数栈技术分享:一文带你了解Flink jm、tm启动过程和资源分配

一、JM启动过程
1、从日志角度分析启动流程
1)client生成jobGraph
2)Yarn RM接收到请求(和yarn交互不重点分析)
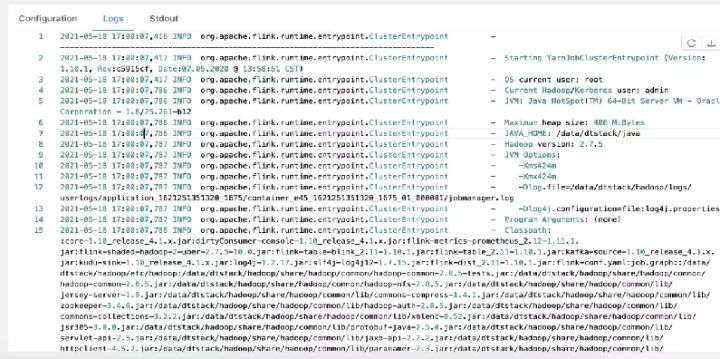
3)在被分配的节点上的工作目录下启动launch_container.sh
4)在perJob模式下,最终调用的是YarnJobClusterEntrypoint
5)初始化相关运行环境,打印软件版本、运行环境、命令行参数、classpath 等信息
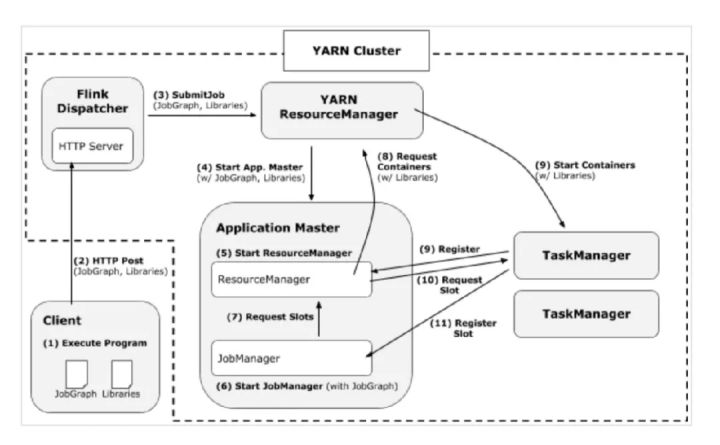 6)加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等)
6)加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等)
7)启动Flink资源管理核心组件ResourceManager(包含 YarnResourceManager 和 SlotManager 两个子组件)
8)启动Dispatcher加载JobGraph 文件、并启动JobManager
9)JobManager开始执行ExecutionGraph,向 ResourceManager申请资源
 10)Flink ResourceManager 接收到新分配的 Container 资源后,准备好 TaskManager 启动上下文
10)Flink ResourceManager 接收到新分配的 Container 资源后,准备好 TaskManager 启动上下文
11)TaskManager 进程加载并运行 YarnTaskExecutorRunner(Flink TaskManager入口类),初始化流程完成后启动 TaskExecutor(负责执行Task相关操作)
