FastAPI与MongoDB分片集群:异步数据路由与聚合优化
title: FastAPI与MongoDB分片集群:异步数据路由与聚合优化
date: 2025/05/26 16:04:31
updated: 2025/05/26 16:04:31
author: cmdragon
excerpt:
FastAPI与MongoDB分片集群集成实战探讨了分片集群的核心概念、Motor驱动配置技巧、分片数据路由策略、聚合管道高级应用、分片索引优化方案及常见报错解决方案。分片集群通过将数据集分割成多个片段,适合处理大规模数据和高并发场景。Motor驱动的异步特性需要合理配置连接池参数。分片策略包括哈希分片、范围分片和复合分片,结合业务需求选择。聚合管道优化策略包括使用分片键过滤、避免跨分片连接和处理大型数据集。分片索引优化原则是优先使用覆盖查询的复合索引。常见报错解决方案涉及连接超时、排序问题和查询超时等。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- MongoDB
- 分片集群
- Motor驱动
- 数据路由
- 聚合管道
- 索引优化

扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
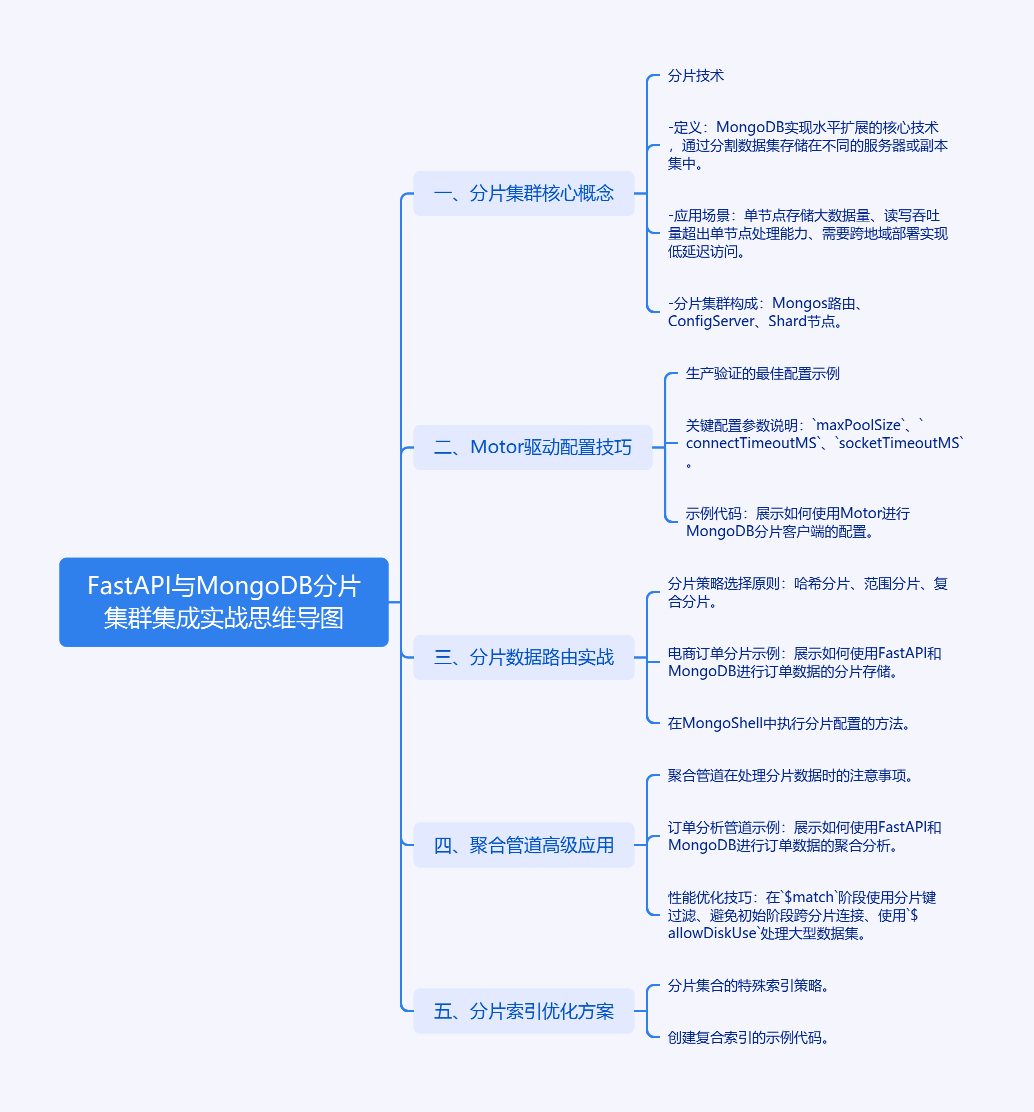
第一章:FastAPI与MongoDB分片集群集成实战
一、分片集群核心概念
分片(Sharding)是MongoDB实现水平扩展的核心技术,通过将数据集分割成多个片段(Shard),每个片段存储在不同的服务器或副本集中。这种架构特别适合处理FastAPI应用中的以下场景:
- 单节点存储达到TB级数据量
- 读写吞吐量超过单节点处理能力
- 需要跨地域部署实现低延迟访问
分片集群由三个核心组件构成:
- Mongos路由:查询流量入口(类似图书馆检索台)
- Config Server:存储元数据(类似图书索引目录)
- Shard节点:实际数据存储节点(类似图书馆书架)
二、Motor驱动配置技巧
使用Motor的异步特性需要特别注意连接池管理。以下是经过生产验证的最佳配置示例:
# requirements.txt
motor == 3.1
.1
fastapi == 0.95
.2
pydantic == 1.10
.7
# database.py
from motor.motor_asyncio import AsyncIOMotorClient
from contextlib import asynccontextmanager
class MongoDBShardClient:
def __init__(self, uri: str, max_pool_size: int = 100):
self.client = AsyncIOMotorClient(
uri,
maxPoolSize=max_pool_size,
connectTimeoutMS=3000,
socketTimeoutMS=5000
)
@asynccontextmanager
async def get_sharded_db(self, db_name: str):
try:
yield self.client[db_name]
finally:
# 连接自动归还连接池
pass
# 配置分片集群连接(包含3个mongos路由)
shard_client = MongoDBShardClient(
"mongodb://mongos1:27017,mongos2:27017,mongos3:27017/"
"?replicaSet=shardReplSet"
)
关键配置参数说明:
maxPoolSize:根据应用QPS调整,建议 (最大并发请求数)/10connectTimeoutMS:防止网络波动导致服务不可用socketTimeoutMS:避免慢查询阻塞整个连接池
