在分布式追踪系统中使用 W3C Trace Context
在分布式追踪系统中使用 W3C Trace Context
https://dev.to/luizhlelis/using-w3c-trace-context-standard-in-distributed-tracing-3743
在软件开发中,当系统遭遇到运行时失效的时刻,开发人员会本能地尝试找到是哪里调用了失效的方法,以及哪里是原始的请求。这就是 stack trace 的作用,比如下面的示例所示。
Unhandled exception. System.InvalidOperationException: Stack trace example
at Program.CallChildActivity() in /Users/luizhlelis/Documents/projects/personal/trace-context-w3c/src/system-diagnostics-activity/Program.cs:line 22
at Program.Main() in /Users/luizhlelis/Documents/projects/personal/trace-context-w3c/src/system-diagnostics-activity/Program.cs:line 11
基于上面的信息,我们就可以直到失效发生在 CallChildActivity() 方法 ( 22 行 ),它是被 Main() 方法 ( 1 行 ) 所调用,它们都位于 Program.cs 类中。这就是运行时消息追踪对于软件的健康和可信赖如此重要的原因。像这样丰富的信息极大提高了解决问题的生产力。所以,用术语消息追踪来说,stack trace 对于目标是单进程的应用程序来说非常适合,比如单体应用系统。但是反过来说,对于处理分布式应用系统,例如微服务架构,stack trace 就不能足够用来展示整体的消息追踪了。这就是为什么分布式追踪工具和标准变得必要的原因。W3C 定义了这种追踪类型的标准,称为 Trace Context。
W3C Trace Context 目标
想象一个使用微服务架构设计的系统,它提供 2 个使用同步方式通讯的 API,其中的第 2 个与 worker 通过消息代理通讯。
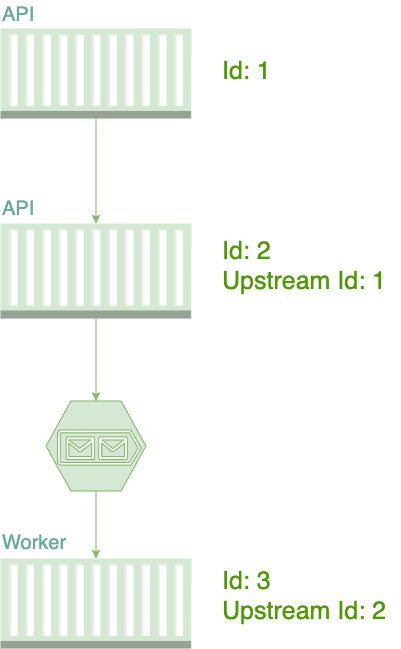
图 1 分布式追踪
与 stack trace 类似,每个 Activity 需要一个唯一标识,还需要知道是调用者的唯一标识。为了解决此类问题,许多厂商发布了不仅提供分布式追踪消息信息,还包括了应用程序性能,加载时间,应用程序响应时间,以及其它内容。此类 vendor 被称为 应用程序性能管理工具 ( Application Performance Management tools (APM tools) ),或者追踪系统,下面是其中的一些:
- Dynatrace
- New Relic
- Application Insights
- Elastic APM
- Zipkin
注意:我选择术语
verdor来描述所有的追踪系统,是因为这是标准的说明它们的方式。但是看起来 它会很快发生变化。
现在想象一个场景,这里有各种 vendor 使用各种语言并使用各种的诊断库,有一些使用 operation-id 来标识,有些使用 request-id,可能还有一些使用 trace-id。除此之外,基于不同 vendor 或者诊断库的标识格式也各不相同。有的是分层 ( hierarchical ) 格式,有的使用 UUID,有的是 24 字符的字符串格式等等。这就会导致这样的结果:使用不同追踪系统 vendor 导致不能关联起来,也不能将追踪传播,因为这里没有唯一标识可以传递。这就是 trace context 标准的作用。
trace context 标准
W3C Trace Context 规范定义了针对 HTTP 头的标准和格式,用来传播分布式追踪上下文信息。其中定义了 2 个字段用来在 HTTP 请求头中传播追踪流。先看一下标准定义中的这 2 个字段:
traceparent: 用来描述在追踪图谱中到达请求的位置。它表示在追踪系统中到达请求的通用格式,被所有的 vendor 所理解。tracestate: 使用 vendor 特定的数据表示形式来扩展traceparent,使用 name/value 对形式。在 tracestate 中保存信息是可选的。
traceparent 字段
traceparent 字段的规范使用扩充巴科斯范式 (ABNF ) 形式定义,由 4 个部分组成
version - traceid - parentid/spanid - traceflags
注意:
sub-field术语是非官方的。我使用该术语仅仅用于说明。
例如:
00-480e22a2781fe54d992d878662248d94-b4b37b64bb3f6141-00
version: 8 位,系统适配的追踪上下文版本,当前位00trace-id: 16 字节,追踪整体的标识。用于在系统中标识一个分布式追踪整体。parent-id/span-id: 8 字节,用来表述在进入请求中,或者对外请求中,当前跨度的父级。trace-flags: 8 位,调用者的建议标志,可以考虑为调用者的建议,限制为 3 个原因:信息或是滥用,调用方的错误,或者在调用方与被调用方的不同负载。
所有字段都使用 16 进制编码 ( hexadecimal )
进而,在图 1 中的应用程序中应用 trace context 的概念,将导致如下的结果:

图 2 传播字段