12)TaskExecutor向ResourceManager注册,向SlotManager汇报自己的 Slot 资源与状态
13)JobManager向TaskExecutor提交task,TaskExecutor启动新的线程运行Task
 2、整体流程分析
2、整体流程分析

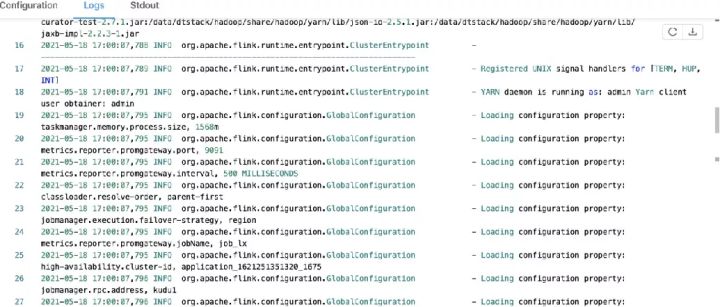
1)输出各软件版本及运行环境信息、命令行参数项、classpath等信息
2)注册处理各种SIGNAL的handler:记录到日志
3)注册JVM关闭保障的shutdown hook:避免JVM退出时被其他shutdown hook阻塞
4)打印YARN运行环境信息:用户名
5)从运行目录中加载flink conf
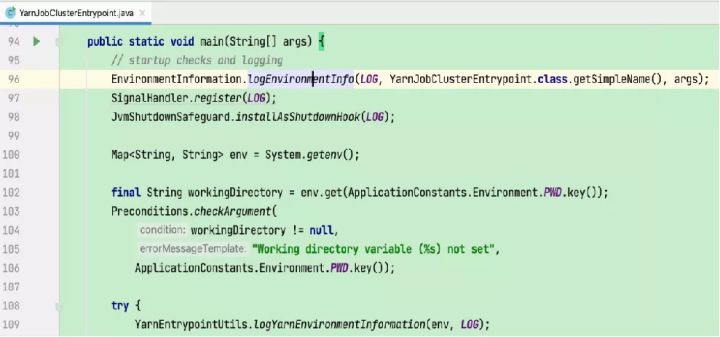
3、AM启动过程
1)创建并启动各类内部服务(包括RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore等)
2)将RPC address和port更新到flink conf配置
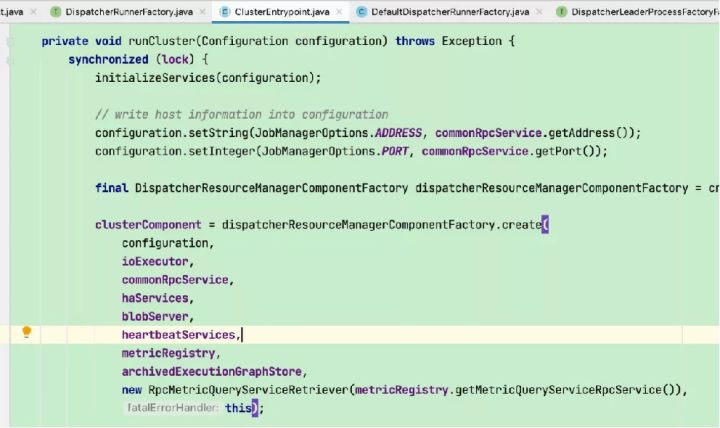
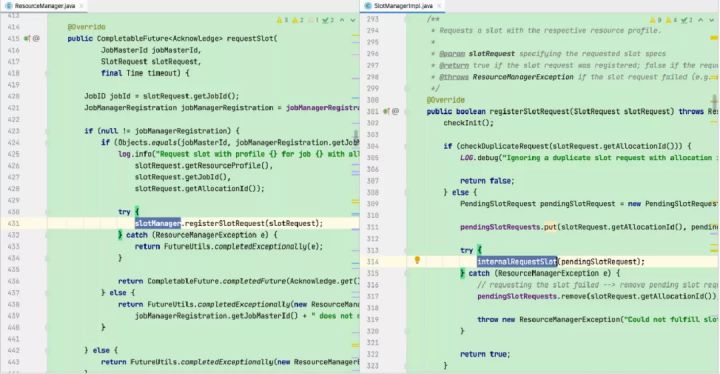
3)创建并启动resourceManager对象(Flink资源管理核心组件,包含YarnResourceManager和SlotManager两个子组件,YarnResourceManager负责外部资源管理,与YARN RM建立通信并保持心跳,申请或释放TaskManager资源,注销应用等;SlotManager则负责内部资源管理,维护全部Slot信息和状态)
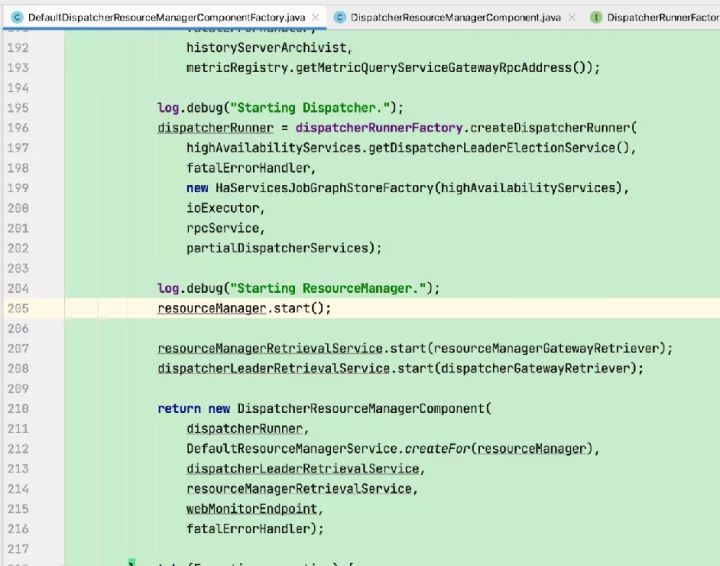
