SpringAI用嵌入模型操作向量数据库!
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
PS:准确来说 Vector Database 和 Vector Store 不完全相同,前者主要用于“向量”数据的存储,而 Vector Store 是用于存储和检索向量数据的组件。
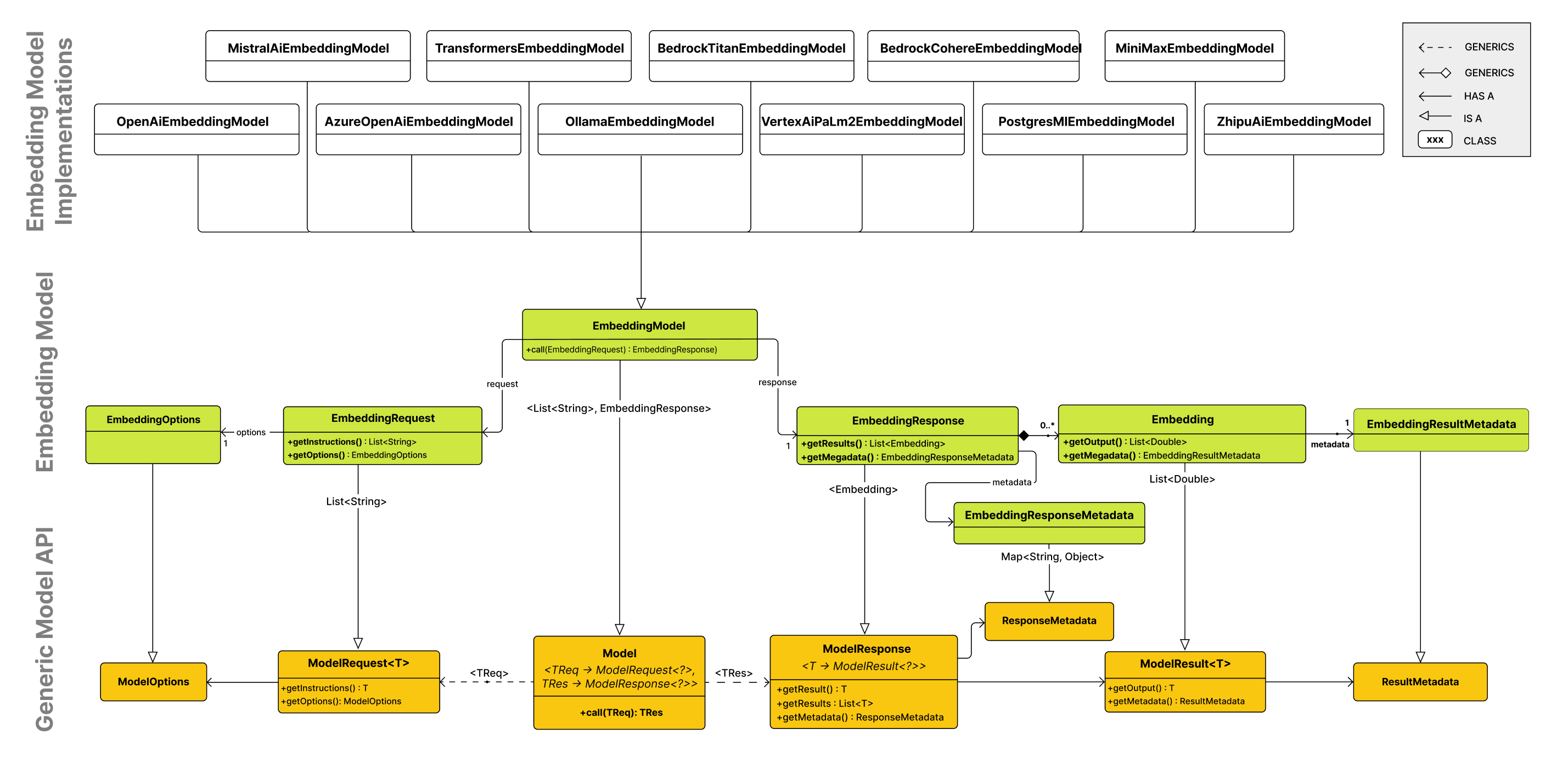
在 Spring AI 中,嵌入模型 API 和 Spring AI Model API 和嵌入模型的关系如下:
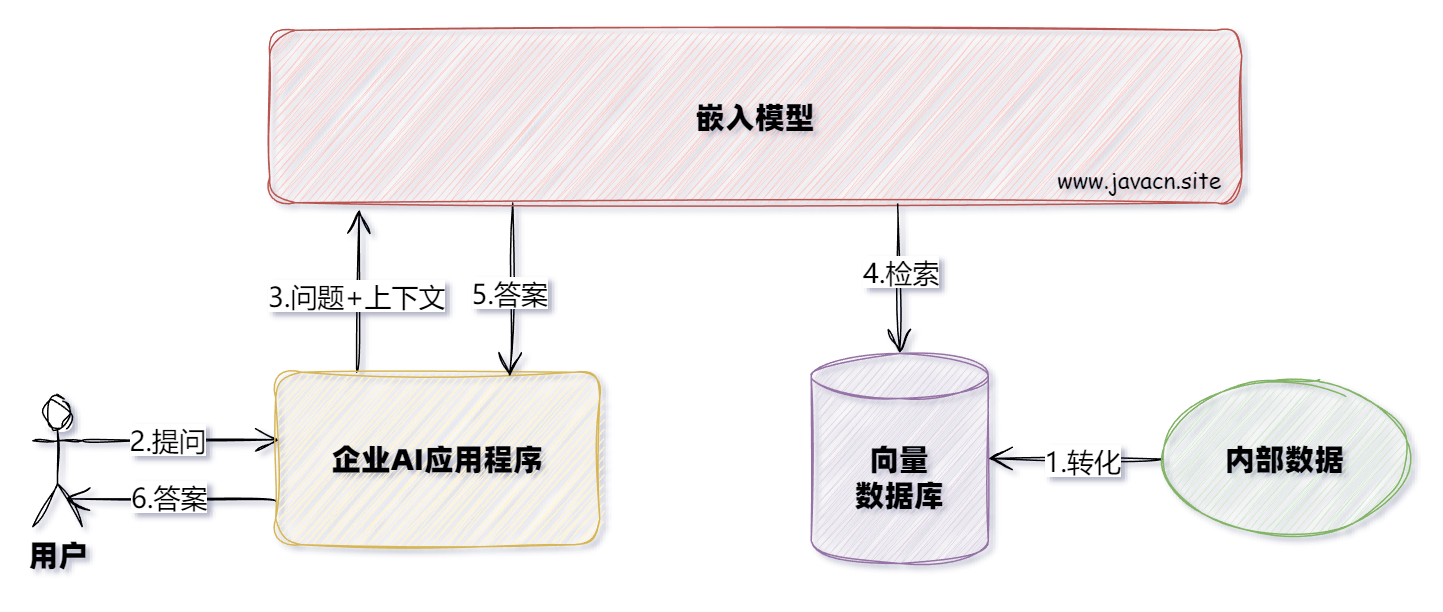
系统整体交互流程如下:
接下来我们使用以下技术:
- Spring AI
- 阿里云文本嵌入模型 text-embedding-v3
- SimpleVectorStore(内存级别存储和检索向量数据组件)
实现嵌入模型操作内存级别向量数据库的案例。
1.添加项目依赖
我们使用阿里云百炼平台的嵌入模型 text-embedding-v3 是兼容 OpenAI 的 SDK 的,因此,我们只需要添加 OpenAI 依赖即可:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