三、分片数据路由实战
分片策略选择原则
- 哈希分片:均匀分布写入(适合日志类数据)
- 范围分片:支持高效范围查询(适合时间序列数据)
- 复合分片:结合业务查询模式定制
电商订单分片示例:
# models.py
from pydantic import BaseModel
from datetime import datetime
class OrderShardKey(BaseModel):
region: str # 地域前缀
order_id: str # 哈希分片依据
class OrderDocument(OrderShardKey):
user_id: int
total_amount: float
items: list[dict]
created_at: datetime = datetime.now()
# repository.py
class OrderShardRepository:
def __init__(self, db):
self.orders = db["orders"]
async def insert_order(self, order: OrderDocument):
# 自动路由到对应分片
return await self.orders.insert_one(order.dict())
在Mongo Shell中执行分片配置:
sh.enableSharding("ecommerce")
sh.shardCollection("ecommerce.orders", {"region": 1, "order_id": "hashed"})
四、聚合管道高级应用
处理分片数据时,聚合管道需要特别注意优化策略:
订单分析管道示例:
async def get_regional_sales(start_date: datetime):
pipeline = [
{"$match": {
"created_at": {"$gte": start_date},
"region": {"$exists": True}
}},
{"$group": {
"_id": "$region",
"total_sales": {"$sum": "$total_amount"},
"avg_order": {"$avg": "$total_amount"}
}},
{"$sort": {"total_sales": -1}},
{"$limit": 10}
]
async with shard_client.get_sharded_db("ecommerce") as db:
repo = OrderShardRepository(db)
return await repo.orders.aggregate(pipeline).to_list(1000)
性能优化技巧:
- 在
$match阶段使用分片键作为过滤条件 - 避免在初始阶段使用
$lookup跨分片连接 - 使用
$allowDiskUse处理大型数据集
五、分片索引优化方案
分片集合需要特殊索引策略:
# 创建复合索引
async def create_shard_indexes():
index_model = [
("region", 1),
("created_at", -1),
("user_id", 1)
]
async with shard_client.get_sharded_db("ecommerce") as db:
await db.orders.create_index(
index_model,
name="region_created_user",
background=True
)
索引管理原则:
- 每个分片维护自己的索引
- 避免在频繁更新字段上建索引
- 使用TTL索引自动清理过期数据
六、课后Quiz
为什么在分片集群中要避免使用自增ID作为分片键?
