CUDA简单介绍
并行计算
并行计算(parallel computing)是一种计算形式,它将大的问题分解为许多可以并行的小问题。
并行计算分为:任务并行(task parallel)和数据并行(data parallel)
- 任务并行指多个任务同时执行
- 数据并行指多个数据可以同时处理,每个数据由独立的线程处理
- 数据并行分块方法有:块分(block partitioning)和循环分块(cyclic partitioning)
PS:
块分和循环分块是两种不同的编程技术,用于将代码分成更小的块以提高代码的可读性和可维护性。
- 块分是指将一段代码分成多个块,每个块执行特定的任务。这些块可以是函数、方法或代码块。块分的目的是将代码逻辑分解为更小的部分,使得每个块只负责一个特定的功能。这样做的好处是可以更容易地理解和调试代码,也可以更方便地重用代码。块分还可以提高代码的可读性,因为每个块都有一个清晰的目的和功能。
- 循环分块是指在循环中将一段代码分成多个块,每个块在每次循环迭代时执行一次。循环分块的目的是将循环体内的代码逻辑分解为更小的部分,使得每个块只负责一个特定的功能。这样做的好处是可以更容易地理解和调试循环体内的代码,也可以更方便地重用代码。循环分块还可以提高代码的可读性,因为每个块都有一个清晰的目的和功能,并且可以更容易地理解循环的逻辑。
总结起来,块分和循环分块都是将代码分解为更小的部分的技术,以提高代码的可读性、可维护性和重用性。
块分适用于将整个代码分解为多个功能块,而循环分块适用于将循环体内的代码分解为多个功能块。无论是块分还是循环分块,都可以帮助我们更好地组织和管理代码。
异构计算
异构计算(heterogeneous computing)是对并行计算的延伸,是高性能计算发展的里程碑。