2.配置嵌入模型
阿里云百炼平台支持的向量模型:
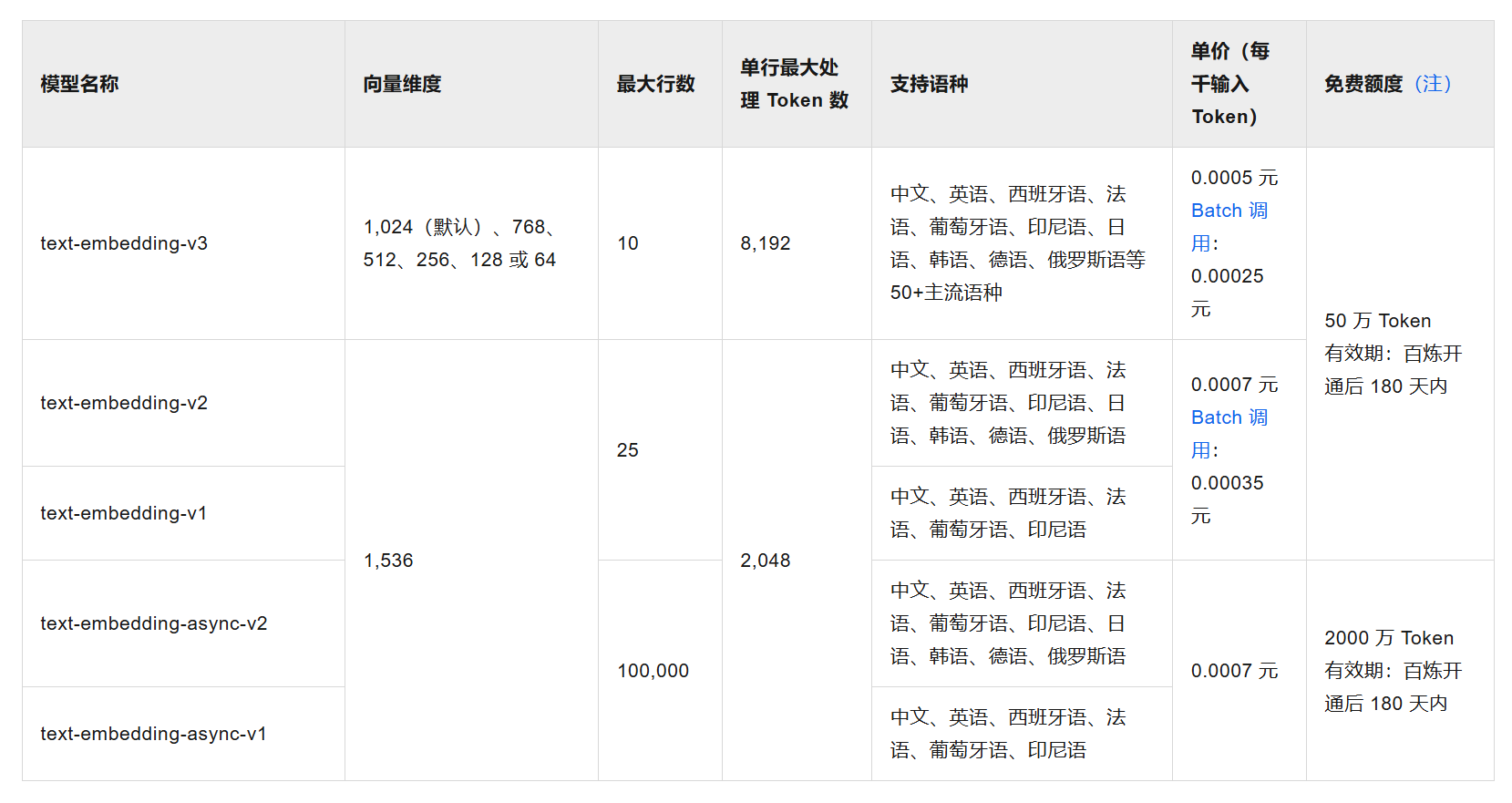
项目配置文件配置向量模型:
spring:
ai:
openai:
api-key: ${aliyun-ak}
embedding:
options:
model: text-embedding-v3
chat:
options:
model: deepseek-r1
3.配置向量模型
将 EmbeddingModel 和 VectorStore 进行关联,如下代码所示:
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
4.向量数据库添加数据
VectorStore 提供的常用方法如下:
- add(List documents) :添加文档。
- delete(List idList) :按 ID 删除文档。
- delete(Filter.Expression filterExpression) :按过滤表达式删除文档。
- similaritySearch(String query) 和 similaritySearch(SearchRequest request) :相似性搜索。
