Java虚拟机代码是如何一步一步变复杂且难以理解的?
有相关统计数据显示,Java开发者有1000万+,这么多的人每天都在使用Java虚拟机进行开发,不过真正看过虚拟机代码的人应该非常非常少吧,可能有些人研究过,不过由于Java虚拟机是一个高度复杂的系统性工程,过于复杂的实现让他们最终放弃。
目前服务器上使用最多的虚拟机还是HotSpot,HotSpot是用C/C++编写的,JDK8版本中虚拟机的代码就有60万行左右的代码,我们需要聚焦C1、C2编译器、垃圾回收、最基础的类加载等模块,以及只针对某一特定平台和架构下的代码实现(推荐研究linux平台下的x86-64位架构实现),那也有50万行左右的代码,所以对于想研究HotSpot虚拟机的Java程序员来说,挑战很大。
这一篇就以HotSpot中实现相对复杂的一个点展开研究,看看它是如何一步一步变成今天这么复杂的。简单来说,有为了性能的,也有为了满足Java更多特性的,以GC任务提交执行为例能很好的说明代码从简单变为复杂的一个过程。
文章分为4部分:
- 基本需求
- 执行非安全点任务
- 优化安全点任务的执行效率
- 支持临界区
4.1 VMThread对临界区的支持
4.2 业务线程对临界区的支持
4.3 业务线程提交GC任务
通过学习这篇文章,你就能够从最简单的实现开始,一步一步彻底理解ParallelScavengeHeap::mem_allocate()、VMThread::execute()以及VMThread::loop()这些复杂函数的实现逻辑了。
业务线程在执行应用程序时,通过调用ParallelScavengeHeap::mem_allocate()函数为Java对象分配内存。如果内存不足,此时就要调用VMThread::execute()函数向队列提交一个GC任务了。
VMThread::loop()中有一个VMThead守护线程会从队列中取出这些任务(包括刚才提交的GC任务)并执行垃圾收集。
1. 基本需求
ParallelScavengeHeap::mem_allocate()函数的实现如下:
// size指定分配的内存大小
HeapWord* ParallelScavengeHeap::mem_allocate(size_t size){
// 尝试在年轻代分配内存,allocate()不需要加锁,这个函数自己有处理
// 多线程的能力
PSYoungGen* psyg = young_gen();
HeapWord* result = psyg->allocate(size);
if(result == NULL){
MutexLocker ml(Heap_lock);
// 再次进行判断,如果分配成功则避免重复提交GC请求
result = young_gen()->allocate(size);
if (result != NULL) {
return result;
}
// 尝试从老年代中分配内存,老年代中分配时必须要加锁
result = mem_allocate_old_gen(size);
if (result != NULL) {
return result;
}
// 提交一个GC任务
VM_ParallelGCFailedAllocation op(size);
Thread::execute(&op);
return op.result;
}
return result;
}
void VMThread::execute(VM_Operation* op) {
{
// 操作_vm_queue队列时必须要获取VMOperationQueue_lock锁,GC线程等待在
// 这个锁上,如果GC线程获取到这个锁,会尝试获取其中的任务
VMOperationQueue_lock->lock_without_safepoint_check();
// 向队列中加入新的任务,其中_vm_queue是VMOperationQueue*类型的全局变量,
// 不是一个线程安全队列
_vm_queue->add(op);
// 唤醒VMThread线程,执行队列中的任务
VMOperationQueue_lock->notify();
VMOperationQueue_lock->unlock();
}
// 提交GC任务后,等待这个GC任务执行完成后,在堆中释放出空间才可能满足
// 这次的内存分配请求
VMOperationRequest_lock->wait();
}
业务线程会提交GC请求,如果堆内存紧张的话,极有可能多个业务线程同时提交GC任务,GC任务会造成STW(Stop The World),影响系统时延和吞吐量,所以通过Heap_lock互斥锁加上重试分配逻辑来避免这样的问题。
下面看一下VMThread单线程取GC任务执行的实现逻辑:
void VMThread::loop() {
while(true) {
{
由于队列不是一个线程安全的容器,所以要通过锁来保证线程安全性
MutexLockerEx mu_queue(VMOperationQueue_lock,Mutex::_no_safepoint_check_flag);
// 从队列中获取一个新的任务
_cur_vm_operation = _vm_queue->remove_next();
// 如果当前线程不应该终止并且没有从队列中获取到任务时,需要等待
while (_cur_vm_operation == NULL) {
VMOperationQueue_lock->wait();
...
