pytorch入门 - AlexNet神经网络
AlexNet背景
AlexNet是2012年由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton提出的深度卷积神经网络架构。
它在ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了突破性成绩,将top-5错误率从26%降低到了15.3%,这一成就标志着深度学习在计算机视觉领域的崛起。
AlexNet的成功主要归功于以下几个创新点:
- 使用ReLU(Rectified Linear Unit)作为激活函数,解决了传统Sigmoid/Tanh激活函数在深层网络中的梯度消失问题
- 采用Dropout技术减少全连接层的过拟合
- 使用重叠的最大池化(max pooling)代替传统平均池化,提升了特征不变性
- 首次在CNN中成功应用GPU加速训练,使得训练大规模深层网络成为可能
AlexNet的出现开启了深度学习在计算机视觉领域的新纪元,为后续各种CNN架构(如VGG、ResNet等)的发展奠定了基础。
AlexNet架构
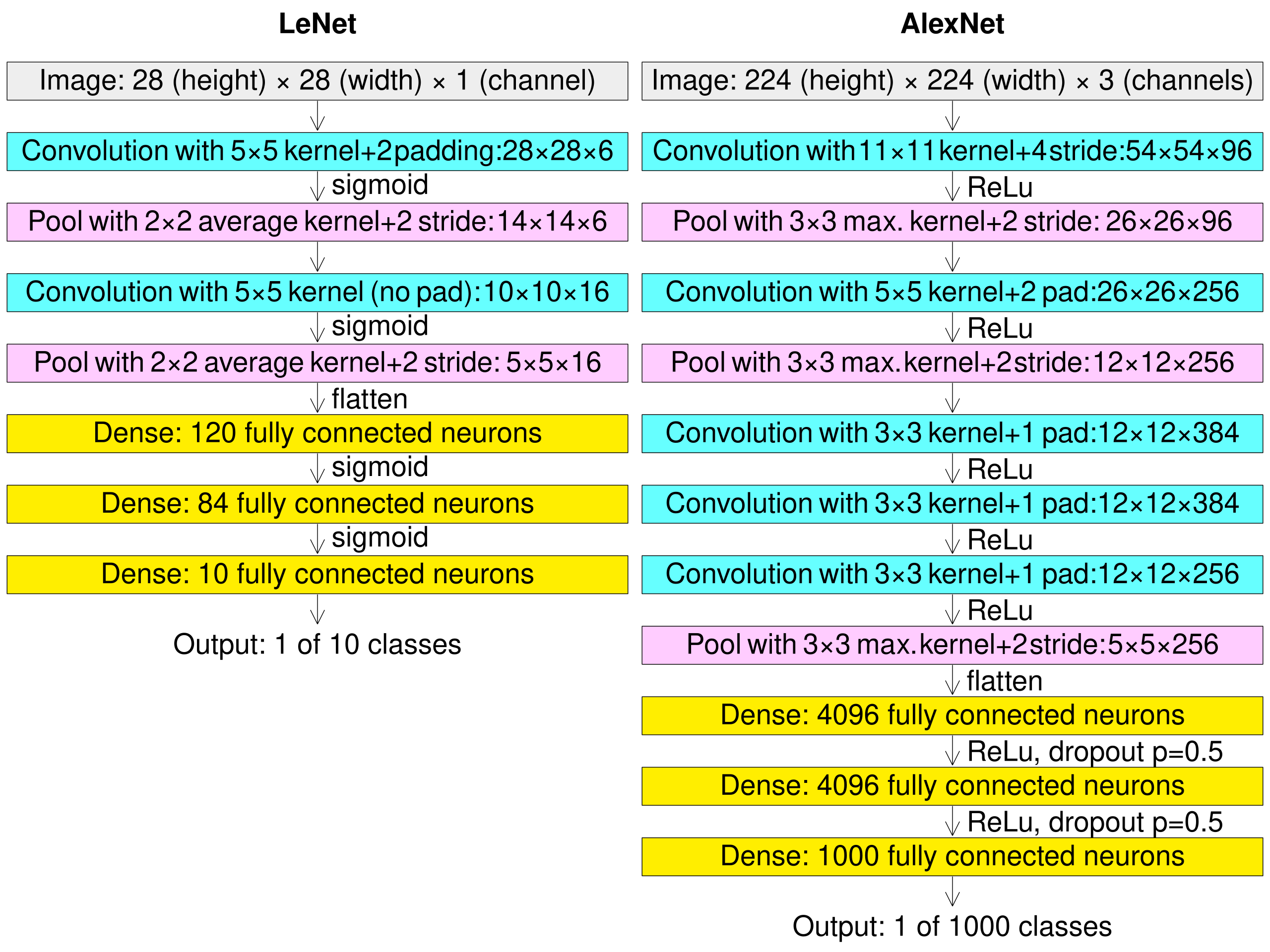
AlexNet原始架构包含8个学习层 - 5个卷积层和3个全连接层。下面是详细的架构描述:
- 输入层:接受224×224×3的RGB图像(在FashionMNIST中调整为227×227×1的灰度图像)
- 卷积层1:96个11×11的卷积核,步长4,使用ReLU激活
- 最大池化层1:3×3池化窗口,步长2
- 卷积层2:256个5×5的卷积核,padding=2,使用ReLU激活
- 最大池化层2:3×3池化窗口,步长2
- 卷积层3:384个3×3的卷积核,padding=1,使用ReLU激活
- 卷积层4:384个3×3的卷积核,padding=1,使用ReLU激活
- 卷积层5:256个3×3的卷积核,padding=1,使用ReLU激活
- 最大池化层3:3×3池化窗口,步长2
- 全连接层1:4096个神经元,使用ReLU激活,Dropout=0.5
- 全连接层2:4096个神经元,使用ReLU激活,Dropout=0.5
- 全连接层3(输出层):1000个神经元(在FashionMNIST中调整为10个)
参数计算详解
让我们详细计算AlexNet每一层的参数数量:
卷积层1:
- 输入:227×227×1
- 96个11×11卷积核
- 参数数量 = (11×11×1 + 1偏置)×96 = 11,712
卷积层2:
- 输入:27×27×96 (经过池化后尺寸)
- 256个5×5卷积核
- 参数数量 = (5×5×96 + 1)×256 = 614,656
卷积层3:
- 输入:13×13×256
- 384个3×3卷积核
- 参数数量 = (3×3×256 + 1)×384 = 885,120
卷积层4:
- 输入:13×13×384
- 384个3×3卷积核
- 参数数量 = (3×3×384 + 1)×384 = 1,327,488
卷积层5:
- 输入:13×13×384
- 256个3×3卷积核
- 参数数量 = (3×3×384 + 1)×256 = 884,992
全连接层1:
- 输入:6×6×256 = 9216
- 输出:4096
- 参数数量 = (9216 + 1)×4096 = 37,752,832
全连接层2:
- 输入:4096
- 输出:4096
- 参数数量 = (4096 + 1)×4096 = 16,781,312
全连接层3:
- 输入:4096
- 输出:10(FashionMNIST)
- 参数数量 = (4096 + 1)×10 = 40,970
总参数数量约为6000万(原始AlexNet),在FashionMNIST上约为5800万。
代码实现解析
模型实现代码(model.py)
import os
import sys
sys.path.append(os.getcwd())
import torch # 导入PyTorch主库
from torch import nn # 从torch中导入神经网络模块
from torchsummary import summary # 导入torchsummary用于模型结构总结
import torch.nn.functional as F # 导入PyTorch的函数式API,常用于激活函数、dropout等
class AlexNet(nn.Module): # 定义AlexNet模型,继承自nn.Module
def __init__(self): # 构造函数,初始化网络结构
super(AlexNet, self).__init__() # 调用父类的构造函数
self.ReLU = nn.ReLU() # 定义ReLU激活函数,后续多次复用
self.conv1 = nn.Conv2d(
in_channels=1, out_channels=96, stride=4, kernel_size=11
) # 第一层卷积,输入通道1,输出通道96,步幅4,卷积核11x11
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2) # 第一层池化,3x3窗口,步幅2
self.conv2 = nn.Conv2d(
in_channels=96, out_channels=256, stride=1, kernel_size=5, padding=2
