...
- Silverlight 查询DataGrid 中匹配项 ,后台改变选中行颜色
需求:根据关键字(参会人号码或名称)查找参会人,在datagird 中高亮显示 界面:我在界面上增加了一个文本框和按钮,进行查找操作 操作说明: 根据关键字进行搜索:输入关键字 点击查找,如果找到 以 ...
- .33-浅析webpack源码之doResolve事件流(5)
file => FileExistsPlugin 这个事件流快接近尾声了,接下来是FileExistsPlugin,很奇怪的是在最后才来检验路径文件是否存在. 源码如下: FileExistsP ...
- Spring学习之路-注解
Spring的注解总结. 地址:https://docs.spring.io/spring/docs/4.3.12.RELEASE/spring-framework-reference/htmlsin ...
- tabs自动切换功能的实现
<html><head><!-- Bootstrap 核心 CSS 文件 --> <link rel="stylesheet" href= ...
- 在GridView控件内文本框实现TextChanged事件
本篇是教你实现GridView控件内的TextBox文本框实现自身的TextChanged事件.由于某些功能的需求,GridView控件内嵌TextBox,当TextBox值发生变化时,触发TextC ...
- 关于.net程序集引用不匹配的问题
今天启动asp.net mvc 程序,其中也用到了web api ,autofac等,为了版本兼容性问题,将mvc和 web api 的版本控制到5.2.0.0,Newtonsoft.Json 的版本 ...
- .NET Core类库中读取配置文件
最近在开发基于.NET Core的NuGet包,遇到一个问题:.NET Core中已经没有ConfigurationManager类,在类库中无法像.NET Framework那样读取App.conf ...
- C#编译和运行过程图例
一张图,描述C#编译和运行过程,比较容易记忆理解