SpringAI用嵌入模型操作向量数据库!
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
PS:准确来说 Vector Database 和 Vector Store 不完全相同,前者主要用于“向量”数据的存储,而 Vector Store 是用于存储和检索向量数据的组件。
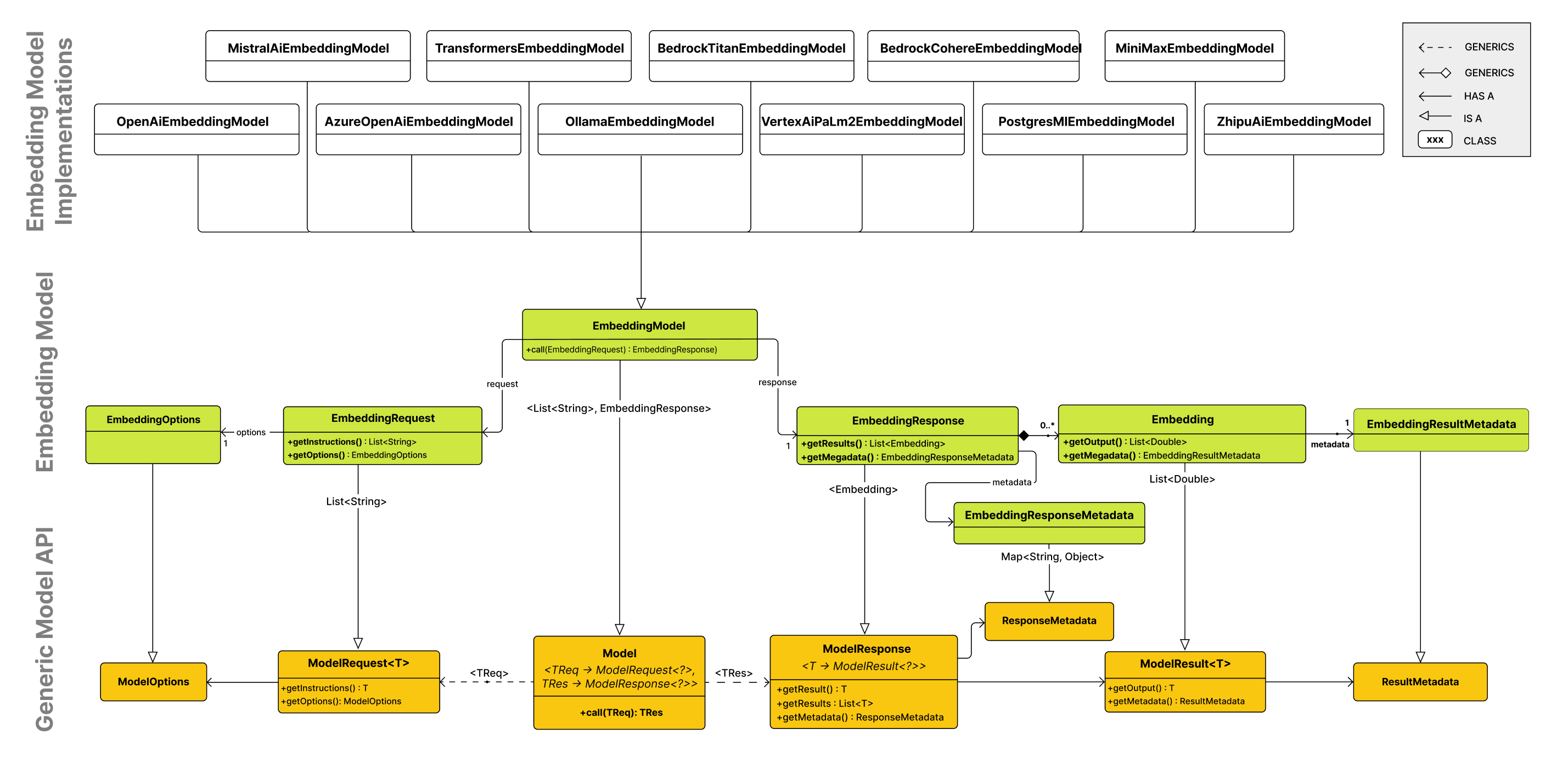
在 Spring AI 中,嵌入模型 API 和 Spring AI Model API 和嵌入模型的关系如下:
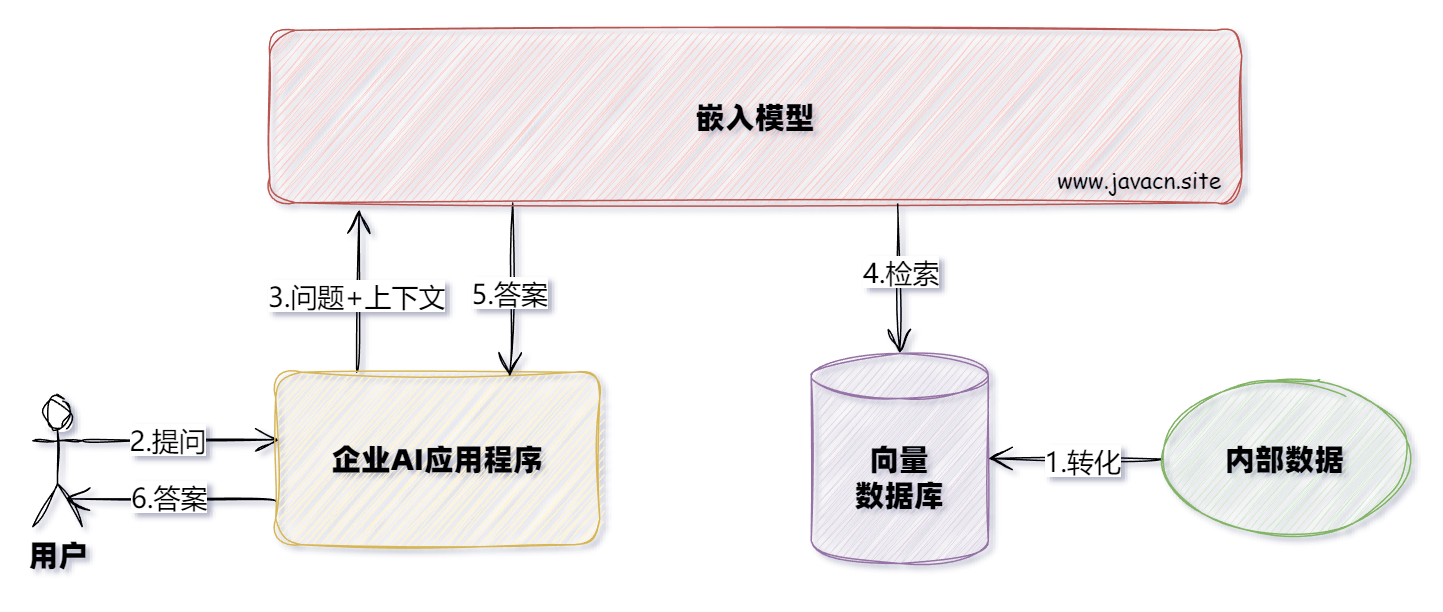
系统整体交互流程如下:
接下来我们使用以下技术:
- Spring AI
- 阿里云文本嵌入模型 text-embedding-v3
- SimpleVectorStore(内存级别存储和检索向量数据组件)
实现嵌入模型操作内存级别向量数据库的案例。
1.添加项目依赖
我们使用阿里云百炼平台的嵌入模型 text-embedding-v3 是兼容 OpenAI 的 SDK 的,因此,我们只需要添加 OpenAI 依赖即可:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