) # 第二层卷积,输入96通道,输出256通道,5x5卷积核,padding=2
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2) # 第二层池化,3x3窗口,步幅2
self.conv3 = nn.Conv2d(
in_channels=256, out_channels=384, stride=1, kernel_size=3, padding=1
) # 第三层卷积,输入256通道,输出384通道,3x3卷积核,padding=1
self.conv4 = nn.Conv2d(
in_channels=384, out_channels=384, stride=1, kernel_size=3, padding=1
) # 第四层卷积,输入384通道,输出384通道,3x3卷积核,padding=1
self.conv5 = nn.Conv2d(
in_channels=384, out_channels=256, stride=1, kernel_size=3, padding=1
) # 第五层卷积,输入384通道,输出256通道,3x3卷积核,padding=1
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2) # 第三层池化,3x3窗口,步幅2
self.flatten = nn.Flatten() # 展平层,将多维输入展平成一维
self.fc1 = nn.Linear(
in_features=256 * 6 * 6, out_features=4096
) # 第一个全连接层,输入256 * 6 * 6,输出4096
self.fc2 = nn.Linear(
in_features=4096, out_features=4096
) # 第二个全连接层,输入4096,输出4096
self.fc3 = nn.Linear(
in_features=4096, out_features=10
) # 第三个全连接层,输入4096,输出10(假设10分类)
def forward(self, x): # 定义前向传播过程
x = self.conv1(x) # 输入通过第一层卷积
x = self.ReLU(x) # 激活
x = self.pool1(x) # 池化
x = self.conv2(x) # 第二层卷积
x = self.ReLU(x) # 激活
x = self.pool2(x) # 池化
x = self.conv3(x) # 第三层卷积
x = self.ReLU(x) # 激活
x = self.conv4(x) # 第四层卷积
x = self.ReLU(x) # 激活
x = self.conv5(x) # 第五层卷积
x = self.ReLU(x) # 激活
x = self.pool3(x) # 池化
x = self.flatten(x) # 展平为一维向量
x = self.fc1(x) # 第一个全连接层
x = self.ReLU(x) # 激活
x = F.dropout(x, p=0.5) # dropout防止过拟合,丢弃概率0.5
x = self.fc2(x) # 第二个全连接层
x = self.ReLU(x) # 激活
x = F.dropout(x, p=0.5) # dropout防止过拟合,丢弃概率0.5
x = self.fc3(x) # 第三个全连接层,输出最终结果
return x # 返回输出
if __name__ == "__main__": # 如果作为主程序运行
model = AlexNet() # 实例化AlexNet模型
print(model) # 打印模型结构
summary(
model, input_size=(1, 227, 227), device="cpu"
) # 打印模型摘要,输入尺寸为(1, 227, 227),单通道训练代码(train.py)
import os # 导入os模块,用于与操作系统交互
import sys # 导入sys模块,用于操作Python运行时环境
sys.path.append(os.getcwd()) # 将当前工作目录添加到sys.path,方便模块导入
import time # 导入time模块,用于计时
from torchvision.datasets import FashionMNIST # 导入FashionMNIST数据集
from torchvision import transforms # 导入transforms用于数据预处理
from torch.utils.data import (
DataLoader, # 导入DataLoader用于批量加载数据
random_split, # 导入random_split用于划分数据集
)
import numpy as np # 导入numpy用于数值计算
import matplotlib.pyplot as plt # 导入matplotlib用于绘图
import torch # 导入PyTorch主库
from torch import nn, optim # 导入神经网络模块和优化器
import copy # 导入copy模块用于深拷贝
import pandas as pd # 导入pandas用于数据处理
from AlexNet_model.model import AlexNet # 从自定义模块导入AlexNet模型