// 线程被唤醒后从队列中获取任务
_cur_vm_operation = _vm_queue->remove_next();
}
}
// 进入安全点执行需要在安全点执行的GC任务,如Parallel GC的YGC和FGC是一定要在安全点下执行的
SafepointSynchronize::begin();
evaluate_operation(_cur_vm_operation);
SafepointSynchronize::end();
{
// 通知相关任务执行完成,唤醒业务线程继续执行
MutexLockerEx mu(VMOperationRequest_lock);
VMOperationRequest_lock->notify_all();
}
} // while循环结束
}
业务线程和VMThread线程之间的交互涉及到了VMOperationQueue_lock和VMOperationRequest_lock锁,VMOperationQueue_lock锁在保护队列的同时,也让有任务到来时,能及时获取队列中的任务并执行。
执行完成后通过VMOperationRequest_lock通知业务线程,结束本次GC垃圾回收操作。
交互操作如下图所示。
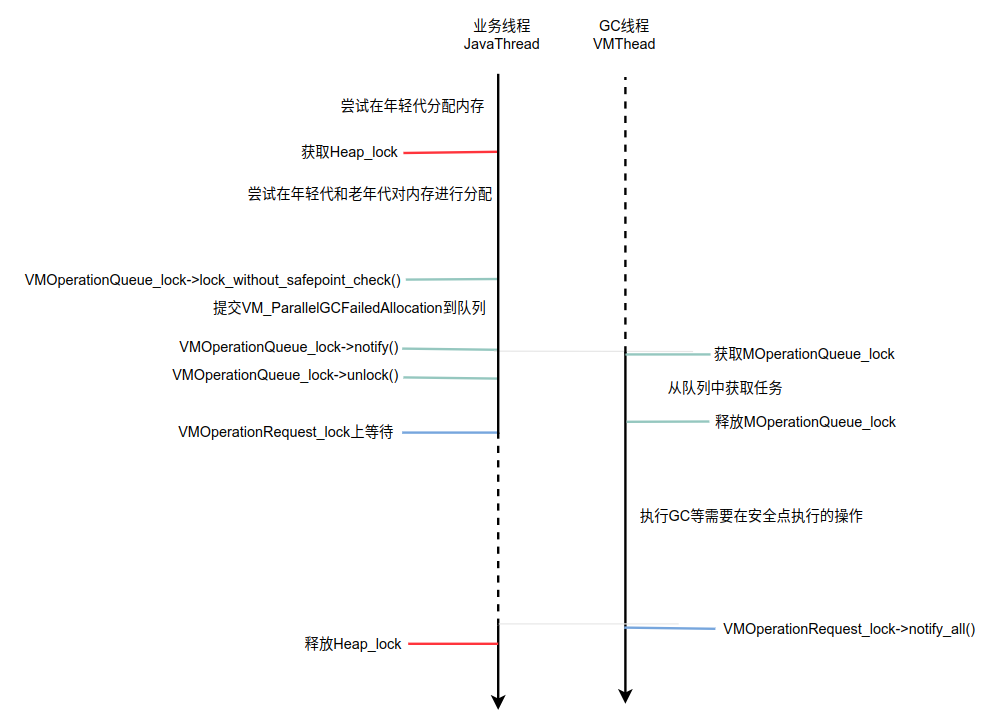
2. 执行非安全点任务
有一些非安全点的任务可在VMThread空闲时执行,重构VMThread::loop()后的实现如下:
void VMThread::loop() {
while(true) {
{
MutexLockerEx mu_queue(VMOperationQueue_lock,Mutex::_no_safepoint_check_flag);
_cur_vm_operation = _vm_queue->remove_next();
while (_cur_vm_operation == NULL) {
// 等待一段时间(由GuaranteedSafepointInterval选项指定)后,就从队列中获取任务
bool timedout = VMOperationQueue_lock->wait(Mutex::_no_safepoint_check_flag,GuaranteedSafepointInterval);
_cur_vm_operation = _vm_queue->remove_next();
}
}
if (_cur_vm_operation->evaluate_at_safepoint()) { // 在安全点下执行任务
SafepointSynchronize::begin();
evaluate_operation(_cur_vm_operation);
SafepointSynchronize::end();
} else {
// 在非安全点下执行任务时,每次只会执行一个任务,然后再次获取任务,不能一次执行多个
// 非安全占下任务时,导致安全点下的优先级高的任务得不到及时执行
evaluate_operation(_cur_vm_operation);
_cur_vm_operation = NULL;
}
{
MutexLockerEx mu(VMOperationRequest_lock);
VMOperationRequest_lock->notify_all();
}
} // while循环结束
}
在一些业务线程提交非安全点上执行的任务时并不会等待,可能有时候连notify()都不会调用,所以这里需要在VMOperationQueue_lock->wait()上定时去唤醒来执行非安全点上的任务。
3. 优化执行安全点任务
调用SafepointSynchronize::begin()会让所有的业务线程进入安全点,这会对整个系统的时延和吞吐量造成影响。所以是重点优化的地方。既然安全点进入来之不易,那在进入安全点后,就尽量多执行一些需要在安全点上执行的任务,最好是把当前能获取到的安全点任务都执行完,优化后的代码实现如下:
void VMThread::loop() {
while(true) {
// 将_vm_queue队列中一些优化级比较高的、需要在安全点下执行的任务都提取出来单独保存
VM_Operation* safepoint_ops = NULL;
{
MutexLockerEx mu_queue(VMOperationQueue_lock,Mutex::_no_safepoint_check_flag);
_cur_vm_operation = _vm_queue->remove_next();
while (_cur_vm_operation == NULL) {
bool timedout = VMOperationQueue_lock->wait(Mutex::_no_safepoint_check_flag,GuaranteedSafepointInterval);
_cur_vm_operation = _vm_queue->remove_next();
}
// 如果当前获取到的任务需要在安全点下执行,则获取队
// 列中的所有需要在安全点中执行的任务,这样要尽量在一次STW期间
// 内执行完所有需要在安全点中执行的任务
if (
_cur_vm_operation != NULL &&
_cur_vm_operation->evaluate_at_safepoint()
){
// 获取队列中的所有需要在安全点中执行的任务
safepoint_ops = _vm_queue->drain_at_safepoint_priority();