2.配置嵌入模型
阿里云百炼平台支持的向量模型:
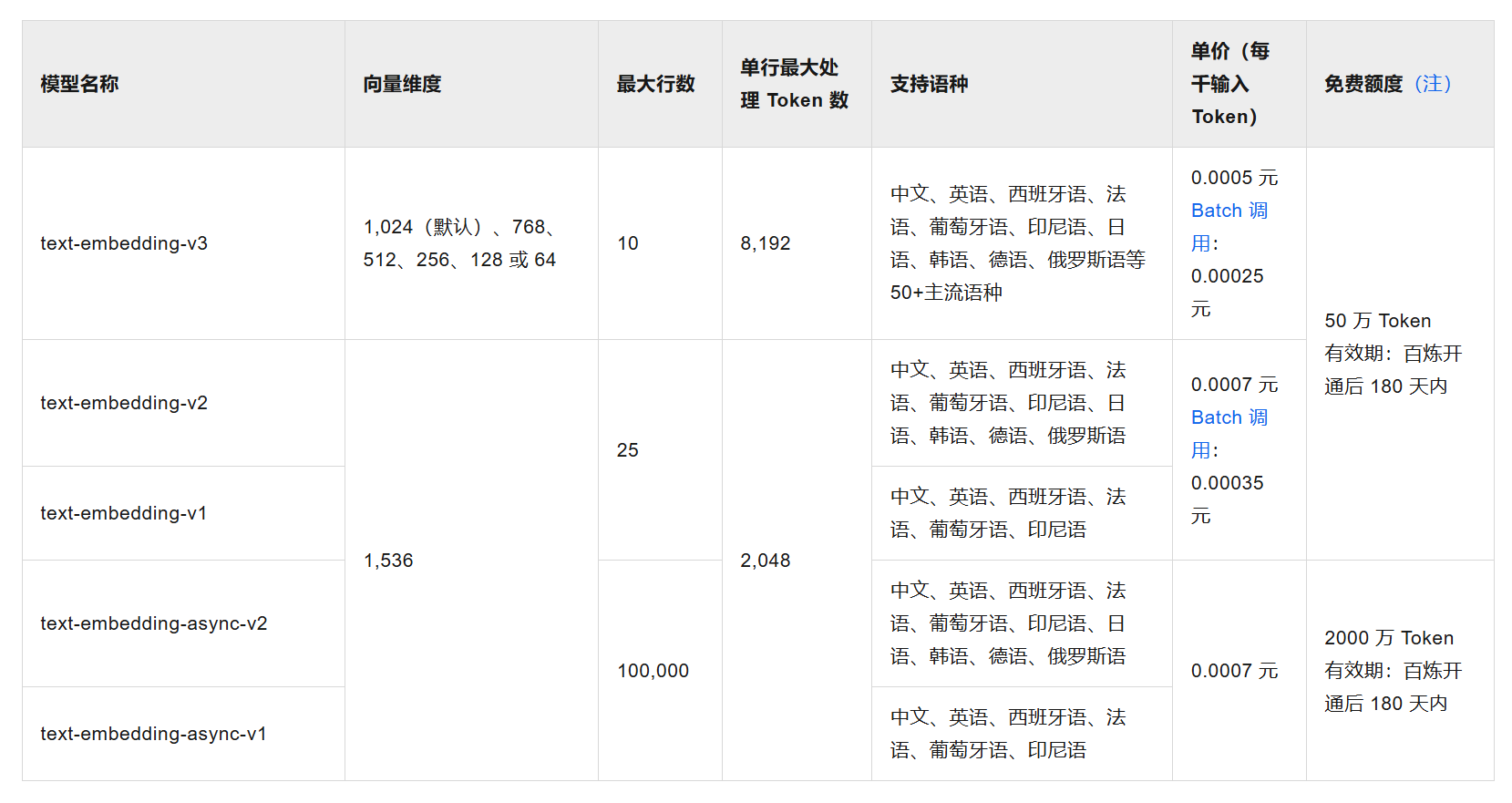
项目配置文件配置向量模型:
spring:
ai:
openai:
api-key: ${aliyun-ak}
embedding:
options:
model: text-embedding-v3
chat:
options:
model: deepseek-r1
3.配置向量模型
将 EmbeddingModel 和 VectorStore 进行关联,如下代码所示:
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
4.向量数据库添加数据
VectorStore 提供的常用方法如下:
- add(List documents) :添加文档。
- delete(List idList) :按 ID 删除文档。
- delete(Filter.Expression filterExpression) :按过滤表达式删除文档。
- similaritySearch(String query) 和 similaritySearch(SearchRequest request) :相似性搜索。