def train_val_date_load(): # 定义函数用于加载训练集和验证集
train_dataset = FashionMNIST(
root="./data", # 数据存储路径
train=True, # 加载训练集
download=True, # 如果数据不存在则下载
transform=transforms.Compose(
[
transforms.Resize(size=227), # 将图片缩放到227x227
transforms.ToTensor(), # 转换为Tensor
]
),
)
train_date, val_data = random_split(
train_dataset,
[
int(len(train_dataset) * 0.8), # 80%作为训练集
len(train_dataset) - int(len(train_dataset) * 0.8), # 剩余20%作为验证集
],
)
train_loader = DataLoader(
dataset=train_date,
batch_size=32,
shuffle=True,
num_workers=1, # 训练集加载器,批量32,打乱顺序
)
val_loader = DataLoader(
dataset=val_data,
batch_size=32,
shuffle=True,
num_workers=1, # 验证集加载器,批量32,打乱顺序
)
return train_loader, val_loader # 返回训练集和验证集加载器
def train_model_process(model, train_loader, val_loader, epochs=10): # 定义训练过程函数
device = "cuda" if torch.cuda.is_available() else "cpu" # 判断是否有GPU可用
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率0.001
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
model.to(device) # 将模型移动到指定设备
best_model_wts = copy.deepcopy(model.state_dict()) # 保存最佳模型参数
best_acc = 0.0 # 初始化最佳准确率
train_loss_all = [] # 记录每轮训练损失
val_loss_all = [] # 记录每轮验证损失
train_acc_all = [] # 记录每轮训练准确率
val_acc_all = [] # 记录每轮验证准确率
since = time.time() # 记录训练开始时间
for epoch in range(epochs): # 遍历每个训练轮次
print(f"Epoch {epoch + 1}/{epochs}") # 打印当前轮次信息
train_loss = 0.0 # 当前轮训练损失
train_correct = 0 # 当前轮训练正确样本数
val_loss = 0.0 # 当前轮验证损失
val_correct = 0 # 当前轮验证正确样本数
train_num = 0 # 当前轮训练样本总数
val_num = 0 # 当前轮验证样本总数
for step, (images, labels) in enumerate(train_loader): # 遍历训练集
images = images.to(device) # 将图片移动到设备
labels = labels.to(device) # 将标签移动到设备
model.train() # 设置模型为训练模式
outputs = model(images) # 前向传播,获取输出
pre_lab = torch.argmax(outputs, dim=1) # 获取预测标签
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_loss += loss.item() * images.size(0) # 累加损失
train_correct += torch.sum(pre_lab == labels.data) # 累加正确预测数
train_num += labels.size(0) # 累加样本数
for step, (images, labels) in enumerate(val_loader): # 遍历验证集
images = images.to(device) # 将图片移动到设备
labels = labels.to(device) # 将标签移动到设备
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 关闭梯度计算
outputs = model(images) # 前向传播
pre_lab = torch.argmax(outputs, dim=1) # 获取预测标签
loss = criterion(outputs, labels) # 计算损失
val_loss += loss.item() * images.size(0) # 累加损失
val_correct += torch.sum(pre_lab == labels.data) # 累加正确预测数
val_num += labels.size(0) # 累加样本数
train_loss_all.append(train_loss / train_num) # 记录本轮平均训练损失