需要注意的是,trace-id 标识了整个追踪,而 parent-id 标识整个追踪中限定的范围。进而,traceparent 和 tracestate 一起在整个追踪流中传播。
为了更好地动态说明 traceparent,让我们看下面的示例,它使用 C# 编写,这里生成了 2 个跨度,并且共享的上下文在其间传播。
using System;
using System.Diagnostics;
var upstreamActivity = new Activity("Upstream");
upstreamActivity.Start();
Console.WriteLine(upstreamActivity.OperationName);
Console.WriteLine("traceparent: {0}", upstreamActivity.Id);
CallChildActivity();
upstreamActivity.Stop();
Console.ReadKey();
void CallChildActivity()
{
var downstreamActivity = new Activity("Downstream Dependency");
downstreamActivity.Start();
Console.WriteLine(downstreamActivity.OperationName);
Console.WriteLine("traceparent: {0}", downstreamActivity.Id);
downstreamActivity.Stop();
}
注意:在 .NET 5 中,
System.Diagnostics.Activity库已经被配置为使用 W3C 标准。
即使上面的示例是作为单进程应用程序,还是使用了 Trace Context 标准的模式。基本上,这个程序做这些事情:
- 首先,它开始一个上游的跨度,并输出其
traceparent到控制台 - 然后,它调用一个下游的方法,开始另一个跨度,也输出它的
traceparent到控制台,并关闭跨度 - 最后,上游的跨度被关闭
输出如下所示:
Upstream
traceparent: 00-3e425f2373d89640bde06e8285e7bf88-9a5fdefae3abb440-00
Downstream Dependency
traceparent: 00-3e425f2373d89640bde06e8285e7bf88-0767a6c6c1240f47-00
注意这个 trace-id (3e425f2373d89640bde06e8285e7bf88) 在整个追踪中被维护,而 parent-id 基于不同的跨度是不同的,上游中是:9a5fdefae3abb440 而下游中是 0767a6c6c1240f47。
在有些场景下,parent-id 会由于其名称导致困惑。但是,该名称是相对于到达的请求来说的。因此,必须从端点的角度来看待,例如,考虑一个请求消息刚刚到达 API 的控制器,从请求头中接收到的 traceparent 还没有被更新到中间件跨度的 parent-id 中,所以,此刻 traceparent中的 parent-id 就是上游标识,或者说,就是父级。
tracestate 字段
Trace Context:AMQP 协议
如图 2 所示,在微服务架构中,通常使用中间商来传播消息。对于此类操作,有另一个文档规范该模式 ( 这里使用 AMQP 协议 ),Trace Context: AMQP protocol
Trace Context: AMQP 协议 是另外一个 W3C 示例文档,该规范定义了与 HTTP 标准不同的 trace context 字段处理。
该标准建议 traceparent 和 tracestat 两者应该添加到消息发布者的消息的 application-properties 部分中,从消息读取者的角度来说,trace context 应该首先通过读取 message-annotations 来构建,如果这里不存在,再通过 application-properties 读取。参见如下的 AMQP 协议消息格式。

图 3 AMQP 消息格式
将 trace context 字段放置到消息发布者定义的消息内的 application-properties 部分的原因是中间商不能修改这些属性,因为这部分是不可变的。从另外的角度来说,message-annotations 被设计为由中间商使用,换句话说,该部分中的字段可以在消息处理过程中发生更改。因此,这意味着,如果需要在中间件内部对消息进行注释,则必须在消息注释部分中进行注释,并使用发布者在应用程序属性中发送的字段作为基础。
小结
W3C 标准规范了在分布式追踪系统中的模式。当前,只有用于 HTTP 的,其它还在工作中 ( AMQP, MQTT 和 baggate)。但这不意味着你应该在产品环境中忽视它,但是要注意到这些变化,更重要的是保持对最新发布的更新。
在分布式追踪系统中使用 W3C Trace Context的更多相关文章
- Uber分布式追踪系统Jaeger使用介绍和案例
原文:Uber分布式追踪系统Jaeger使用介绍和案例[PHP Hprose Go] 前言 随着公司的发展,业务不断增加,模块不断拆分,系统间业务调用变得越复杂,对定位线上故障带来很大困难.整个调 ...
- 开源分布式追踪系统 — Jaeger介绍
目录 一.Jaeger是什么 二.Jaeger架构 1. 术语 2. 架构图 三.关于采样率 四.部署与实践 一.Jaeger是什么 Uber开发的一个受Dapper和Zipkin启发的分布式跟踪系统 ...