向数据库添加向量数据的方法如下:
// 构建测试数据
List<Document> documents =
List.of(new Document("I like Spring Boot"),
new Document("I love Java"));
// 添加到向量数据库
vectorStore.add(documents);
当然,向量数据的数据源可以是文件、图片、音频等资源,这里为了简单演示整体执行流程,使用了更简单直观的文本作为数据源。
5.查询数据
@RestController
@RequestMapping("/vector")
public class VectorController {
@Resource
private VectorStore vectorStore;
@RequestMapping("/find")
public List find(@RequestParam String query) {
// 构建搜索请求,设置查询文本和返回的文档数量
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(3)
.build();
List<Document> result = vectorStore.similaritySearch(request);
System.out.println(result);
return result;
}
}
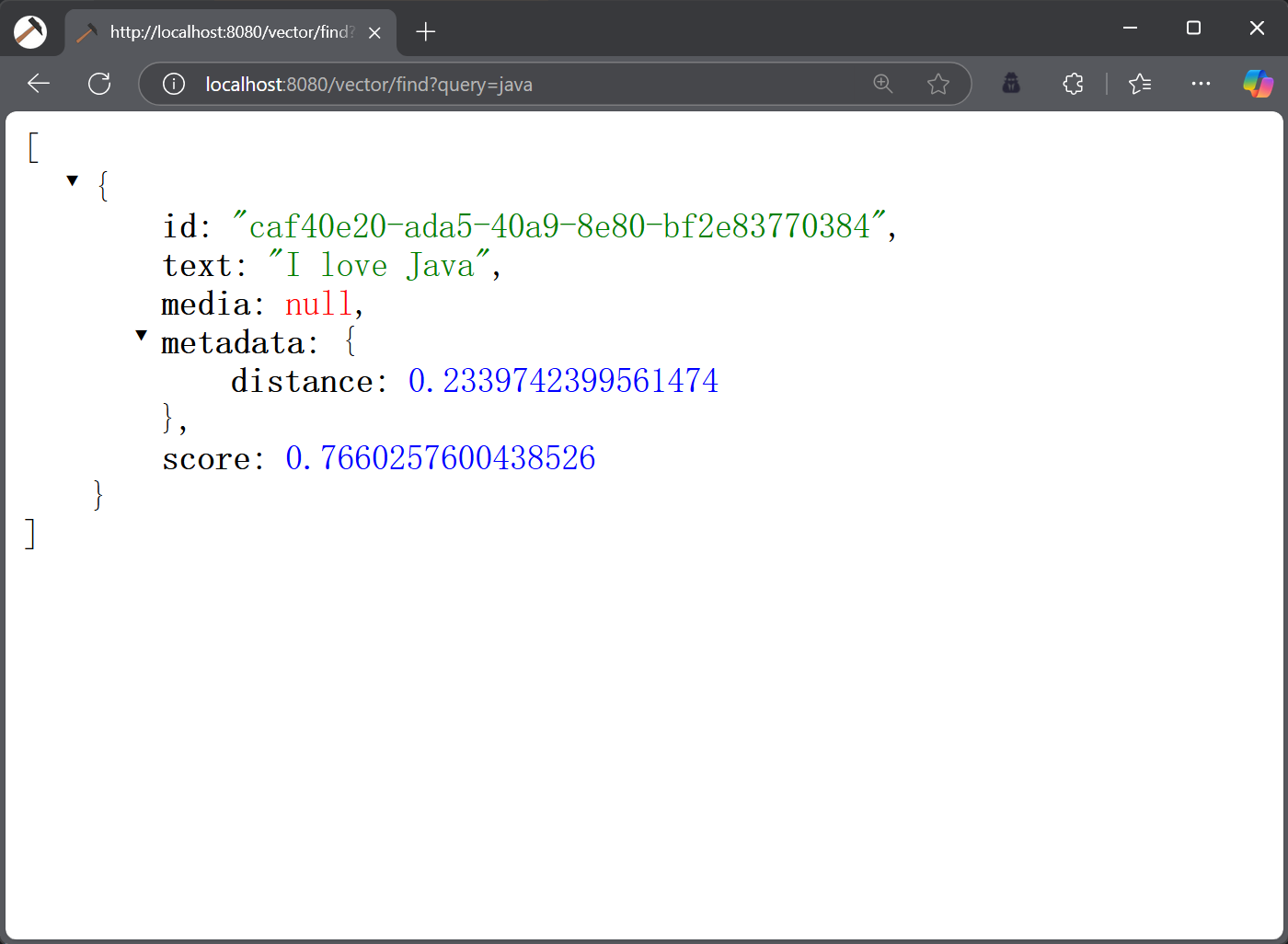
执行结果如下:
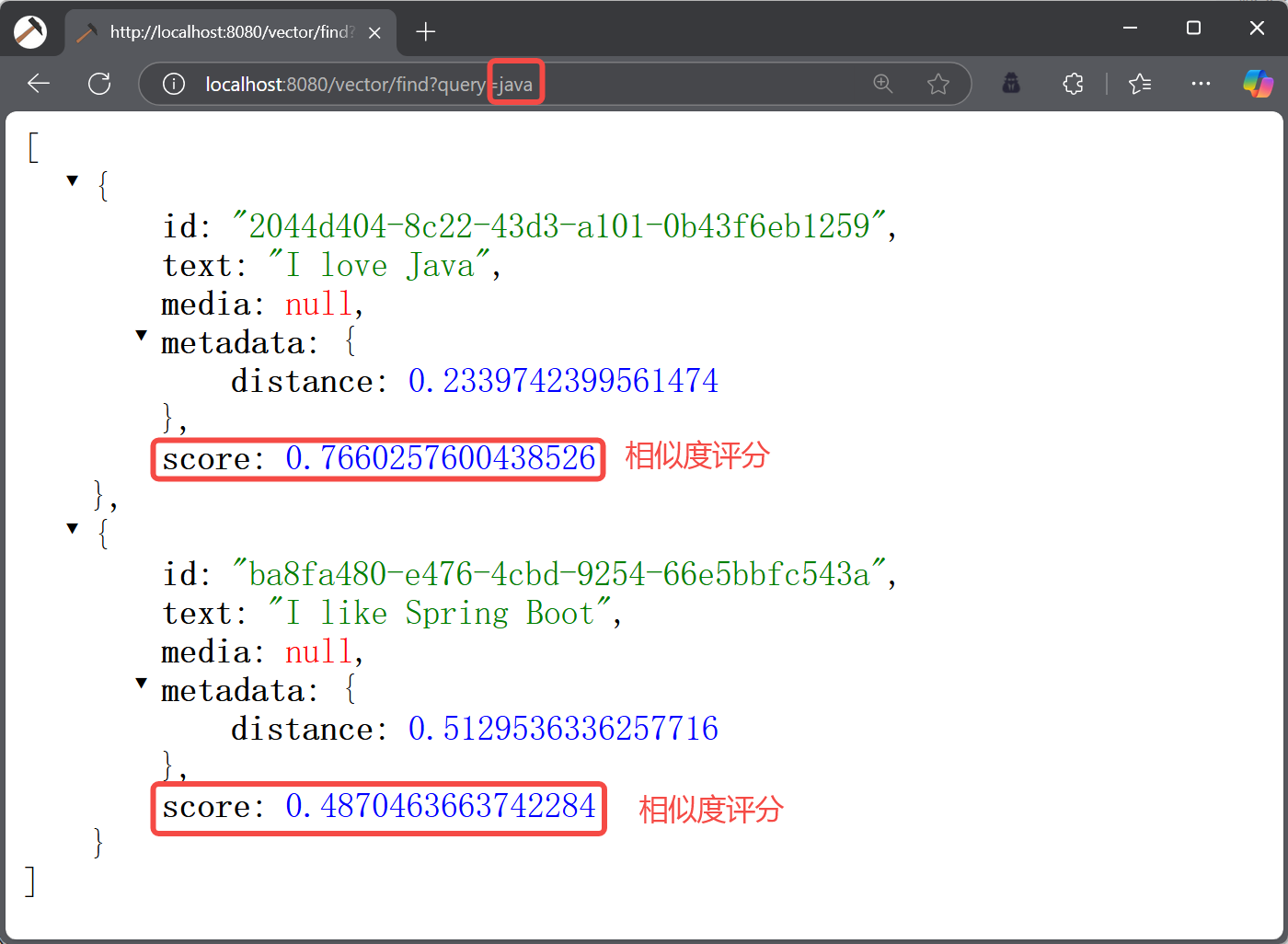
从上述结果可以看出,和“java”相似度最高的向量为“I love Java”,相似度评分为 0.77,如果我们 SearchRequest 对象中的 topK 设置为 1 的话,只会查询“I love Java”这条数据,如下图所示:
想要获取完整案例的同学加V:vipStone【备注:向量】
小结
嵌入模型和向量数据库是实现 RAG(检索增强生成)的技术基础,当然除了以上案例外,你可以使用 Redis 或 ES 来存储向量数据,并尝试加入 DeepSeek 实现 RAG 功能,这种形式更符合企业真实的技术应用。我是磊哥,如果觉得文章有帮助欢迎点赞、转发支持一下,我们下期再见。
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:场景题、并发编程、MySQL、Redis、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、JVM、设计模式、消息队列等模块。
SpringAI用嵌入模型操作向量数据库!的更多相关文章
- django->model模型操作(数据库操作)
一.字段类型 二.字段选项说明 三.内嵌类参数说明abstract = Truedb_table = 'table_name' #表名,默认的表名是app_name+类名ordering = ['id ...
- .NET使用DAO.NET实体类模型操作数据库
一.新建项目 打开vs2017,新建一个项目,命名为orm1 二.新建数据库 打开 SqlServer数据库,新建数据库 orm1,并新建表 student . 三.新建 ADO.NET 实体数据模型 ...
- python操作三大主流数据库(9)python操作mongodb数据库③mongodb odm模型mongoengine的使用
python操作mongodb数据库③mongodb odm模型mongoengine的使用 文档:http://mongoengine-odm.readthedocs.io/guide/ 安装pip ...