- 答案:会导致写入热点,所有新文档都会路由到同一个分片
聚合管道中
$lookup阶段在分片环境下的限制是什么?- 答案:只能在单个分片内执行,无法跨分片关联文档
如何选择分片集合的索引类型?
- 答案:优先使用覆盖查询的复合索引,结合查询模式设计
七、常见报错解决方案
问题1:No primary server available
motor.errors.ServerSelectionTimeoutError: No primary server available
- 原因:客户端无法连接任何mongos路由
- 解决:
- 检查mongos节点状态
netstat -tulnp | grep 27017 - 验证DNS解析是否正常
- 增加连接超时时间到5000ms
- 检查mongos节点状态
问题2:Query failed with error code 291
Error 291: Cannot $sort with non-equality query on shard key
- 原因:排序字段不包含分片键前缀
- 解决:
- 修改查询包含分片键范围过滤
- 创建包含排序字段的复合索引
- 使用
$merge阶段优化排序
问题3:Operation exceeded time limit
Error 50: Operation exceeded time limit
- 原因:跨分片查询超时
- 解决:
- 添加
maxTimeMS参数延长超时时间 - 优化查询使用分片键过滤
- 在分片键上创建更合适的索引
- 添加
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:FastAPI与MongoDB分片集群:异步数据路由与聚合优化 | cmdragon's Blog
往期文章归档:
- FastAPI与MongoDB Change Stream的实时数据交响曲 | cmdragon's Blog
- 地理空间索引:解锁日志分析中的位置智慧 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的极致性能优化之旅 | cmdragon's Blog
- 异步日志分析:MongoDB与FastAPI的高效存储揭秘 | cmdragon's Blog
- MongoDB索引优化的艺术:从基础原理到性能调优实战 | cmdragon's Blog
- 解锁FastAPI与MongoDB聚合管道的性能奥秘 | cmdragon's Blog
- 异步之舞:Motor驱动与MongoDB的CRUD交响曲 | cmdragon's Blog
- 异步之舞:FastAPI与MongoDB的深度协奏 | cmdragon's Blog
- 数据库迁移的艺术:FastAPI生产环境中的灰度发布与回滚策略 | cmdragon's Blog
- 数据库迁移的艺术:团队协作中的冲突预防与解决之道 | cmdragon's Blog
- 驾驭FastAPI多数据库:从读写分离到跨库事务的艺术 | cmdragon's Blog
- 数据库事务隔离与Alembic数据恢复的实战艺术 | cmdragon's Blog
- FastAPI与Alembic:数据库迁移的隐秘艺术 | cmdragon's Blog
- 飞行中的引擎更换:生产环境数据库迁移的艺术与科学 | cmdragon's Blog
- Alembic迁移脚本冲突的智能检测与优雅合并之道 | cmdragon's Blog
- 多数据库迁移的艺术:Alembic在复杂环境中的精妙应用 | cmdragon's Blog
- 数据库事务回滚:FastAPI中的存档与读档大法 | cmdragon's Blog
- Alembic迁移脚本:让数据库变身时间旅行者 | cmdragon's Blog
- 数据库连接池:从银行柜台到代码世界的奇妙旅程 | cmdragon's Blog
- 点赞背后的技术大冒险:分布式事务与SAGA模式 | cmdragon's Blog
- N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon's Blog
- FastAPI与Tortoise-ORM开发的神奇之旅 | cmdragon's Blog
- DDD分层设计与异步职责划分:让你的代码不再“异步”混乱 | cmdragon's Blog
- 异步数据库事务锁:电商库存扣减的防超卖秘籍 | cmdragon's Blog
- FastAPI中的复杂查询与原子更新指南 | cmdragon's Blog
- 深入解析Tortoise-ORM关系型字段与异步查询 | cmdragon's Blog
- FastAPI与Tortoise-ORM模型配置及aerich迁移工具 | cmdragon's Blog
- 异步IO与Tortoise-ORM的数据库 | cmdragon's Blog
- FastAPI数据库连接池配置与监控 | cmdragon's Blog
- 分布式事务在点赞功能中的实现 | cmdragon's Blog
- Tortoise-ORM级联查询与预加载性能优化 | cmdragon's Blog
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon's Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon's Blog
- 深入解析事务基础与原子操作原理 | cmdragon's Blog
- XML Sitemap
FastAPI与MongoDB分片集群:异步数据路由与聚合优化的更多相关文章
- TiDB和MongoDB分片集群架构比较
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近阅读了TiDB源码的说明文档,跟MongoDB的分片集群做了下简单对比. 首先展示TiDB的整体架构 M ...