}
}
{
// 将需要在安全点下执行的任务列表保存到_drain_list属性中
_vm_queue->set_drain_list(safepoint_ops);
// 进入安全点
SafepointSynchronize::begin();
// 执行任务
evaluate_operation(_cur_vm_operation);
// 循环执行任务列表中的所有任务
do {
_cur_vm_operation = safepoint_ops;
if (_cur_vm_operation != NULL) {
do {
VM_Operation* next = _cur_vm_operation->next();
_vm_queue->set_drain_list(next);
evaluate_operation(_cur_vm_operation);
// 针对线程设定任务完成数量,好让等待的线程迟早退出等待状态
op->calling_thread()->increment_vm_operation_completed_count();
_cur_vm_operation = next;
} while (_cur_vm_operation != NULL);
}
// 在执行任务的过程中,可能队列中又被其它业务线程压入了优化级高且需要在安全点下执行的任务,
// 取出来继续执行
if (_vm_queue->peek_at_safepoint_priority()) {
MutexLockerEx mu_queue(VMOperationQueue_lock,Mutex::_no_safepoint_check_flag);
safepoint_ops = _vm_queue->drain_at_safepoint_priority();
} else {
safepoint_ops = NULL;
}
} while(safepoint_ops != NULL);
_vm_queue->set_drain_list(NULL);
// 离开安全点
SafepointSynchronize::end();
}
{
MutexLockerEx mu(VMOperationRequest_lock);
VMOperationRequest_lock->notify_all();
}
} // while循环结束
}
经过这一次的性能优化后,VMThread::loop()函数变的复杂了起来。
首先是从_vm_queue队列中分离出了需要在安全点下操作的高优先级任务,这些任务需要串行操作,也就是一个操作完成后才能再操作一个。在操作第一个任务,那后面的安全点任务也要做为根进行扫描的,这就是调用set_drain_list()的原因。
另外,为了高效,我们从队列中取出任务后就释放了VMOperationQueue_lock,这会让其它的业务线程也会提交更多的任务到队列,所以我们在进入安全点后,执行的安全点任务要比之前更多了,效率更高了。
现在VMThread::loop()函数的实现已经非常接近JDK8的版本了,不过还需要完善一些细节,比如VMThead做为后台线程,应该在Java业务线程退出时停止等。完整函数的判断流程如下图所示。
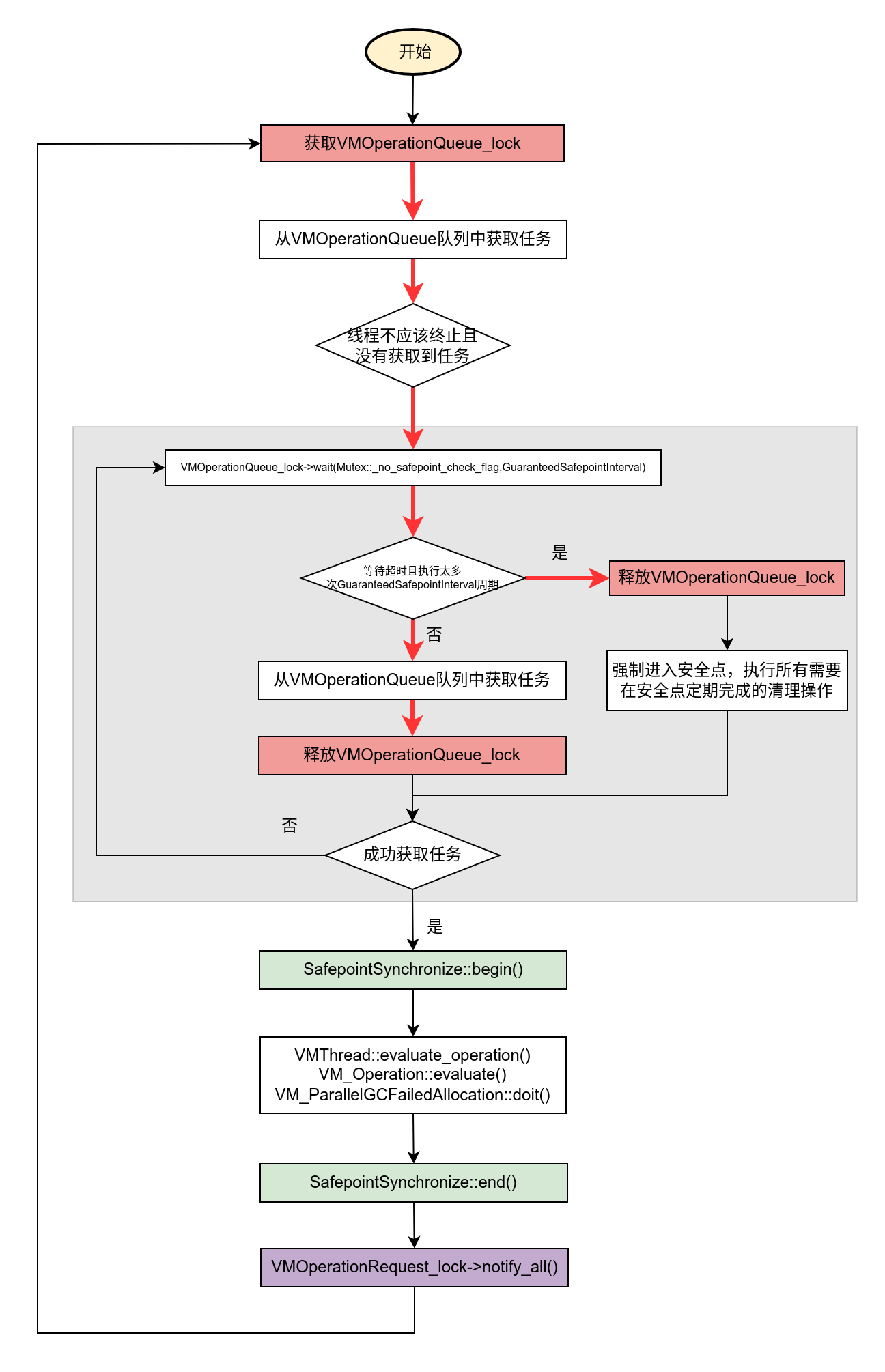
void VMThread::execute(VM_Operation* op) {
Heap_lock->lock();
// 任务中保存当前的线程,让VMThread在执行完任务时,针对这个线程设定任务完成数量,让当前
// 线程尽快退出等待状态
op->set_calling_thread(t, Thread::get_priority(t));
int ticket = t->vm_operation_ticket();
{
VMOperationQueue_lock->lock_without_safepoint_check();
bool ok = _vm_queue->add(op);
VMOperationQueue_lock->notify();
VMOperationQueue_lock->unlock();
}
{
// 当前的JavaThread必须等待任务执行完成后的结果
MutexLocker mu(VMOperationRequest_lock);
// 当Thread::_vm_operation_started_count的值大于等于ticket时,表示
// 提交的任务已经执行完成,JavaThread不必等待,可以开始运行了
while(t->vm_operation_completed_count() < ticket) {
VMOperationRequest_lock->wait();
}
}
Heap_lock->unlock();
}
提交一个任务时,返回_vm_operation_started_count加1后的结果做为ticket,当任务执行完成后,VMThread会调用increment_vm_operation_completed_count()函数对_vm_operation_completed_count加1,由于_vm_operation_started_count与_vm_operation_completed_count初始时都为0,所以当_vm_operation_completed_count不小于_vm_operation_started_count时就表示任务执行完成,可以不用等待了。