异构计算指在具有多种类型处理器(CPU和GPU)的系统中完成的计算。
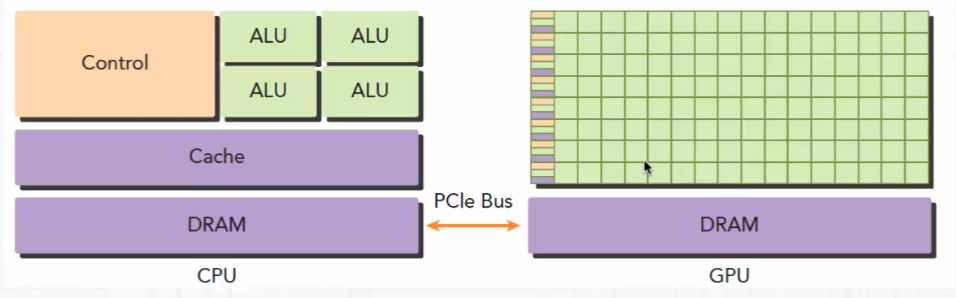
CPU擅长与逻辑处理,GPU擅长数据处理,在通用的异构计算结构中,两者可通过PCIe总线进行连接,使其发挥各自擅长的部分。
在异构计算的程序中,包含了运行在GPU的程序也包含了运行在CPU的程序
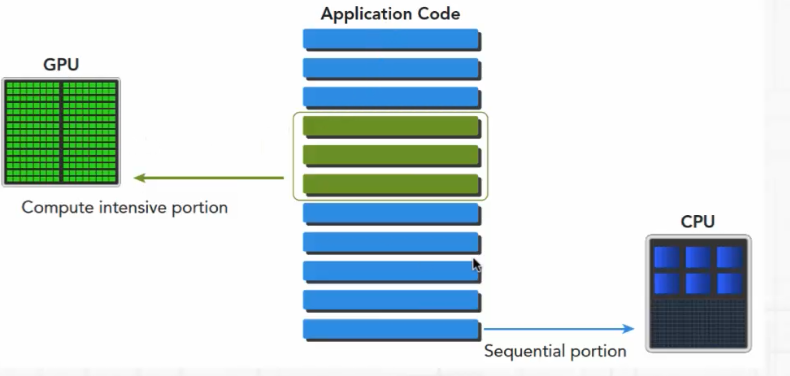
因GPU上有很多线程,因此在GPU上的执行是一个并行的数据处理
GPU性能指标
- GPU核心数(core number)
- GPU内存容量
- 计算峰值
每秒钟单精度或双精度运算能力
- 内存带宽
每秒钟读出或 写入GPU内存的数据量
CUDA
CUDA(Compute Unified Device Architecture)是英伟达公司推出的基于GPU的通用高性能计算平台和编程模型。
可以通过CUDA充分利用英伟达GPU的强大计算能力
CUDA平台的架构如下图:
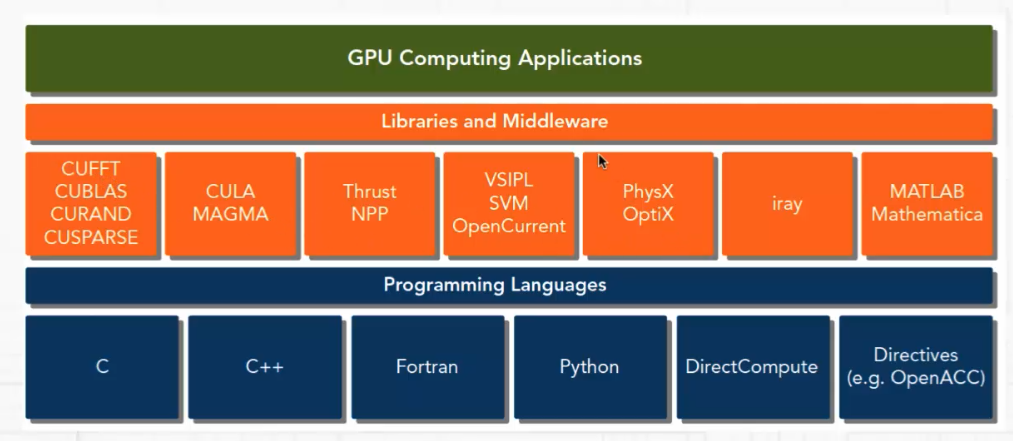
CUDA平台提供了驱动层接口(Driver API)和运行时接口(Runtime API)
基于运行时接口,CUDA的然见架构图如下:
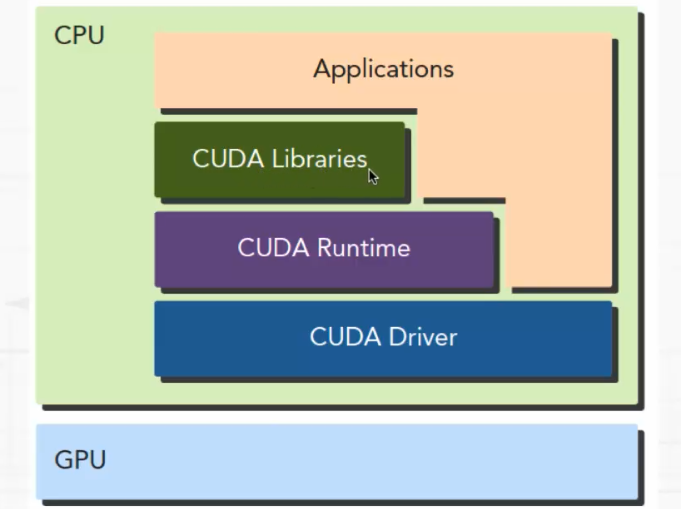
基于CUDA平台开发的程序包含了主机代码和设备代码
主机代码:主要执行流程控制或者是业务层控制
设备代码:主要是数据的并行计算
CUDA程序从程序代码层次的架构
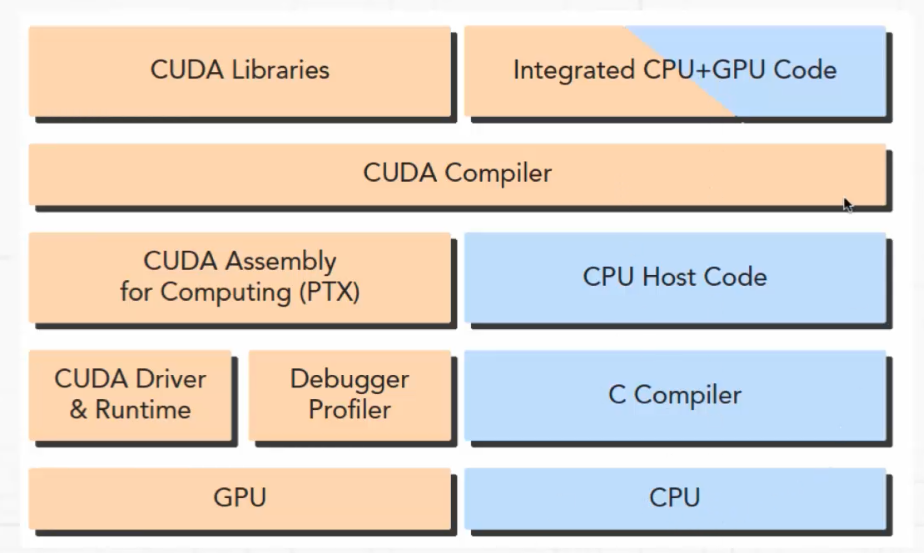
PS:
建议:
在对cuda的学习中,要注意或掌握一下几点:
- CUDA C编程时只需要编写程序顺序执行的程序,在程序代码中不需要有多线程的处理。