val_loss_all.append(val_loss / val_num) # 记录本轮平均验证损失
train_acc = train_correct.double() / train_num # 计算本轮训练准确率
val_acc = val_correct.double() / val_num # 计算本轮验证准确率
train_acc_all.append(train_acc.item()) # 记录训练准确率
val_acc_all.append(val_acc.item()) # 记录验证准确率
print(
f"Train Loss: {train_loss / train_num:.4f}, Train Acc: {train_acc:.4f}, "
f"Val Loss: {val_loss / val_num:.4f}, Val Acc: {val_acc:.4f}"
) # 打印本轮损失和准确率
if val_acc_all[-1] > best_acc: # 如果本轮验证准确率更高
best_acc = val_acc_all[-1] # 更新最佳准确率
best_model_wts = copy.deepcopy(model.state_dict()) # 保存最佳模型参数
# model.load_state_dict(best_model_wts) # 可选:恢复最佳模型参数
time_elapsed = time.time() - since # 计算训练总耗时
print(
f"Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s\n"
f"Best val Acc: {best_acc:.4f}"
) # 打印训练耗时和最佳准确率
torch.save(model.state_dict(), "./models/alex_net_best_model.pth") # 保存模型参数
train_process = pd.DataFrame(
data={
"epoch": range(1, epochs + 1), # 轮次
"train_loss_all": train_loss_all, # 训练损失
"val_loss_all": val_loss_all, # 验证损失
"train_acc_all": train_acc_all, # 训练准确率
"val_acc_all": val_acc_all, # 验证准确率
}
) # 构建训练过程数据表
return train_process # 返回训练过程数据
def matplot_acc_loss(train_process): # 定义绘图函数
plt.figure(figsize=(12, 5)) # 创建画布,设置大小
plt.subplot(1, 2, 1) # 激活第1个子图
plt.plot(
train_process["epoch"], train_process["train_loss_all"], label="Train Loss"
) # 绘制训练损失曲线
plt.plot(
train_process["epoch"], train_process["val_loss_all"], label="Val Loss"
) # 绘制验证损失曲线
plt.xlabel("Epoch") # 设置x轴标签
plt.ylabel("Loss") # 设置y轴标签
plt.title("Loss vs Epoch") # 设置子图标题
plt.legend() # 显示图例
plt.subplot(1, 2, 2) # 激活第2个子图
plt.plot(
train_process["epoch"], train_process["train_acc_all"], label="Train Acc"
) # 绘制训练准确率曲线
plt.plot(
train_process["epoch"], train_process["val_acc_all"], label="Val Acc"
) # 绘制验证准确率曲线
plt.xlabel("Epoch") # 设置x轴标签为Epoch
plt.ylabel("Accuracy") # 设置y轴标签为Accuracy
plt.title("Accuracy vs Epoch") # 设置子图标题
plt.legend() # 显示图例
plt.tight_layout() # 自动调整子图间距
plt.ion() # 关闭交互模式,防止图像自动关闭
plt.show() # 显示所有图像
plt.savefig("./models/alex_net_output.png") # 保存图片到指定路径
if __name__ == "__main__": # 如果当前脚本作为主程序运行
traindatam, valdata = train_val_date_load() # 加载训练集和验证集
result = train_model_process(
AlexNet(), traindatam, valdata, 10
) # 训练模型并获取训练过程数据
matplot_acc_loss(result) # 绘制训练和验证的损失及准确率曲线测试代码(test.py)
import os # 导入os模块,用于与操作系统交互
import sys # 导入sys模块,用于操作Python运行时环境
sys.path.append(os.getcwd()) # 将当前工作目录添加到sys.path,方便模块导入