有人可能好奇,这里为什么要用计数来判断呢?这是因为有些业务线程提交了安全点操作后并不需要等待执行结果,而GC垃圾回收任务,例如Parallel Scaveng提交一个VM_ParallelGCFailedAllocation是需要等待任务执行结果的,当然也可以通过判断具体的VM_ParallelGCFailedAllocation任务是否完成来结束等待,不过鉴于之前在VMThread::loop()中会批处理安全点任务,这里计数就可以达到目的了。
4. 对临界区的支持
使用JNI临界区的方式操作数组或者字符串时,为了防止GC过程中jarray或者jstring发生位移而导致数组指针失效,需要保持它们在Java堆中的地址在JNI临界区执行过程中保持不变。HotSpot通过GC_locker来阻止其他GC的发生。
HotSpot通过阻止GC来防止堆中对象的移动,这样就不用将堆中的数据先行拷贝到C/C++堆中,这样可避免因为数据拷贝导致的开销,从而提高JNI的性能。
临界区的支持要涉及到当前正在临界区执行代码的线程、提交GC任务的业务线程和执行GC任务的VMThread线程,这几个线程通过JNICritical_lock全局互斥锁以及GC_locker中定义的_needs_gc、_jni_lock_count等静态变量来交互。
GC_locker类的定义如下:
class GC_locker: public AllStatic {
private:
// 这个属性记录了当前在临界区中的线程数量
// 当进入安全点时才会更新这个值,因为此时的业务线程已经STW,可能会改变_jni_lock_count的只有本地线程,
// 本地线程此时的状态可能是:
// 1. 没有进入安全点,如果操作对象,则会被阻塞
// 2. 要进入临界区
// 3. 进入临界区了,要离开
static volatile jint _jni_lock_count;
static volatile jint _lock_count; // number of other active instances
static volatile bool _needs_gc; // heap is filling, we need a GC
static volatile bool _doing_gc; // unlock_critical() is doing a GC
// ...
上面的变量全部都是静态全局的,所以操作时要注意多线程问题。
4.1 VMThread对临界区的支持
当VMthread进入安全点开始执行任务时发现有线程进入,此时无论如何也不能继续GC,只能退出并将_needs_gc变量设置为true。
VMThread::loop()
VMThread::evaluate_operation()
VM_Operation::evaluate()
VM_ParallelGCFailedAllocation::doit()
ParallelScavengeHeap::failed_mem_allocate()
PSScavenge::invoke()
PSScavenge::invoke_no_policy()
PSParallelCompact::invoke_no_policy()
VMThread是单线程在安全点下执行GC,在PSScavenge::invoke_no_policy()和PSParallelCompact::invoke_no_policy()函数中首先会调用GC_locker::check_active_before_gc()函数判断是否有线程进入了临界区,函数的实现如下:
// 当前函数在安全点内调用
bool GC_locker::check_active_before_gc() {
assert(SafepointSynchronize::is_at_safepoint(), "only read at safepoint");
if (is_active() && !_needs_gc) {
_needs_gc = true;
}
return is_active();
}
static bool is_active() {
return is_active_internal();
}
static bool is_active_internal() {
return _lock_count > 0 || _jni_lock_count > 0;
}
调用check_active_before_gc()函数时,可能会将_needs_gc设置为true,注意这里是唯一一个将_needs_gc设置为true的地方。如果设置为true,则:
- 会阻塞其他业务线程进入JNI临界区;
- 在最后一个位于JNI临界区的线程退出临界区时,发起一次CGCause为_gc_locker的GC;
- 让尝试提交GC任务的线程阻塞等待,逻辑在GC_locker::stall_until_clear()函数中实现。
另外在VM_ParallelGCFailedAllocation::doit()函数中也有对临界区的支持逻辑,如下:
void VM_ParallelGCFailedAllocation::doit() {
SvcGCMarker sgcm(SvcGCMarker::MINOR);
ParallelScavengeHeap* heap = (ParallelScavengeHeap*)Universe::heap();
GCCauseSetter gccs(heap, _gc_cause);
_result = heap->failed_mem_allocate(_size);
// 需要发生GC并且还有线程在临界区内执行任务??