向数据库添加向量数据的方法如下:
// 构建测试数据
List<Document> documents =
List.of(new Document("I like Spring Boot"),
new Document("I love Java"));
// 添加到向量数据库
vectorStore.add(documents);
当然,向量数据的数据源可以是文件、图片、音频等资源,这里为了简单演示整体执行流程,使用了更简单直观的文本作为数据源。
5.查询数据
@RestController
@RequestMapping("/vector")
public class VectorController {
@Resource
private VectorStore vectorStore;
@RequestMapping("/find")
public List find(@RequestParam String query) {
// 构建搜索请求,设置查询文本和返回的文档数量
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(3)
.build();
List<Document> result = vectorStore.similaritySearch(request);
System.out.println(result);
return result;
}
}
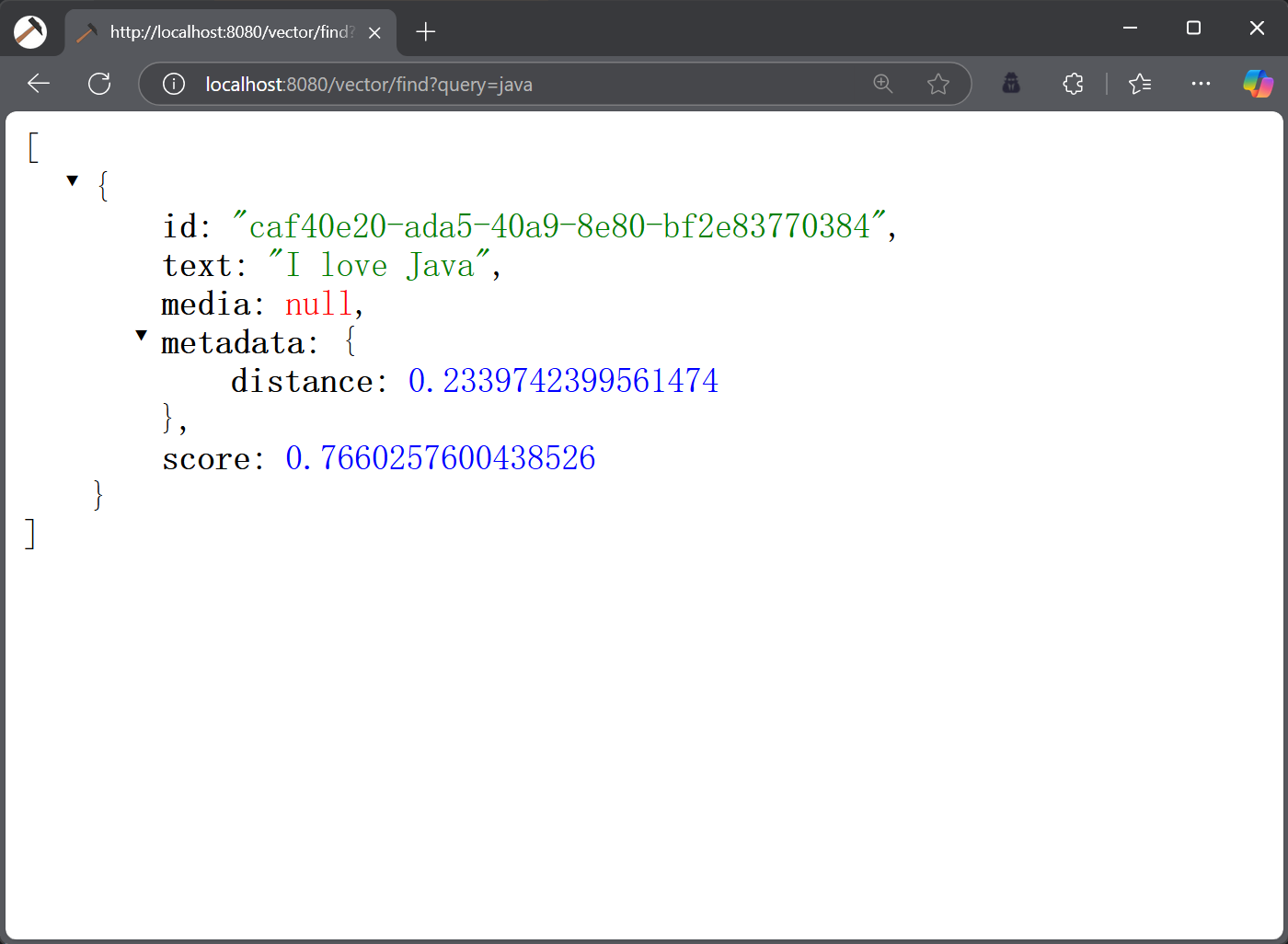
执行结果如下:
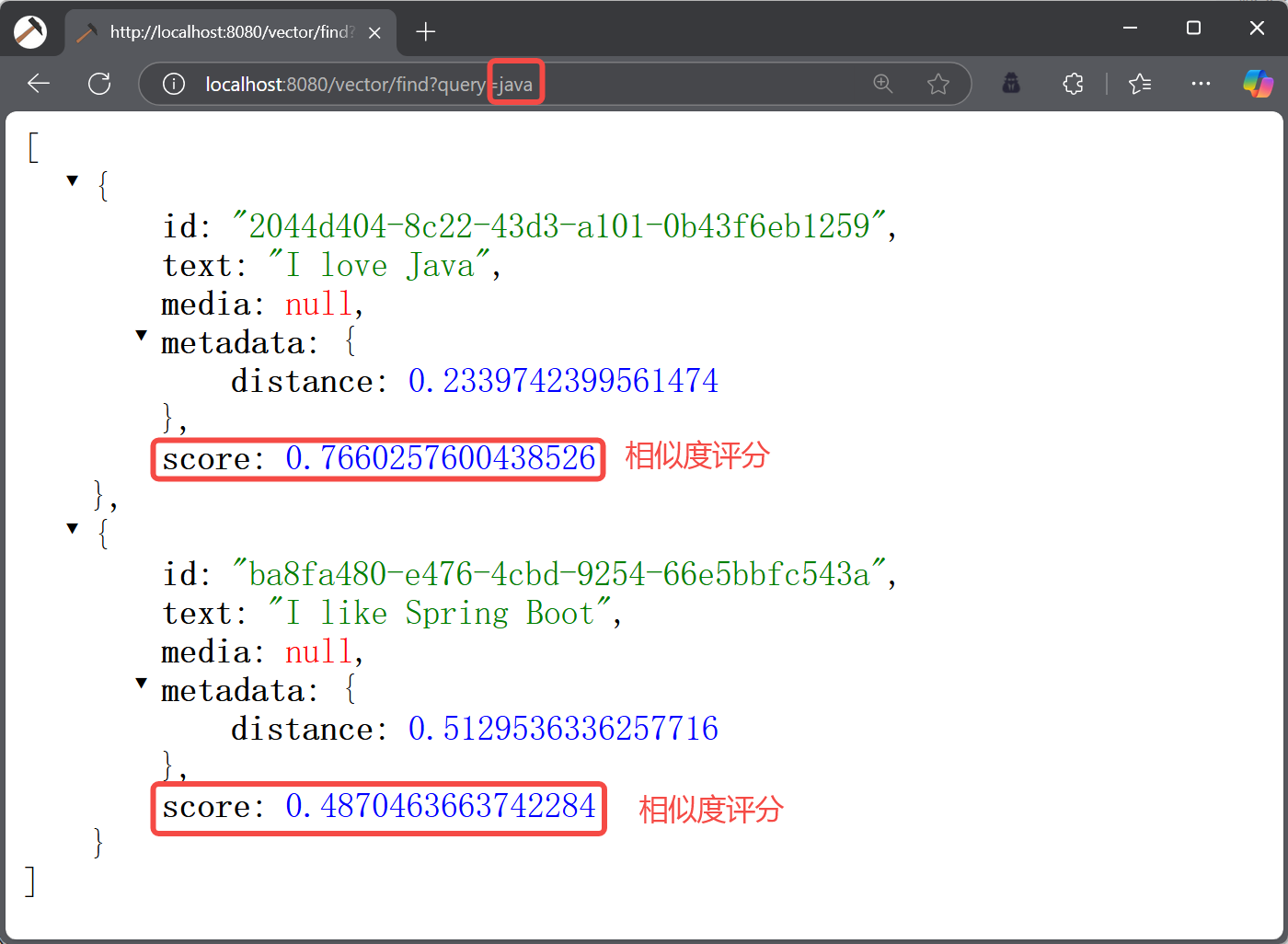
从上述结果可以看出,和“java”相似度最高的向量为“I love Java”,相似度评分为 0.77,如果我们 SearchRequest 对象中的 topK 设置为 1 的话,只会查询“I love Java”这条数据,如下图所示:
想要获取完整案例的同学加V:vipStone【备注:向量】
小结
嵌入模型和向量数据库是实现 RAG(检索增强生成)的技术基础,当然除了以上案例外,你可以使用 Redis 或 ES 来存储向量数据,并尝试加入 DeepSeek 实现 RAG 功能,这种形式更符合企业真实的技术应用。我是磊哥,如果觉得文章有帮助欢迎点赞、转发支持一下,我们下期再见。