4)创建并启动dispatcher(负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager)及相关服务(包括REST endpoint等)并加载JobGraph。

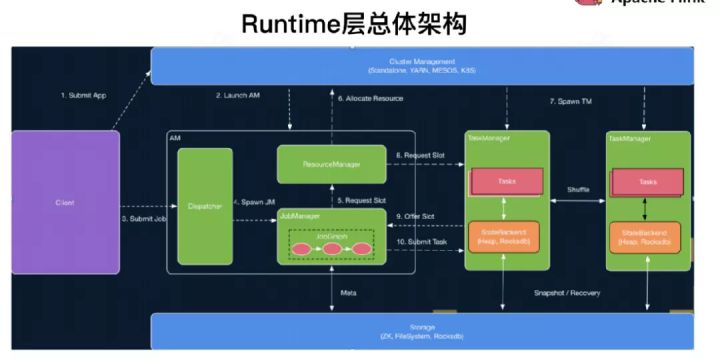
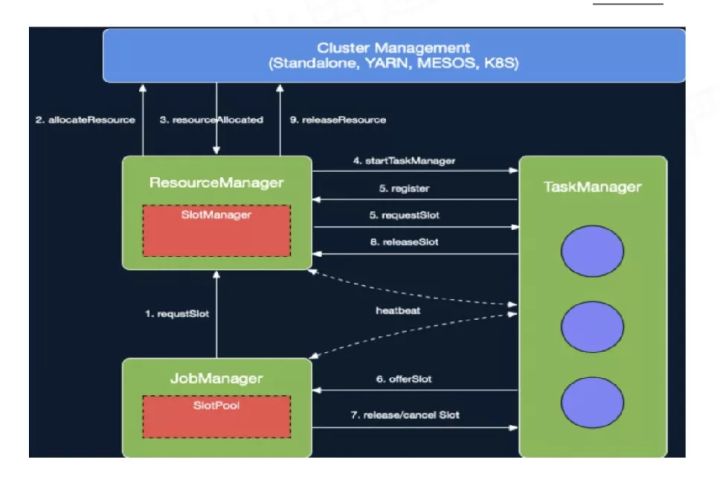
二、JM资源分配
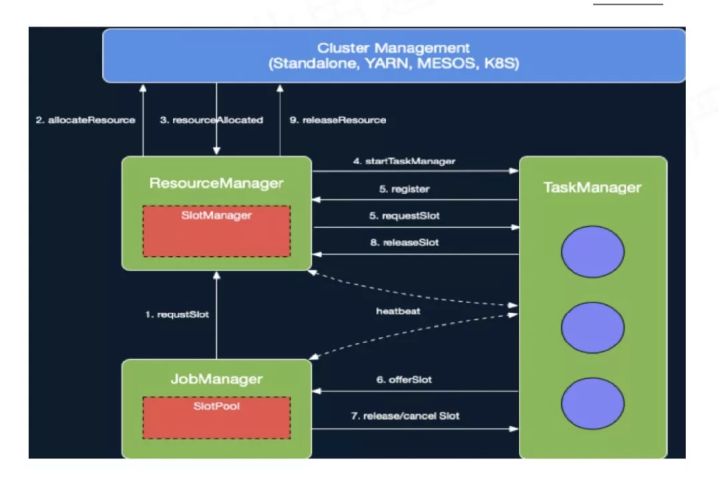
JobManager开始执行ExecutionGraph,向ResourceManager申请资源。
ResourceManager将资源请求加入等待请求队列,并通过心跳向YARN RM申请新的Container资源来启动TaskManager进程。
后续流程如果有空闲Slot资源,SlotManager将其分配给等待请求队列中匹配的请求,不用再通过YarnResourceManager申请新的TaskManager。
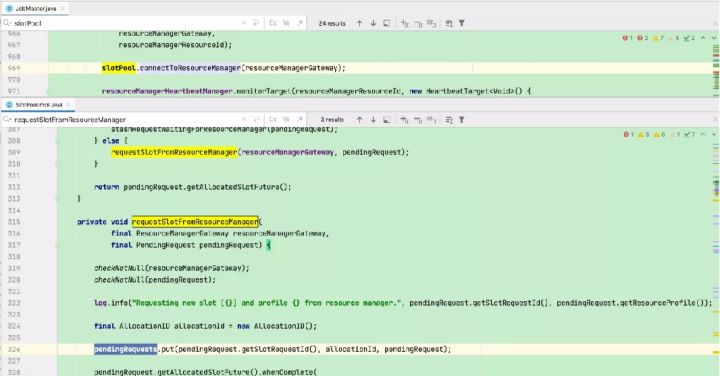
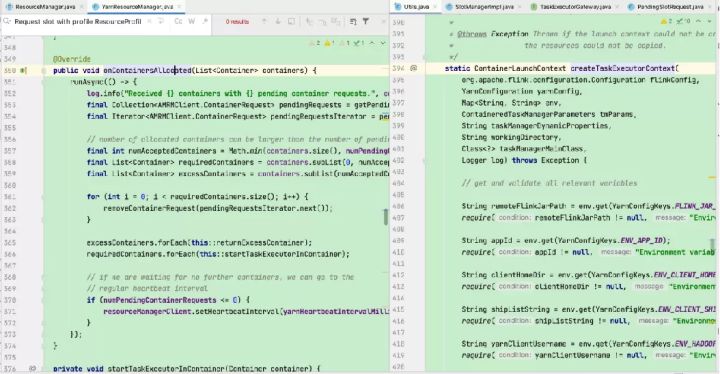
Flink ResourceManager接收到新分配的Container资源后,准备好TaskManager启动上下文(ContainerLauncherContext,生成TaskManager配置并上传至分布式存储,配置其他依赖和环境变量等)。
然后向YARN NM申请启动TaskManager进程,YARN NM启动Container的流程与AM Container启动流程基本类似。
三、TM启动过程
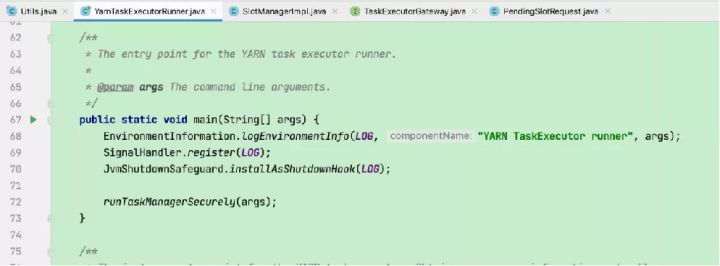
输出各软件版本及运行环境信息、命令行参数项、classpath等信息