if (_result == NULL && GC_locker::is_active_and_needs_gc()) {
set_gc_locked();
}
}
void set_gc_locked() {
_gc_locked = true; // 定义在VM_GC_Operation类中的实例变量
}
当_gc_locked为true时,本次的GC任务并没有真正执行,但是GC_locker::is_active_and_needs_gc()为true时表示有临界区线程,当最后一个临界区线程退出时会触发GC执行,那么提交此次GC任务的那个线程就需要重试了,后面在介绍ParallelScavengeHeap::mem_allocate()函数时会介绍。
4.2 业务线程对临界区的支持
进入临界区的代码如下:
inline void GC_locker::lock_critical(JavaThread* thread) {
// 当前线程还没有进入临界区时,可能在进入临界区时要阻塞等待GC执行完成
if (!thread->in_critical()) {
// needs_gc()表示现在堆中需要发生GC来进行垃圾回收
if (needs_gc()) {
jni_lock(thread);
return;
}
}
thread->enter_critical();
}
在进入临界区时,如果当前线程不在临界区并且_needs_gc的值为true时,要调用jni_lock()。_needs_gc为true表示有VMThead线程在安全点中试着执行GC任务,但是由于临界区有线程在,所以没有执行。那当退出临界区的最后一个线程是需要调用GC_locker::unlock_critical()函数触发GC的,所以如果是GC已经触发,那么_doing_gc为true,这个线程要阻塞等待;假设上一个线程还在临界区,那当前线程也要阻塞,因为要防止饿死GC线程。
void GC_locker::jni_lock(JavaThread* thread) {
// 加互斥锁
// 1. 保护_doing_gc变量
// 2. 保护_jni_lock_count变量
MutexLocker mu(JNICritical_lock);
// 当需要发生GC并且已经有至少一个线程在临界区时,要阻止当前的线程进入临界区,防止饿死GC线程
// 当正在发生GC时,同样需要阻止当前线程进入临界区
while ((needs_gc() && is_jni_active()) || _doing_gc) {
JNICritical_lock->wait();
}
// 当前线程被允许进入临界区
thread->enter_critical();
_jni_lock_count++; // 进入临界区的线程数量要增加1
}
static bool is_jni_active() {
assert(_needs_gc, "only valid when _needs_gc is set");
return _jni_lock_count > 0;
}
// _jni_active_critical是一个实例变量,表示一个线程进入临界区的数量
bool in_critical() {
return _jni_active_critical > 0;
}
void enter_critical() {
_jni_active_critical++;
}
下面看一下退出临界区的代码,如下:
退出临界区的代码如下:
inline void GC_locker::unlock_critical(JavaThread* thread) {
if (thread->in_last_critical()) { // 当前线程实例变量_jni_active_critical的值为1
if (needs_gc()) {
// 如果当前线程是临界区中最后一个线程,并且堆需要发生GC回收垃圾时,
// 要在退出临界区时触发垃圾回收操作
jni_unlock(thread);
return;
}
}
thread->exit_critical();
}
// 只有当前线程是临界区中最后一个线程时才会调用这个函数
void GC_locker::jni_unlock(JavaThread* thread) {
MutexLocker mu(JNICritical_lock);
_jni_lock_count--; // 临界区的线程数量减一
thread->exit_critical(); // 当前线程进入的临界区的数量减一
// 当前线程是临界区最后一个线程了,需要触发GC操作
if (needs_gc() && !is_jni_active()) {
if (!is_active_internal()) {
_doing_gc = true;
{
// Must give up the lock while at a safepoint
MutexUnlocker munlock(JNICritical_lock);
// 触发一次原因为GCCause::_gc_locker的GC
Universe::heap()->collect(GCCause::_gc_locker);
}
_doing_gc = false;
}
_needs_gc = false;
// 唤醒被阻塞在临界区外面的线程
JNICritical_lock->notify_all();
}
}
static bool is_active_internal() {
return _lock_count > 0 || _jni_lock_count > 0;
}
bool in_last_critical() {
return _jni_active_critical == 1;
}
void exit_critical() {
_jni_active_critical--;
}
最后一个位于JNI临界区的线程退出临界区时,发起一次CGCause为_gc_locker的GC。
如上函数要注意,在调用Universe::heap()->collect()函数之前释放了JNICritical_lock锁,这是为了让一切没有进入临界区的线程全部都能走到GC_locker::jni_lock()函数的wait()上,为本次的GC任务让路。
调用的collect()函数的实现如下:
void ParallelScavengeHeap::collect(GCCause::Cause cause) {
assert(!Heap_lock->owned_by_self(),
"this thread should not own the Heap_lock");
unsigned int gc_count = 0;
unsigned int full_gc_count = 0;
{
MutexLocker ml(Heap_lock);
// This value is guarded by the Heap_lock
gc_count = Universe::heap()->total_collections();
full_gc_count = Universe::heap()->total_full_collections();
}
VM_ParallelGCSystemGC op(gc_count, full_gc_count, cause);