- 需要深刻理解CUDA平台GPU的内存结构和线程架构,并掌握对其控制和优化方法
掌握CUDA平台的常用性能分析和调优工具:
1.NVIDIA Nsight
2.CUDA-GDB
3.其他一些图形化的性能分析工具
GPU相关的linux命令
查看GPU类型:
lspci | grep -i nvidia

lspci是一个用于显示计算机上PCI设备信息的命令。
uname -m && cat /etc/*release
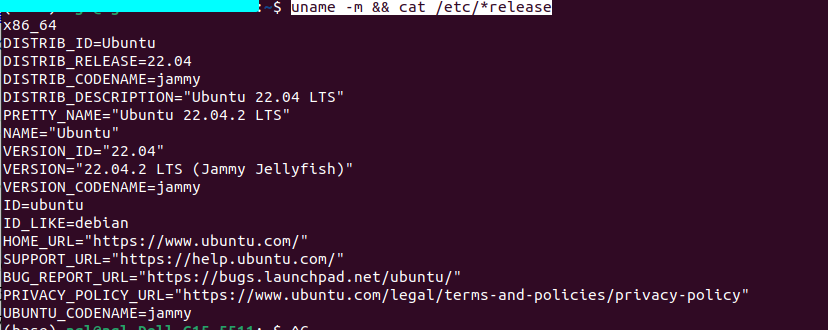
uname -m:这个命令用于获取机器的硬件架构信息。它会返回一个字符串,表示机器的架构类型,比如 x86_64、i686 等。
cat /etc/*release:这个命令用于查看操作系统的发行版信息。/etc/*release是一个文件路径模式,它会匹配所有以 release 结尾的文件。在大多数 Linux 发行版中,这些文件包含了操作系统的版本和其他相关信息。
nvidia-smi -q
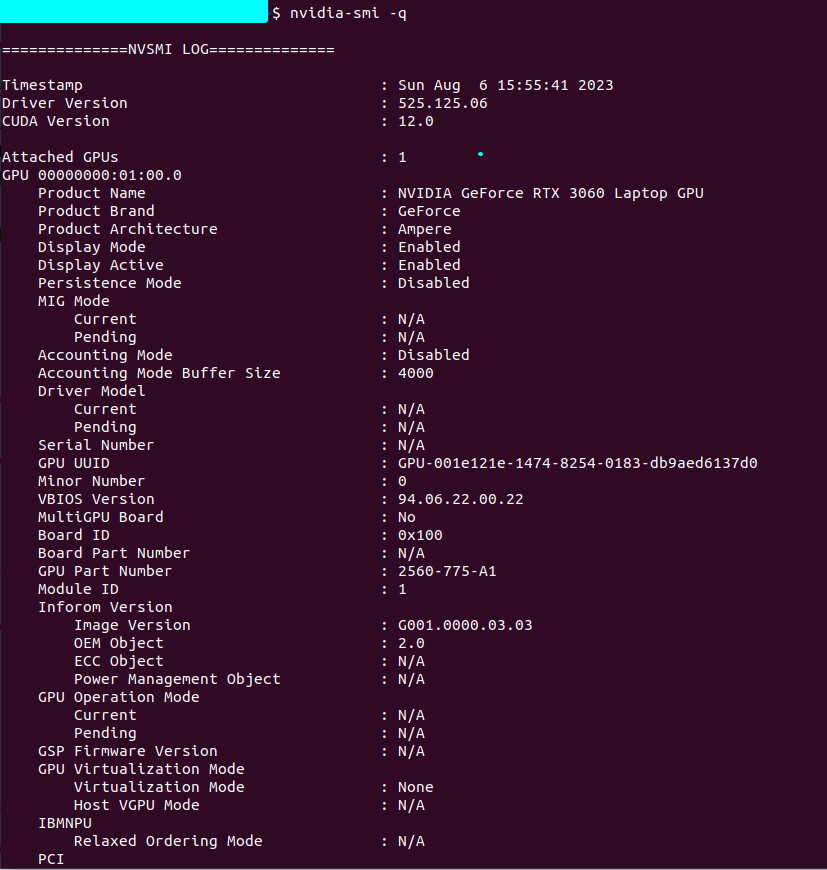
nvidia-smi -q是一个用于查询NVIDIA GPU的命令行工具。它提供了有关GPU硬件和驱动程序的详细信息,包括GPU的型号、驱动程序版本、温度、功耗、内存使用情况等。
nvidia-smi -L

nvidia-smi -L是一个用于显示系统中所有 NVIDIA GPU 设备的命令。它可以帮助您确定系统中有多少个 NVIDIA GPU 设备以及它们的标识符。
当您运行 nvidia-smi -L 命令时,它会返回一个类似于以下格式的输出:GPU 0: GeForce GTX 1080 (UUID: GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)