- MongoDB分片集群原理、搭建及测试详解
随着技术的发展,目前数据库系统对于海量数据的存储和高效访问海量数据要求越来越高,MongoDB分片机制就是为了解决海量数据的存储和高效海量数据访问而生. MongoDB分片集群由mongos路由进程( ...
- mongodb分片集群
第一章 1.mongodb 分片集群解释和目的 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合.复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础. 第二章 1. ...
- 搭建MongoDB分片集群
在部门服务器搭建MongoDB分片集群,记录整个操作过程,朋友们也可以参考. 计划如下: 用5台机器搭建,IP分别为:192.168.58.5.192.168.58.6.192.168.58.8.19 ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
- MongoDB 分片集群实战
背景 在如今的互联网环境下,海量数据已随处可见并且还在不断增长,对于如何存储处理海量数据,比较常见的方法有两种: 垂直扩展:通过增加单台服务器的配置,例如使用更强悍的 CPU.更大的内存.更大容量的磁 ...
- CentOS7+Docker+MangoDB下部署简单的MongoDB分片集群
简单的在Docker上快速部署MongoDB分片集群 前言 文中使用的环境如下 OS:CentOS Linux release 7.5.1804 (Core) Docker:Docker versio ...
- Windows 搭建MongoDB分片集群(一)
一.角色说明 要构建一个MongoDB分片集群,需要三个角色: shard server 即存储实际数据得分片,每个shard 可以是一个Mongod实例,也可以是一组mongod实例构成得Repl ...
- 分布式文档存储数据库之MongoDB分片集群
前文我们聊到了mongodb的副本集以及配置副本集,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13953598.html:今天我们来聊下mongodb的分片 ...
- MongoDB分片集群机制及原理
1. MongoDB常见的部署架构 * 单机版 * 复制集 * 分片集群 2. 为什么要使用分片集群 * 数据容量日益增大,访问性能日渐下降,怎么破? * 新品上线异常火爆,如何支撑更多用户并发? * ...
随机推荐
- 961. 重复 N 次的元素
地址:https://leetcode-cn.com/problems/n-repeated-element-in-size-2n-array/ <?php /** 在大小为 2N 的数组 A ...
- 百万架构师第四十六课:并发编程的原理(一)|JavaGuide
百万架构师系列文章阅读体验感更佳 原文链接:https://javaguide.net 并发编程的原理 课程目标 JMM 内存模型 JMM 如何解决原子性.可见性.有序性的问题 Synchronize ...
- 单页应用(SPA)是什么?
来源:https://zhuanlan.zhihu.com/p/648113861 概述 单页应用(SPA,Single Page Application)是一种网页应用或网站的设计模式,它在浏览器中 ...
- Web前端入门第 6 问:HTML 的基础语法结构
HTML的全称为超文本标记语言(HyperText Markup Language),基础语法结构由标签.元素.属性和内容组成,遵循层级嵌套的树形结构. 关键语法规则 标签(Tags) 双标签语法 标 ...
- 编写你的第一个 Django 应用程序,第7部分
本教程从教程 6 停止的地方开始.我们将继续使用网络投票应用程序,并将专注于自定义 Django 自动生成的管理站点,这是我们在教程 2 中首次探索的. 一.自定义管理表单 通过用 admin.sit ...
- maven知识理解和生命周期
学习的技能/知识 运动 提升 不足 强化了maven的知识理解和生命周期 3公里日常跑,其中1公里破之前的记录达到3分40 没有赖床,嗯:写完的博客自己阅读又温习了一遍 下午没课,但都用来休息了.. ...
- 我对TamperMonkey的不满-更新中
我认为我的电脑上的TamperMonkey插件的值得考虑的不足: 没有提供一个把脚本最小化的功能 不能编辑热键 脚本icon不能使用svg 没有提供一种很好的能够区分别人的脚本和自己的脚本的方式,自己 ...
- .NET & JSON
C# & JSON DataContractJsonSerializer // JsonHelper.cs using System; using System.Collections.Gen ...
- C# 中合并2个 Dictionary
内置方法 using System.Collections.Generic; using System.Linq; Dictionary<string, object> dicA = ne ...
- 【Guava】并发编程ListenableFuture&Service
MoreExecutors directExecutor ExecutorService executor = Executors.newSingleThreadExecutor(); Settabl ...