VMThread::execute(&op);
}
4.3 业务线程提交GC任务
HeapWord* ParallelScavengeHeap::mem_allocate(
size_t size,
bool* gc_overhead_limit_was_exceeded
){
// 发生在GC占用大量时间为释放很小空间的时候发生的,是一种保护机制
// 这里初始化为false,后面根据实际情况进行值的更新
*gc_overhead_limit_was_exceeded = false;
PSYoungGen* psyg = young_gen();
HeapWord* result = psyg->allocate(size);
uint gc_count = 0;
int gclocker_stalled_count = 0;
while (result == NULL) {
{
MutexLocker ml(Heap_lock);
gc_count = Universe::heap()->total_collections();
result = young_gen()->allocate(size);
if (result != NULL) {
return result;
}
// 尝试从老年代中分配内存
result = mem_allocate_old_gen(size);
if (result != NULL) {
return result;
}
// 当线程尝试分配内存时,若此时GCLocker机制暂时冻结GC操作。
// 此时分配请求会进入重试流程,GCLockerRetryAllocationCount 即记录重试次数
if (gclocker_stalled_count > GCLockerRetryAllocationCount) {
return NULL;
}
// 有线程在进入临界区并且当前堆需要发生GC收集时,is_active_and_needs_gc()返回true
if (GC_locker::is_active_and_needs_gc()) {
// 当临界区最终被清空时,最后一个退出临界区的线程会触发GC。
// 因此我们会从循环开始处重试分配流程,而非触发更多(此时可能已无必要的)GC尝试。
JavaThread* jthr = JavaThread::current();
if (!jthr->in_critical()) {
// 在这里释放了Heap_lock锁
MutexUnlocker mul(Heap_lock);
// 由于临界区的扰乱,本来堆中内存吃紧,需要发生GC回收(_needs_gc的值为true)的时候,有线程却
// 在临界区内阻塞了GC回收,此时当前要提交GC任务的业务线程就只能等待在JNICritical_lock锁上
GC_locker::stall_until_clear();
// 等待退出临界区时,然后从头再试
gclocker_stalled_count += 1;
continue;
} else {
// 一定要让在临界区的代码返回,否则临界区线程可能永远出不来,导致系统实际上僵死
// 当前线程在执行临界区代码时,由于内存没有成功分配导致流程执行到这里
if (CheckJNICalls) {
fatal("Possible deadlock due to allocating while in jni critical section");
}
return NULL;
}
}
} // 持有Heap_lock锁的块结束,锁将被释放
// 注意下面的代码执行时,Heap_lock锁已经释放,那么可能有多个业务线程在分配内存失败时,会提交GC任务
// 对于Parallel GC来说,仍然是再次获取Heap_lock锁来互斥操作,不过由于锁可以轮流持有,所以仍然可能会
// 重复提交GC任务,此时就在第一个线程提交GC任务后,会增加gc计数,这样第二个线程在获取互斥锁时,判断
// gc_count和实时取到的gc计数不同,就会跳过gc操作,回到本次的while大循环内重新试着分配内存
if (result == NULL) {
// 流程走到这里说明了:
// 1、内存分配没有成功
// 2、大概率已经没有线程在临界区了,因为没有锁的保护,所以可能还有线程进入临界区
VM_ParallelGCFailedAllocation op(size, gc_count);
VMThread::execute(&op);
// 提交的GC任务是否已打算执行?若打算执行,prologue_succeeded()函数返回true
// 该机制可避免系统对无法满足的请求持续重试,从而防止陷入循环直至超时。
if (op.prologue_succeeded()) {
// 若在GC任务操作期间GC被锁定,则需重试内存分配和/或进入等待状态,这就是因为
// 进入安全点后才发现,又有线程进入临界区了,导致没办法执行GC任务
if (op.gc_locked()) {
continue;
}
// 如果已超过GC时间限制,则退出循环。
// 此时内存分配必定已在上方失败(守卫此路径的"result"为NULL),且最近一次垃圾
// 收集已超过GC开销限制(尽管可能已回收足够内存来满足此次分配)。退出循环以便
// 抛出内存溢出错误(返回NULL并忽略op.result()的内容),但需要清除
// gc_overhead_limit_exceeded标志,让下一次垃圾收集可以从全新状态开始(即忘记之前开销超标的情况)。
const bool limit_exceeded = size_policy()->gc_overhead_limit_exceeded();
const bool softrefs_clear = collector_policy()->all_soft_refs_clear();
if (limit_exceeded && softrefs_clear) {
*gc_overhead_limit_was_exceeded = true;
size_policy()->set_gc_overhead_limit_exceeded(false);
if (op.result() != NULL) {
// 用填充对象填充op.result(),以保持堆的可解析性
CollectedHeap::fill_with_object(op.result(), size);
}
return NULL;
}
return op.result();
}
} // if (result == NULL) 判断结束
} // while (result == NULL) 循环结束
return result;
}
上面图的流程如下图所示。
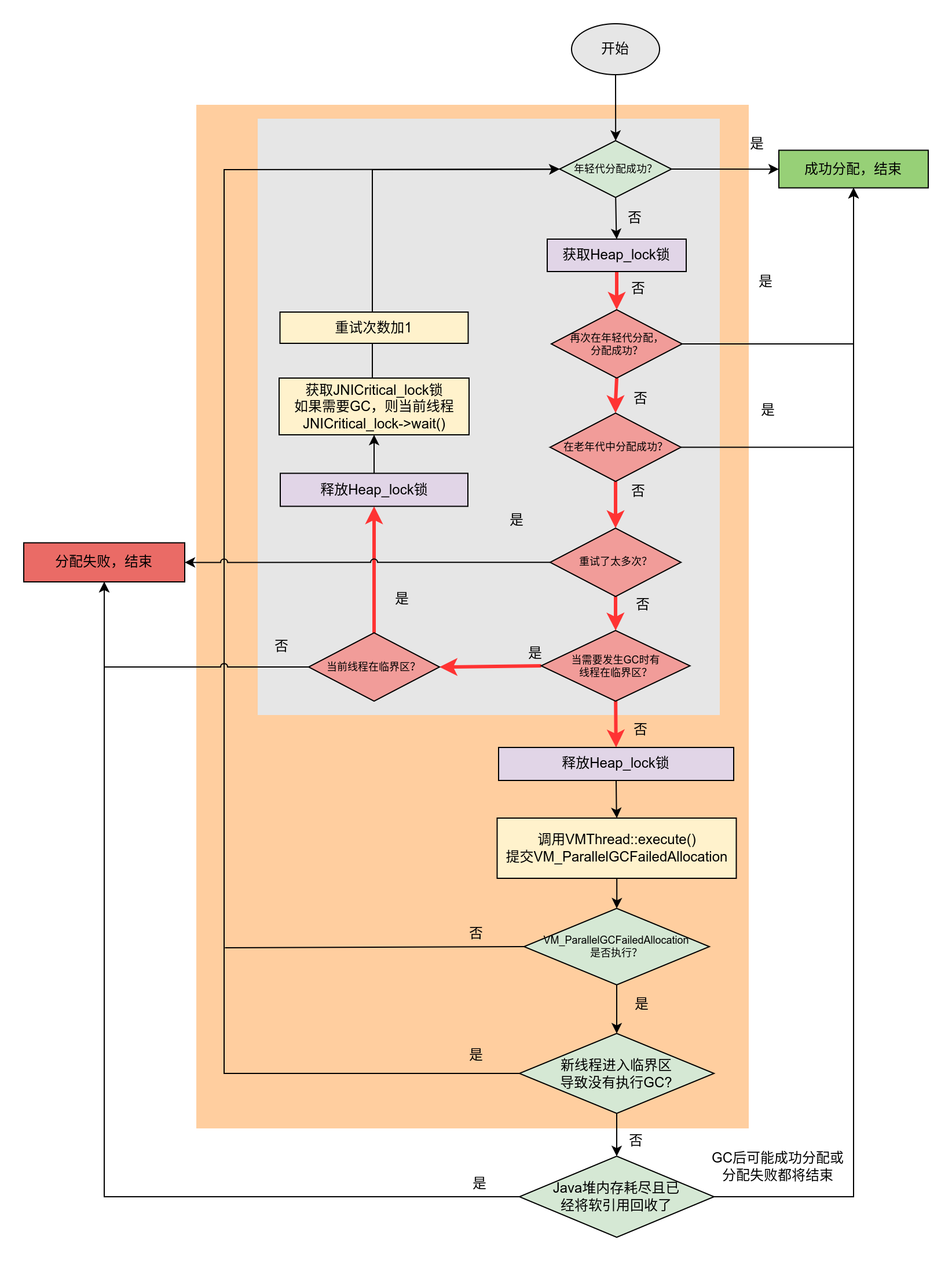
图中灰色背景表示内部循环,橙色背景表示外部循环。
这里我们要着重看一下对临界区的支持。由于临界区的扰乱,本来堆中内存吃紧,需要发生GC回收(_needs_gc的值为true)的时候,有线程却在临界区内阻塞了GC回收,此时当前要提交GC任务的业务线程就只能等待在JNICritical_lock锁上。
之前在没有支持临界区时,分配内存失败的线程都阻塞在Heap_lock互斥锁上。
GC_locker::stall_until_clear()函数的实现如下:
void GC_locker::stall_until_clear() {
assert(!JavaThread::current()->in_critical(), "Would deadlock");
MutexLocker ml(JNICritical_lock);
while (needs_gc()) {
JNICritical_lock->wait();
}
}
上图中灰色背景表示内部循环,这个循环就是因为临界区扰乱,所以需要等待,当临界区最后一个线程触发GC任务完成后,会调用JNICritical_lock->notify_all()通过这些业务线程重新进行内存分配等尝试。
完整的VMThread::execute()函数的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/runtime/vmThread.cpp
void VMThread::execute(VM_Operation* op) {
Thread* t = Thread::current();
if (!t->is_VM_thread()) {
// 对于Parallel GC来说,concurrent的值为false
bool concurrent = op->evaluate_concurrently();
// 在doit_prologue()中获取Heap_lock锁
if (!op->doit_prologue()) {
return;
}
// 设置提交当前任务的线程
op->set_calling_thread(t, Thread::get_priority(t));
// 对于Parallel GC来说,返回true
bool execute_epilog = !op->is_cheap_allocated();
// 生成ticket,辅助判断提交的任务是否执行完成
int ticket = 0;
if (!concurrent) {
ticket = t->vm_operation_ticket();
}
{
// 操作_vm_queue队列时必须要获取VMOperationQueue_lock锁,GC线程等待在
// 这个锁上,如果GC线程获取到这个锁,会尝试获取其中的任务
VMOperationQueue_lock->lock_without_safepoint_check();
bool ok = _vm_queue->add(op); // 向队列中加入新的任务
// 唤醒VMThread线程,执行队列中的任务
VMOperationQueue_lock->notify();
VMOperationQueue_lock->unlock();
}
if (!concurrent) {
// 当前的JavaThread必须等待任务执行完成后的结果
MutexLocker mu(VMOperationRequest_lock);
// 当Thread::_vm_operation_started_count的值大于等于ticket时,表示
// 提交的任务已经执行完成,JavaThread不必等待,可以开始运行了
while(t->vm_operation_completed_count() < ticket) {
VMOperationRequest_lock->wait(!t->is_Java_thread());
}
}
// 在doit_epilogue()中释放Heap_lock锁
if (execute_epilog) {
op->doit_epilogue();
}
}
...
}
大概的流程如下图所示。
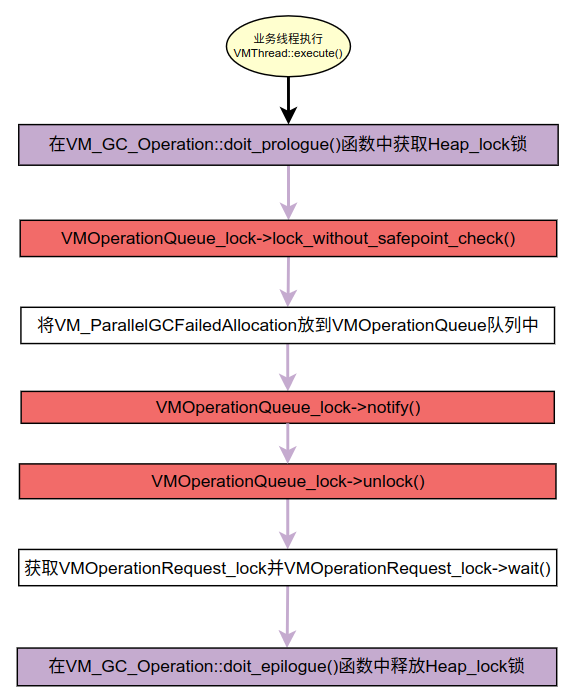
在向队列提交任务后,当前线程需要在VMOperationRequest_lock上等待,直到GC线程执行完成后会调用VMoperationRequest_lock的notifyAll()进行通知。
对于Parallel GC来说,其VM_ParallelGCFailedAllocation并非concurrent,执行的doit_prologue()函数的实现如下:
bool VM_GC_Operation::doit_prologue() {
// 获取Heap_lock锁
Heap_lock->lock();
if (skip_operation()) {
// 当某些原因导致当前的GC任务仍然不能提交到队列时,及时释放Heap_lock锁
Heap_lock->unlock();
_prologue_succeeded = false;
} else {
_prologue_succeeded = true;
SharedHeap* sh = SharedHeap::heap();
if (sh != NULL)
sh->_thread_holds_heap_lock_for_gc = true;
}
return _prologue_succeeded;
}
_prologue_succeeded値返回true时会提交GC操作,否则可能由于临界区等原因没办法提交GC操作。
bool VM_GC_Operation::skip_operation() const {
// 在ParallelScavengeHeap::mem_allocate()函数中获取的_gc_count_before,当这个值不相等时,
// 说明已经有线程提交了GC操作并执行了GC
bool skip = (_gc_count_before != Universe::heap()->total_collections());
if (_full && skip) {
skip = (_full_gc_count_before != Universe::heap()->total_full_collections());
}
// 有必要触发执行GC,但是有线程在临界区
if (!skip && GC_locker::is_active_and_needs_gc()) {
// 如果Java对象分配堆区已到达无需垃圾回收即可达到的最大提交内存上限,则返回true
skip = Universe::heap()->is_maximal_no_gc();
assert(!(skip && (_gc_cause == GCCause::_gc_locker)), "GC_locker cannot be active when initiating GC");
}
return skip;
}
不得不说,从最初最简单的功能需求开始,由于需要高性能、也需要一些特性的支持,最终导致代码变的复杂且难以理解,尤其是临界区特性的支持(这其实也是为了性能),为了性能,不能加过多的互斥锁,只能是用一些变量加Critical_lock互斥锁来协调临界区线程、提交GC任务的线程和VMThread后台线程。这样复杂的代码对后来的开发者极不友好,并且也非常容易引入Bug。

Java虚拟机代码是如何一步一步变复杂且难以理解的?的更多相关文章
- 【深入理解JAVA虚拟机】第三部分.虚拟机执行子系统.1.类文件结构
无关性 无关性的体现有两个方面: 1.平台无关性:可在不同的操作系统和机器指令集上执行,可在不同厂商的虚拟机平台上执行. 2.语言无关性:用不同编程语言写出的代码编译生成的文件都可以运行. 实现思想: ...