import torch # 导入PyTorch主库
from torch.utils.data import (
DataLoader, # 导入DataLoader用于批量加载数据
random_split, # 导入random_split用于划分数据集(本文件未用到)
)
from torchvision import datasets, transforms # 导入torchvision的数据集和数据变换模块
from torchvision.datasets import FashionMNIST # 导入FashionMNIST数据集
from AlexNet_model.model import AlexNet # 从自定义模块导入AlexNet模型
def test_data_load(): # 定义测试数据加载函数
test_dataset = FashionMNIST(
root="./data", # 数据存储路径
train=False, # 加载测试集
download=True, # 如果数据不存在则下载
transform=transforms.Compose(
[
transforms.Resize(size=227), # 将图片缩放到227x227
transforms.ToTensor(), # 转换为Tensor
]
),
)
test_loader = DataLoader(
dataset=test_dataset, batch_size=128, shuffle=True, num_workers=1 # 测试集加载器,批量128,打乱顺序
)
return test_loader # 返回测试集加载器
print(test_data_load()) # 打印测试集加载器(调试用)
def test_model_process(model, test_loader): # 定义模型测试过程
device = "cuda" if torch.cuda.is_available() else "cpu" # 判断是否有GPU可用
model.to(device) # 将模型移动到指定设备
model.eval() # 设置模型为评估模式
correct = 0 # 正确预测样本数
total = 0 # 总样本数
with torch.no_grad(): # 关闭梯度计算,加快推理速度
for images, labels in test_loader: # 遍历测试集
images, labels = images.to(device), labels.to(device) # 数据移动到设备
outputs = model(images) # 前向传播,获取输出
_, predicted = torch.max(outputs, 1) # 获取预测标签
total += labels.size(0) # 累加总样本数
correct += torch.sum(predicted == labels.data) # 累加正确预测数
accuracy = correct / total * 100 # 计算准确率(百分比)
print(f"Test Accuracy: {accuracy:.2f}%") # 打印测试准确率
if __name__ == "__main__": # 如果当前脚本作为主程序运行
test_loader = test_data_load() # 加载测试集
model = AlexNet() # 实例化AlexNet模型
model.load_state_dict(torch.load("./models/alex_net_best_model.pth")) # 加载训练好的模型参数
test_model_process(model, test_loader) # 测试模型并输出准确率总结
AlexNet作为深度学习在计算机视觉领域的里程碑式模型,具有以下重要特点和贡献:
- 架构创新:首次证明了深层卷积神经网络在大规模图像识别任务中的有效性
- 技术突破:引入了ReLU激活函数、Dropout、局部响应归一化等技术
- 硬件加速:开创性地使用GPU加速CNN训练,大幅缩短训练时间
- 开源影响:AlexNet的成功推动了深度学习开源框架的发展
尽管现在有更先进的CNN架构,AlexNet仍然是学习深度学习计算机视觉的经典案例。
通过本文的代码实现,我们可以在FashionMNIST数据集上复现AlexNet的基本架构,并理解其工作原理。
在实际应用中,AlexNet的一些设计已经过时,如大卷积核(11×11)被小卷积核(3×3)堆叠取代,全连接层被全局平均池化替代等。但理解AlexNet仍然是掌握现代CNN架构的重要基础。
pytorch入门 - AlexNet神经网络的更多相关文章
- Pytorch入门随手记
Pytorch入门随手记 什么是Pytorch? Pytorch是Torch到Python上的移植(Torch原本是用Lua语言编写的) 是一个动态的过程,数据和图是一起建立的. tensor.dot ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- 超简单!pytorch入门教程(五):训练和测试CNN
我们按照超简单!pytorch入门教程(四):准备图片数据集准备好了图片数据以后,就来训练一下识别这10类图片的cnn神经网络吧. 按照超简单!pytorch入门教程(三):构造一个小型CNN构建好一 ...
- pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- Pytorch入门上 —— Dataset、Tensorboard、Transforms、Dataloader
本节内容参照小土堆的pytorch入门视频教程.学习时建议多读源码,通过源码中的注释可以快速弄清楚类或函数的作用以及输入输出类型. Dataset 借用Dataset可以快速访问深度学习需要的数据,例 ...
- Pytorch入门中 —— 搭建网络模型
本节内容参照小土堆的pytorch入门视频教程,主要通过查询文档的方式讲解如何搭建卷积神经网络.学习时要学会查询文档,这样会比直接搜索良莠不齐的博客更快.更可靠.讲解的内容主要是pytorch核心包中 ...
- 第一章:PyTorch 入门
第一章:PyTorch 入门 1.1 Pytorch 简介 1.1.1 PyTorch的由来 1.1.2 Torch是什么? 1.1.3 重新介绍 PyTorch 1.1.4 对比PyTorch和Te ...
- [pytorch] Pytorch入门
Pytorch入门 简单容易上手,感觉比keras好理解多了,和mxnet很像(似乎mxnet有点借鉴pytorch),记一记. 直接从例子开始学,基础知识咱已经看了很多论文了... import t ...
随机推荐
- 记录一下 简单udp和sni 代理 done
由于之前借鉴 Kestrel 了非常多抽象和优化实现,对于后续的扩展非常便利, 实现 简单udp和sni 代理 两个功能比预期快了超多(当然也有偷懒因素) (PS 大家有空的话,能否在 GitHub ...
- golng切片实现分页
前言 实现切片分页,主要是根据选择页码和每页显示数量,计算了切片的开始.结束索引地址 package main import "math" func main() { slice1 ...
- Golang 入门 : 字符串及底层字符类型
字符串 基本使用 在 Go 语言中,字符串是一种基本类型,默认是通过 UTF-8 编码的字符序列,当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节,比如中文编码通常需 ...
- Joker 可视化开发平台全局方法使用指南
在 Joker 可视化开发平台中,全局方法是实现公共业务逻辑的有力工具,它能跨越组件和页面文件的界限,让开发者快速调用,显著提升开发效率.下面将详细介绍全局方法在平台中的使用方式. 一.全局方法的定义 ...
- 张高兴的大模型开发实战:(三)使用 LangGraph 为对话添加历史记录
目录 基础概念 环境搭建与配置 将对话历史存储至内存 将对话历史存储至 PostgreSQL 在构建聊天机器人时,对话历史记录是提升用户体验的核心功能之一,用户希望机器人能够记住之前的对话内容,从而避 ...
- 【Linux】5.6 Shell打印输出指令
Shell打印输出命令 1. echo命令 Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出.命令格式:echo string 您可以使用echo实现更复杂的输出 ...
- 【Linux】5.1 Shell简介
Shell简介 1. Shell基础 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言. Shell 是指一种应用程序,这 ...
- study python3【3】前人高度总结出来的不仅仅Pathon的语言习方法
这是前人写的学习python的经验体会.不单单python,all语言都是如此. 转自https://www.cnblogs.com/nokiaguy/p/9557996.html 感谢分享 下面正文 ...
- 基于注解的 AOP 配置
第一步:在 spring 配置文件中开启 spring 对注解 AOP 的支持 <!-- 开启 spring 对注解 AOP 的支持 --> <aop:aspectj-autopro ...
- Python日志模块Logging使用指北
Python日志模块Logging使用指北 作者:SkyXZ CSDN:SkyXZ--CSDN博客 博客园:SkyXZ - 博客园 Logging模块是Python中一个很重要的日志模块,它提供了灵活 ...