- [业界方案] 用SOFATracer学习分布式追踪系统Opentracing
[业界方案] 用SOFATracer学习分布式追踪系统Opentracing 目录 [业界方案] 用SOFATracer学习分布式追踪系统Opentracing 0x00 摘要 0x01 缘由 &am ...
- [业界方案]用Jaeger来学习分布式追踪系统Opentracing
[业界方案]用Jaeger来学习分布式追踪系统Opentracing 目录 [业界方案]用Jaeger来学习分布式追踪系统Opentracing 0x00 摘要 0x01 缘由 & 问题 1. ...
- 分布式追踪系统dapper
http://www.cnblogs.com/LBSer/p/3390852.html 最近单位需要做自己的分布式监控系统,因此看了一些资料,其中就有google的分布式追踪系统dapper的论文:h ...
- Linux下安装 SkyWalking 分布式追踪系统
Linux下安装 SkyWalking 分布式追踪系统 1.SkyWalking简介 1.1 SkyWalking介绍 SkyWalking项目是由华为大牛吴晟开源的个人项目,目前已经加入Apache ...
- SkyWalking 分布式追踪系统
随着微服务架构的流行,一些微服务架构下的问题也会越来越突出,比如一个请求会涉及多个服务,而服务本身可能也会依赖其他服务,整个请求路径就构成了一个网状的调用链,而在整个调用链中一旦某个节点发生异常,整个 ...
- .NetCore从零开始使用Skywalking分布式追踪系统
本文将从0开妈搭建两个webapi项目,使用Skywalking来追踪他们之间的调用关系及响应时间.开发环境为VisualStudio2019 1:安装Skywalking,可参考:https://w ...
- 架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里 一.全局ID简介 在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理.比如常见的: 订单:order ...
- Docker安装Skywalking APM分布式追踪系统
环境介绍 本文使用虚拟机unbutu18+docker.本unbutu18系统IP地址为:192.168.150.134 大家在使用时记得将此地址换成自己的实际地址. docker的安装可参考:htt ...
随机推荐
- HDU-ACM 2024 Day4
T1001 超维攻坚(HDU 7469) 三维凸包,不会. T1002 黑白边游戏(HDU 7470) 显然这道题没有一个固定的最优策略,所以只能 \(\text{dp}\) 决策. 可以倒着做,设 ...
- 使用 GPU-Operator 与 KubeSphere 简化深度学习训练与 GPU 监控
本文将从 GPU-Operator 概念介绍.安装部署.深度训练测试应用部署,以及在 KubeSphere 使用自定义监控面板对接 GPU 监控,从原理到实践,逐步浅析介绍与实践 GPU-Operat ...
- 报名开启|QKE 容器引擎托管版暨容器生态发布会!
当下,"云原生"技术红利正吞噬旧秩序,重塑新世界. 但您的企业是否依然困惑:缺少运维人员或运维团队,想要专注于业务的开发,又不得不兼顾集群的日常运维:在生产环境中,为了保证业务的高 ...
- PHP的json浮点精度难题
前言 之前开发的接口需要用到json加签,有一次对接JAVA时,签名怎么都过不了,仔细对比了字符串,发现是PHP进行json_encode时,会将浮点型所有无意义的0给去掉(echo和var_dump ...
- mysql 查询两个日期之间所有天数(查询近两个月所有日期)
本文转自博文:https://blog.csdn.net/qq_42795259/article/details/126722209 遇到一个需求需要查询近两个月所有日期,如下图: 首先实现解决问题如 ...
- [Flink/FlinkCDC] 实践总结:Flink 1.12.6 升级 Flink 1.15.4
Flink DataStream/API 依赖模块的变化 版本变化 flink.version : 1.12.6 => 1.15.4 flink.connector.version : 1.12 ...
- 关于 IntelliJ IDEA 2024 安装使用 (附加激活码、补丁,亲测有效)
第一步:下载 IDEA 安装包 访问 IDEA 官网,下载 IDEA 2024.1.4 版本的安装包,下载链接如下 : idea官方链接 也可以在这里点击下载idea https://pan.quar ...
- 搞人工智能开源大语言模型GPT2、Llama的正确姿势
(如果想及时收到人工智能相关的知识更新,请点击关注!!) 序言:目前我们每一小节的内容都讲解得非常慢,因为这是人工智能研发中的最基础知识.如果我们不能扎实掌握这些知识,将很难理解后续更复杂且实用的概念 ...
- 精选2款C#/.NET开源且功能强大的网络通信框架
前言 今天大姚给分享2个C#/.NET开源且功能强大的网络通信框架,希望可以帮助到有需要的同学. NetCoreServer NetCoreServer是一个.NET开源.免费(MIT License ...
- 2.搭建K8S集群前置知识
搭建K8S集群 搭建k8s环境平台规划 单master集群 单个master节点,然后管理多个node节点 多master集群 多个master节点,管理多个node节点,同时中间多了一个负载均衡的过 ...