注册处理各种SIGNAL的handler:记录到日志
注册JVM关闭保障的shutdown hook:避免JVM退出时被其他shutdown hook阻塞
加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry等)
启动tm后就可以通过RPC接收远程调用,submitTask就是接收任务的服务。
回到在JM端启动scheduler后,就开始调度Execution,在Execution的deploy()方法中通过rpc调用TM的submitTask接口。

交互流程图如下:
当submitTask收到请求后加载jobInformation和taskInformation文件,初始化jobInformation和taskInformation,然后构造Task,启动Task线程,最终调用AbstractInvokable.invoke方法。
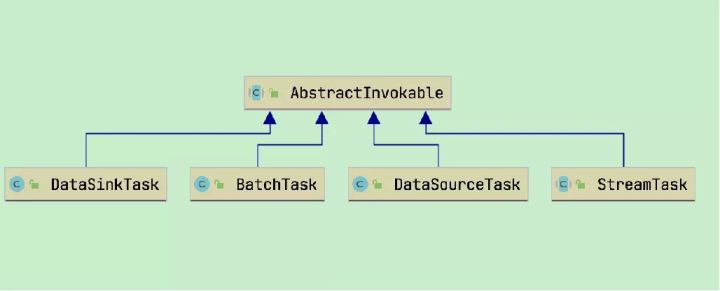
- invokable.invoke( )将根据nameOfInvokableClass的不同调度不同的任务,包括批任务、Source任务、Sink任务、流任务
- DataSourceTask:Kafka Source
- StreamTask:中间算子
- DataSinkTask:Kafka Sink
这里以StreamTask例分析
- 初始化、run、close
- 初始化:创建状态后端、operator配置、特殊task初始化、恢复算子的状态、richfunction open
- run:执行task,处理record并发往下游
- close:关闭和清理操作
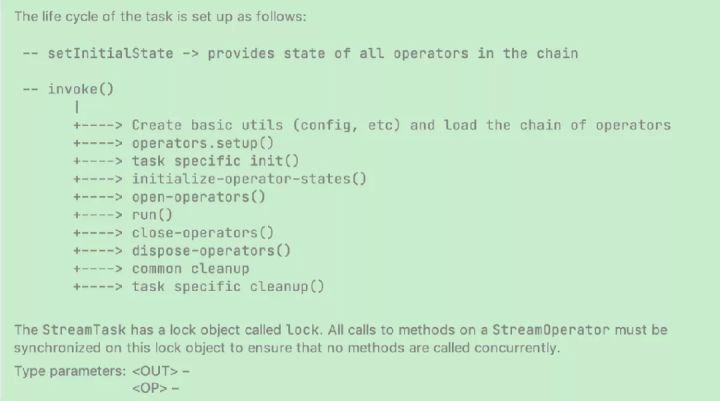
这里以flinkX中的代码为例:
会被invoke()中的initialize-operator-states()执行并调用到DtInputFormatSourceFunction的initializeState方法恢复状态。
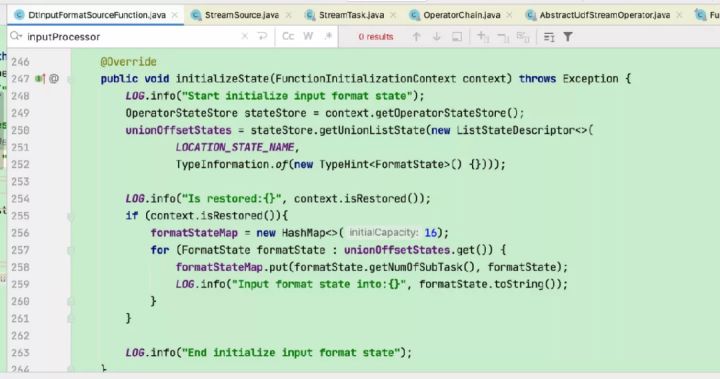
这里以flinkX中的代码为例:
会被invoke()中的open-operators()执行并调用到DtInputFormatSourceFunction的open方法恢复状态做一些初始化工作。
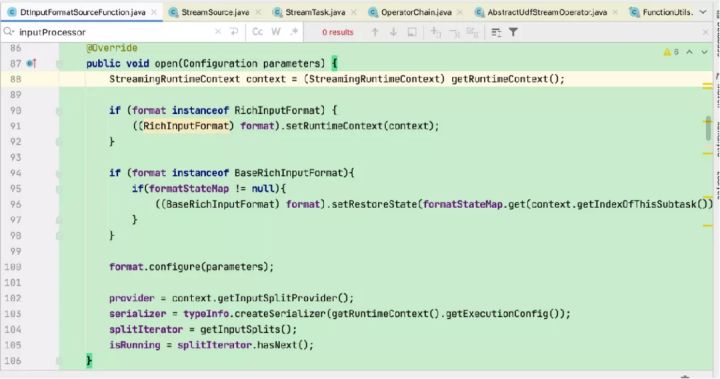
这里以flinkX中的代码为例:
会被invoke()中的run()执行并调用到DtInputFormatSourceFunction的run读取数据并往下游发送。
 经过上面分析,任务已经启动,并等待数据流动。
经过上面分析,任务已经启动,并等待数据流动。
相关参考:
https://zhuanlan.zhihu.com/p/87132673https://zhuanlan.zhihu.com/p/87132673
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
数栈技术分享:一文带你了解Flink jm、tm启动过程和资源分配的更多相关文章
- 一文带你了解 Flink Forward 柏林站全部重点内容
前言 2019.10.7~9号,随着70周年国庆活动的顺利闭幕,Flink Forward 也照例在他们的发源地柏林举办了第五届大会.虽然还没有拿到具体的数据,不过从培训门票已经在会前销售一空的这样的 ...
- 【凯子哥带你学Framework】Activity启动过程全解析
It’s right time to learn Android’s Framework ! 前言 学习目标 写作方式 主要对象功能介绍 主要流程介绍 zygote是什么有什么作用 SystemSer ...