GPU 1: GeForce GTX 1060 (UUID: GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)
每个 GPU 设备都有一个唯一的标识符(UUID),以及一个友好的名称(例如 "GeForce GTX 1080")。通过这些信息,您可以确定系统中有多少个 GPU 设备,并使用它们进行编程或其他操作。
编程模型
编程模型是对底层计算机硬件架构的抽象表达
编程模型作为应用程序和底层架构的桥梁
编程模型体现在程序开发语言和开发平台中
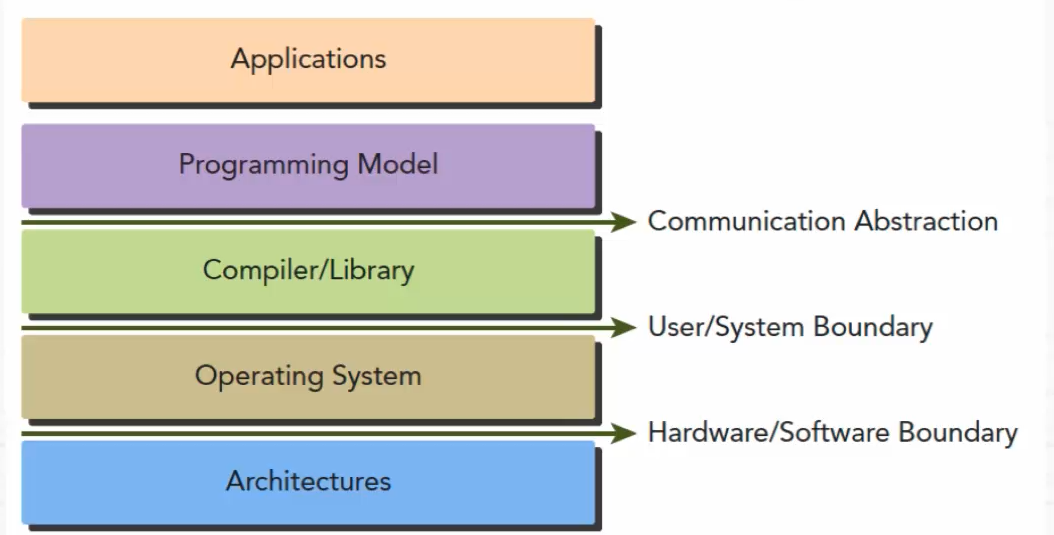
CUDA平台编程模型的特点:
CUDA平台对线程的管理
CUDA 平台提供了线程抽象接口控制GPU中的线程
CUDA平台对内存访问的控制
- 主机内存和GPU设备内存
- GPU和CPU之间内存数据传递
内核函数(kernel function)
- 内核函数本身不包含任何并行性,由GPU协调处理线程执行内核
- CPU 和 GPU处于异步执行状态
运行时GPU信息查询相关API
API接口方法:
获取GPU数量:cudaGetDeviceCount
设置需要使用的GPU:cudaSetDevice
获取GPU信息:cudaGetDeviceProperties
CUDA简单介绍的更多相关文章
- professional cuda c programming--CUDA库简单介绍
CUDA Libraries简单介绍 上图是CUDA 库的位置.本文简要介绍cuSPARSE.cuBLAS.cuFFT和cuRAND.之后会介绍OpenACC. cuSPARSE线性代数库,主要针 ...