- 《深入理解java虚拟机-高效并发》读书笔记
Java内存模型与线程 概述 多任务处理在现代计算机操作系统中几乎已是一项必备的功能,多任务运行是压榨手段,就如windows一样,我们使劲的压榨它运行多个任务,俱要high又要耍.并发则是另外一种更 ...
- Java虚拟机--垃圾收集
Java虚拟机 1. JVM运行时数据区域 参考书籍:<深入理解Java虚拟机:JVM高级特性与最佳实践,第二版> 资料参考:http://blog.csdn.net/nms312/art ...
- JVM规范系列第3章:为Java虚拟机编译
Oracle 的 JDK 包括两部分内容:一部分是将 Java 源代码编译成 Java 虚拟机的指令集的编译器,另一部分是用于Java 虚拟机的运行时环境. 第一部分应该说的是 Javac 这个前置编 ...
- 翻译Java虚拟机的结构
英文原版: https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html 直接谷歌翻译: Java SE规范 > Java虚拟机 ...
- Java虚拟机,类文件结构深度解析
Java类文件结构 Java虚拟机不和包括Java在内的任何语言绑定,只与 "Class文件" 这种特定的二进制文件所关联, Class文件中包含了Java虚拟机指令集合符号表以及 ...
- 如何设置java虚拟机参数
这两天在看java虚拟机,从书上看到可以自己设置java虚拟机的参数,可以方便开发人员进行系统调优和故障排查 Ecplise设置java虚拟机参数: window-->preferences-- ...
- 深入理解Java虚拟机——读书笔记
首先 强烈推荐周志明老师的这本书,真的可以说是(起码中文出版界)新手了解Java虚拟机必须人手一本的教科书!!! 第二部分自动内存管理机制 由于Java虚拟机的多线程是通过线程轮流切换并分配处理器 ...
- java虚拟机规范(se8)——class文件格式(五)
4.7.1 定义和命名新属性 允许编译器定义和发布的class文件在class文件结构体.field_info结构体.method_info结构体和Code结构体中的attributes表中包含新的属 ...
- java虚拟机规范(se8)——java虚拟机的编译(四)
3.12 抛出和处理异常 在程序中使用throw关键字来抛出异常.编译结果很简单. void cantBeZero(int i) throws TestExc { if (i == 0) { thro ...
随机推荐
- Janus Pro:DeepSeek 开源革新,多模态 AI 的未来
Janus Pro 是 DeepSeek 开发的一个开源多模态人工智能框架,它通过集成视觉和语言处理能力,提供了高性能的多模态任务处理能力. 在线体验: https://deepseek-janusp ...
- [业界方案] 智能运维AIOps-学习笔记
[业界方案] 智能运维-学习笔记 目录 [业界方案] 智能运维-学习笔记 0x00 摘要 0x01 AIOps 背景 1.1 AIOps概述 1.2 AIOps场景 1.3 AIOps能力 1.4 A ...
- 镇海-APIO联合总结
镇海考试见此处:https://www.cnblogs.com/british-union/p/liankao.html 考的是湖南省队集训,除了第一天有点头昏导致体验很差之外体验非常好,剩下两次考试 ...
- Centos 7 安装Redis5 详细步骤 备忘录笔记
通过wget下载tar包 wget http://download.redis.io/releases/redis-5.0.5.tar.gz 解压包 tar -zxvf redis-5.0.5.tar ...
- PPT革命!DeepSeek+Kimi=N小时工作5分钟完成?
在之前的三篇文章中,笔者介绍了有关DeepSeek的基础操作,满足了不同类型的用户需求. 想利用大模型构建属于自己的智能知识库,无论你是想私有化部署,还是直接使用API调用,都可以在这三篇文章中找到答 ...
- Log4j2 中三种常见 File 类 Appender 对比与选择
在 Log4j2 中,若不考虑 Rolling(支持滚动和压缩)类文件 Appender,则包含以下三种文件 Appender:FileAppender.RandomAccessFileAppende ...
- 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
FRP 是 Github 上开源的一款内网穿透工具,点击前往项目地址,该项目分为 frps 服务端和 frpc 客户端,通过在拥有公网 IP 的服务器上搭建服务端,然后在被穿透的机器上安装客户端,配置 ...
- mongodb logical sessions can't have multiple authenticated users
前言 使用 mongodb db.auth,切换用户时,报以下错误 logical sessions can't have multiple authenticated users 原因是 mongo ...
- $GOPATH/go.mod exists but should not
开启模块支持后,并不能与GOPATH共存,所以把项目从GOPATH中移出即可
- 编写你的第一个 Django 应用程序,第4部分
本教程从教程 3 停止的地方开始.我们是 继续民意调查应用程序,并将专注于表单处理和 减少我们的代码. 一.编写最小表单 让我们更新上一个教程的投票详细信息模板("polls/detail. ...