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:场景题、并发编程、MySQL、Redis、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、JVM、设计模式、消息队列等模块。
SpringAI用嵌入模型操作向量数据库!的更多相关文章
- django->model模型操作(数据库操作)
一.字段类型 二.字段选项说明 三.内嵌类参数说明abstract = Truedb_table = 'table_name' #表名,默认的表名是app_name+类名ordering = ['id ...
- .NET使用DAO.NET实体类模型操作数据库
一.新建项目 打开vs2017,新建一个项目,命名为orm1 二.新建数据库 打开 SqlServer数据库,新建数据库 orm1,并新建表 student . 三.新建 ADO.NET 实体数据模型 ...
- python操作三大主流数据库(9)python操作mongodb数据库③mongodb odm模型mongoengine的使用
python操作mongodb数据库③mongodb odm模型mongoengine的使用 文档:http://mongoengine-odm.readthedocs.io/guide/ 安装pip ...
- Qt 学习之路 2(56):使用模型操作数据库
Qt 学习之路 2(56):使用模型操作数据库 (okgogo: skip) 豆子 2013年6月20日 Qt 学习之路 2 13条评论 前一章我们使用 SQL 语句完成了对数据库的常规操作,包括简单 ...
- 48.Python中ORM模型实现mysql数据库基本的增删改查操作
首先需要配置settings.py文件中的DATABASES与数据库的连接信息, DATABASES = { 'default': { 'ENGINE': 'django.db.backends.my ...
- Django中的模型(操作数据库)
目录 Django配置连接数据库 在Django中操作数据库 原生SQL语句操作数据库 ORM模型操作数据库 增删改查 后台管理 使用后台管理数据库 模型是数据唯一而且准确的信息来源.它包含您正在储存 ...
- python【第十二篇下】操作MySQL数据库以及ORM之 sqlalchemy
内容一览: 1.Python操作MySQL数据库 2.ORM sqlalchemy学习 1.Python操作MySQL数据库 2. ORM sqlachemy 2.1 ORM简介 对象关系映射(英语: ...