- 【浅墨著作】《OpenCV3编程入门》内容简单介绍&勘误&配套源码下载
经过近一年的沉淀和总结,<OpenCV3编程入门>一书最终和大家见面了. 近期有为数不少的小伙伴们发邮件给浅墨建议最好在博客里面贴出这本书的文件夹,方便大家更好的了解这本书的内容.事实上近 ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- yii2的权限管理系统RBAC简单介绍
这里有几个概念 权限: 指用户是否可以执行哪些操作,如:编辑.发布.查看回帖 角色 比如:VIP用户组, 高级会员组,中级会员组,初级会员组 VIP用户组:发帖.回帖.删帖.浏览权限 高级会员组:发帖 ...
- angular1.x的简单介绍(二)
首先还是要强调一下DI,DI(Denpendency Injection)伸手获得,主要解决模块间的耦合关系.那么模块是又什么组成的呢?在我看来,模块的最小单位是类,多个类的组合就是模块.关于在根模块 ...
- Linux的简单介绍和常用命令的介绍
Linux的简单介绍和常用命令的介绍 本说明以Ubuntu系统为例 Ubuntu系统的安装自行百度,或者参考http://www.cnblogs.com/CoderJYF/p/6091068.html ...
- iOS-iOS开发简单介绍
概览 终于到了真正接触IOS应用程序的时刻了,之前我们花了很多时间去讨论C语言.ObjC等知识,对于很多朋友而言开发IOS第一天就想直接看到成果,看到可以运行的IOS程序.但是这里我想强调一下,前面的 ...
- iOS开发多线程篇—多线程简单介绍
iOS开发多线程篇—多线程简单介绍 一.进程和线程 1.什么是进程 进程是指在系统中正在运行的一个应用程序 每个进程之间是独立的,每个进程均运行在其专用且受保护的内存空间内 比如同时打开QQ.Xcod ...
随机推荐
- Vulnhun靶机-kioptix level 4-sql注入万能密码拿到权限ssh连接利用mysql-udf漏洞提权
一.环境搭建 然后选择靶机所在文件夹 信息收集 本靶机ip和攻击机ip 攻击机:192.168.108.130 靶机:192.168.108.141 扫描ip 靶机ip为:192.168.108.14 ...
- Deepseek学习随笔(3)--- 高效提问技巧
明确需求 在与 DeepSeek 互动时,明确需求是获取高质量回复的关键.以下是一些示例: 错误示例:帮我写点东西 这样模糊的指令无法让 DeepSeek 理解你的具体需求,生成的回复可能无法满足你的 ...
- 雷电4扩展坞HDMI显示器无法睡眠问题
背景: 最近使用Dell的雷电4扩展坞WD22TB4,感觉很爽,取电脑时,不用再拔显示器.鼠标.键盘,直接把雷电4接口拔出即可. 后来通过windows update升级了intel显卡驱动后,发现电 ...
- MySQL - [07] 查看库表数据所使用的空间大小
1.切换数据库:use information_schema; 2.查看数据库使用大小 SELECT concat(round(sum(data_length/1024/1024),2),'MB') ...
- 全源最短路——Johnson 算法
一.问题引入 目前我们所知道的一些常见的最短路算法有 dijkstra.spfa.floyd. dijkstra 和 spfa 是单源最短路,floyd 是多源最短路. 如果我们需要在 \(O(nm) ...
- Pwnable_orw
题源 题解 保护 只开启了栈保护 分析 进入ida分析 main函数如下 seccomp (Secure Computing Mode)是一种 Linux 内核安全机制,它可以 限制进程可执行的系统调 ...
- 提示词工程——AI应用必不可少的技术
引言 在人工智能技术飞速发展的今天,大语言模型(LLM)已成为推动技术革新的核心引擎.然而,如何让这些"聪明"的模型真正落地业务场景.解决实际问题?答案往往不在于模型本身的参数规模 ...
- Basics of using bash, and shell tools for covering several of the most common tasks
Basics of using bash, and shell tools for covering several of the most common tasks Introduction M ...
- WARN Issues with peer dependencies found,pnpm peer dependencies auto-install
前言 pnpm 也需要设置自动安装对等依赖项 解决 pnpm 使用 npm 的配置格式,所以应该以与 npm 相同的方式设置配置: pnpm config set auto-install-peers ...
- 远程连接到轻量应用服务器PG数据库
不建议这样做,但是开发时方便需要.进入正题. PG是不支持远程连接的,需要连接直接该参数. 在其data目录里,有二个配置文件: pg_hba.conf:配置数据库的访问权限 postgresql.c ...