- Qt 学习之路 2(56):使用模型操作数据库
Qt 学习之路 2(56):使用模型操作数据库 (okgogo: skip) 豆子 2013年6月20日 Qt 学习之路 2 13条评论 前一章我们使用 SQL 语句完成了对数据库的常规操作,包括简单 ...
- 48.Python中ORM模型实现mysql数据库基本的增删改查操作
首先需要配置settings.py文件中的DATABASES与数据库的连接信息, DATABASES = { 'default': { 'ENGINE': 'django.db.backends.my ...
- Django中的模型(操作数据库)
目录 Django配置连接数据库 在Django中操作数据库 原生SQL语句操作数据库 ORM模型操作数据库 增删改查 后台管理 使用后台管理数据库 模型是数据唯一而且准确的信息来源.它包含您正在储存 ...
- python【第十二篇下】操作MySQL数据库以及ORM之 sqlalchemy
内容一览: 1.Python操作MySQL数据库 2.ORM sqlalchemy学习 1.Python操作MySQL数据库 2. ORM sqlachemy 2.1 ORM简介 对象关系映射(英语: ...
- ThinkPHP 的模型使用对数据库增删改查(五)
原文:ThinkPHP 的模型使用对数据库增删改查(五) ThinkPHP 的模型使用 // 直接连接数据库,但是得先去配置文件中配置下才行 class IndexAction extends Act ...
- 通过EntityFramework来操作MySQL数据库
自己首次用到了EF,为了利人利己,故将自己今天学的记录下来. 这个项目要用到的工具是VS2015.MySQL5.7.12 . 首先我们先建一个解决方案,里面建两个项目分别是Silentdoer.Mai ...
- UWP: 在 UWP 中使用 Entity Framework Core 操作 SQLite 数据库
在应用中使用 SQLite 数据库来存储数据是相当常见的.在 UWP 平台中要使用 SQLite,一般会使用 SQLite for Universal Windows Platform 和 SQLit ...
随机推荐
- 利用Linq Skip() Take()分页
private void TestPostData() { string all = ""; List<int> listTimeCard = new List< ...
- linux-杂项
1.常用基础 防火墙systemctl status firewalldsystemctl stop firewalldsystemctl start firewalld find / -size + ...
- biancheng-Spring Cloud教程
目录http://c.biancheng.net/springcloud/ 1微服务是什么2Spring Cloud是什么3Spring Cloud Eureka4Spring Cloud Ribbo ...
- Java中StringBuilder类常用的几个方法
StringBuilder类 StringBuilder 类是 Java 中用于处理可变字符串的类,它提供了在字符串内部进行修改的方法,相比之下,String 类是不可变的,每次对字符串做修改都会创建 ...
- [rustGUI][iced]基于rust的GUI库iced(0.13)的部件学习(05):svg图片转为png格式(暨svg部件的使用)
前言 本文是关于iced库的部件介绍,iced库是基于rust的GUI库,作者自述是受Elm启发. iced目前的版本是0.13.1,相较于此前的0.12版本,有较大改动. 本合集是基于新版本的关于分 ...
- Kotlin:【Map集合】集合创建、集合遍历、元素增加
to本身是一个函数
- SQL Server与ORACLE数据库存储过程编写的几个不同之处
一直在使用SQL Server数库的存储过程进行业务数据处理,现在ORACLE上进行存储过程应用,感觉没有MSSQL的方便灵活,总结了以下几点区别: 1.入参数据类型不要书写长度.比如:userNam ...
- Rust多线程中安全的使用变量
在Rust语言中,一个既引人入胜又可能带来挑战的特性是闭包如何从其所在环境中捕获变量,尤其是在涉及多线程编程的情境下. 如果尝试在不使用move关键字的情况下创建新线程并传递数据至闭包内,编译器将很可 ...
- h5使用vue-photo-preview 做全屏预览
h5页面使用全屏预览 最近需要在微信小程序中跳转到h5页面 在h5页面中需要进行图片预览展示 由于没有使用第三方的组件库. 只能手写,但是时间很紧张. 所以只能够寻找第三方的插件 vue-photo- ...
- Python基于自定义方法的排序
Python基于自定义方法的排序 在Python中,排序是一个常见的任务,它可以帮助我们根据特定的规则对数据结构(如列表)中的元素进行排序.Python的内置排序方法,如列表的sort()函数和内置函 ...