- 【转载】【凯子哥带你学Framework】Activity启动过程全解析
It's right time to learn Android's Framework ! 前言 一个App是怎么启动起来的? App的程序入口到底是哪里? Launcher到底是什么神奇的东西? ...
- 一文带你了解 Flink 的基本组件栈
作为实时计算领域的佼佼者,Flink 的基本组件同样值得我们仔细研究. Flink 同样遵循着分层的架构设计理念,在降低系统耦合的同时,也为上层用户构建 Flink 应用提供了丰富且友好的接口. Fl ...
- 《手把手教你》系列技巧篇(七)-java+ selenium自动化测试-宏哥带你全方位吊打Chrome启动过程(详细教程)
1.简介 经过前边几篇文章和宏哥一起的学习,想必你已经知道了如何去查看Selenium相关接口或者方法.一般来说我们绝大多数看到的是已经封装好的接口,在查看接口源码的时候,你可以看到这个接口上边的注释 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- 黄文俊:Serverless小程序后端技术分享
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 黄文俊,现任腾讯云SCF无服务器云函数高级产品经理,多年企业级系统开发和架构工作经验,对企业级存储.容器平台.微服务架构.无服务器计算等领域 ...
- 精华推荐 | 【JVM深层系列】「GC底层调优系列」一文带你彻底加强夯实底层原理之GC垃圾回收技术的分析指南(GC原理透析)
前提介绍 很多小伙伴,都跟我反馈,说自己总是对JVM这一块的学习和认识不够扎实也不够成熟,因为JVM的一些特性以及运作机制总是混淆以及不确定,导致面试和工作实战中出现了很多的纰漏和短板,解决广大小伙伴 ...