- ThinkPHP 的模型使用对数据库增删改查(五)
原文:ThinkPHP 的模型使用对数据库增删改查(五) ThinkPHP 的模型使用 // 直接连接数据库,但是得先去配置文件中配置下才行 class IndexAction extends Act ...
- 通过EntityFramework来操作MySQL数据库
自己首次用到了EF,为了利人利己,故将自己今天学的记录下来. 这个项目要用到的工具是VS2015.MySQL5.7.12 . 首先我们先建一个解决方案,里面建两个项目分别是Silentdoer.Mai ...
- UWP: 在 UWP 中使用 Entity Framework Core 操作 SQLite 数据库
在应用中使用 SQLite 数据库来存储数据是相当常见的.在 UWP 平台中要使用 SQLite,一般会使用 SQLite for Universal Windows Platform 和 SQLit ...
随机推荐
- Nodejs 实现一个CRC16校验
近日在开发一个数据平台,据说nodejs比较适合DIRT类型的程序,所以也搞了一把,虽然接收.转发及其报文解析等功能顺利的实现了,但是由于某些报文涉及到应答,故而需要CRC校验,也算是一个小坑吧,故而 ...
- NAT原理:概念、使用场景、转发流程及规则
本文分享自天翼云开发者社区<NAT原理:概念.使用场景.转发流程及规则>,作者:x****n 网络地址转换(NAT)是一种在计算机网络中将一个网络的IP地址转换为另一个网络的IP地址的技术 ...
- 局域网 yum仓库
有时候在局域网环境中,每台机器上挂载本地镜像充当yum仓库太麻烦. 可以选择局域网一台服务器生成yum仓库,局域网其他服务器通过http协议访问这台服务器的yum仓库. 一.准备 两台虚拟机,其中 A ...
- 支付宝云Serveless+豆包AI实现AI日语学习APP
1. 引言 最近学日语,发现动词.形容词的变形规则又多又复杂,在不同语境里变化也不一样,句子结构和语法也很麻烦.为了提高学习效率,决定开发基于AI的日语学习APP,借助 AI 进行辅助学习,目前已经完 ...
- Ollama模型迁移
技术背景 在前面的一些文章中,我们介绍过使用Ollama在Linux平台加载DeepSeek蒸馏模型,使用Ollama在Windows平台部署DeepSeek本地模型.除了使用Ollama与模型文件交 ...
- 安川MOTOMAN机器人NX100维修的注意事项
安川MOTOMAN机器人NX100维修,操作人员安全注意事项 整个机器人的最大动作范围内均具有潜在的危险性. 为机器人工作的所有人员 (安全管理员.安装人员.操作人员和机器人维修人员) 必须时刻树 ...
- 如何在JMeter中配置断言,将非200状态码视为测试成功
如何在JMeter中配置断言,将非200状态码视为测试成功 引言 在接口测试中,HTTP响应状态码是判断请求是否成功的重要依据.通常情况下,状态码200表示请求成功,而其他状态码则可能表示各种类型的错 ...
- Typecho 如何开启外链转内链
把博客中的外部链接转换为网站内链,据说有利于搜索引擎收录.该插件主要由 benzBrake 大佬 编写,同时支持转换文章和评论中的链接. 上传插件 下载 Master Branch Code 后上传到 ...
- 如何测试网络是否支持ipv6地址?如何打开ipv6?
疑难解答加微信机器人,给它发:进群,会拉你进入八米交流群 机器人微信号:bamibot 简洁版教程访问:https://bbs.8miyun.cn 一.什么是IPv6: 1.IPv6简介: IPv6是 ...
- 『玩转Streamlit』--缓存机制
Streamlit 应用在运行时,每次用户交互都会触发整个脚本的重新执行. 这意味着一些耗时操作,如数据加载.复杂计算和模型训练等,可能会被重复执行,严重影响应用响应速度. 本文介绍的缓存机制能够帮助 ...