- UWA 技术分享连载 转载
技术分享连载1 Q1:Texture占用内存总是双倍,这个是我们自己的问题,还是Unity引擎的机制? Q2:我现在发现两个因素直接影响Overhead,一个是Shader的复杂度,一个是空Updat ...
- 阿里钉钉技术分享:企业级IM王者——钉钉在后端架构上的过人之处
本文引用了唐小智发表于InfoQ公众号上的“钉钉企业级IM存储架构创新之道”一文的部分内容,收录时有改动,感谢原作者的无私分享. 1.引言 业界的 IM 产品在功能上同质化较高,而企业级的 IM 产品 ...
随机推荐
- 什么是集群&集群的分类
集群(Cluster) 计算机集群简称集群,是一种计算机系统,它通过一组松散集成的计算机软件(和/或)硬件连接起来高度紧密地协作完成计算工作.在某种意义上,他们可以被看作是一台计算机.集群系统中 ...
- 在IIS Express下部署NuGet私服
用途 个人开发,部署自己的NuGet pkg. 环境 Win11 IIS Express (轻度使用,不安装IIS,而使用VS预装的IIS Express) VS2022 步骤 开发环境准备 因我拟用 ...
- 【软件】解决奥林巴斯生物显微镜软件OlyVIA提示“不支持您使用的操作系统”安装中止的问题
[软件]解决奥林巴斯生物显微镜软件OlyVIA提示"不支持您使用的操作系统"安装中止的问题 零.问题 资源在文末 问题如下,从奥林巴斯生物显微镜软件官网下载地址:https://l ...
- 再说PG的连接
前面说过连接PG的方法,但是遇到问题又不通了. 按照前面的做法还是不行,正是鼻子气歪了. 到pg老家下载PGODBC,安装了,还是不行. 其实仅仅copy一个libpg.dll是不够的.因为libpg ...
- DevOps的工作岗位的要求
## 为什么需要DevOps 不是每个人都能理解可靠的版本管理和牢固的构建系统的重要性. 也不是任何人能使得软件的发布达到可靠性,可重复性和可审计的高标准.Devops的职责就是将软件的构建和发布的流 ...
- nginx中的路径匹配规则详解(location规则)
Nginx的路径匹配规则 Nginx的匹配规则用location指令来实现,Nginx 的location指令用于匹配请求的 URI(请求路径),并根据匹配结果执行特定的处理指令.location是实 ...
- IDEA构建Maven项目生成的文件说明(.mvn、mvnw、mvnw.cmd、.gitignore、.iml、.idea、pom.xml)
IDEA构建的maven+springBoot项目结构如下: 1..gitignore:分布式版本控制系统git的配置文件,意思为忽略提交 在 .gitingore 文件中,遵循相应的语法,即在每一行 ...
- 基于MySQL分析线上充值留存率
1.数据清洗 步骤: 1.查询charge_record表业务类型为充值且订单状态为成功的数据 2.将上述数据转移到本地数据库 使用如下脚本: # coding=utf-8import pymysql ...
- python,设置windows系统时间
老笔记本纽扣电池没电了,每次拔掉电源再重新开机时间就对不上了,然后写个python脚本开机后执行对时吧 脚本直接网上复制的,比较简单,貌似时访问www.baidu.com获取头信息里的时间,然后设置为 ...
- JVM 垃圾回收调优的主要目标是什么?
JVM 垃圾回收调优的主要目标 JVM 垃圾回收调优的目标是为了提升应用的性能,优化垃圾回收过程中的停顿时间和吞吐量.调优的核心目标通常包括以下几点: 1. 减少垃圾回收的停顿时间 停顿时间(Stop ...