机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC
精确率、召回率、F1、AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢。下面让我们分别来看一下这几个指标分别是什么意思。
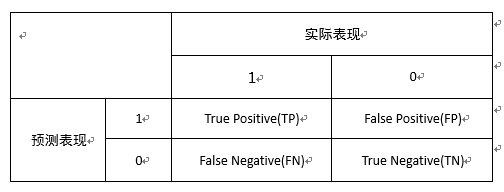
针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
如下图所示:
精确率(Precision)为TP/(TP+FP),即实际是正类并且被预测为正类的样本占所有预测为正类的比例,精确率更为关注将负样本错分为正样本(FP)的情况。
召回率(Recall)为TP/(TP+FN),即实际是正类并且被预测为正类的样本占所有实际为正类样本的比例,召回率更为关注将正样本分类为负样本(FN)的情况。
F1值是精确率和召回率的调和均值,即F1=2PR/(P+R) (P代表精确率,R代表召回率),相当于精确率和召回率的综合评价指标。
有的时候,我们对recall 与 precision 赋予不同的权重,表示对分类模型的偏好:
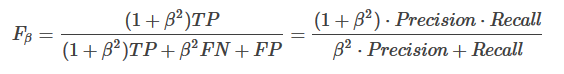
可以看到,当 ,那么就退回到了, 其实反映了模型分类能力的偏好, 的时候,precision的权重更大,为了提高,我们希望precision 越小,而recall 应该越大,说明模型更偏好于提升recall,意味着模型更看重对正样本的识别能力; 而 的时候,recall 的权重更大,因此,我们希望recall越小,而precision越大,模型更偏好于提升precision,意味着模型更看重对负样本的区分能力。
ROC曲线其实是多个混淆矩阵的结果组合,如果在上述模型中我们没有定好阈值,而是将模型预测结果从高到低排序,将每个概率值依次作为阈值,那么就有多个混淆矩阵。
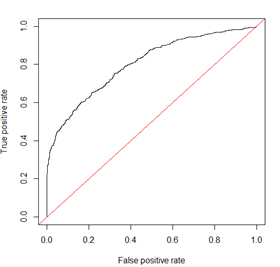
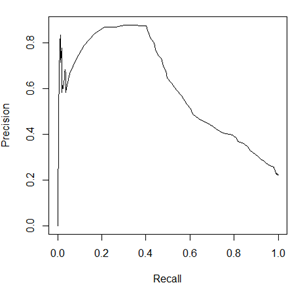
除此之外,在评价模型时还会用到KS(Kolmogorov-Smirnov)值,KS=max(TPR-FPR),即为TPR与FPR的差的最大值,KS值可以反映模型的最优区分效果,此时所取的阈值一般作为定义好坏用户的最优阈值。
相对来讲ROC曲线会稳定很多,在正负样本量都足够的情况下,ROC曲线足够反映模型的判断能力。
因此,对于同一模型,PRC和ROC曲线都可以说明一定的问题,而且二者有一定的相关性,如果想评测模型效果,也可以把两条曲线都画出来综合评价。
对于有监督的二分类问题,在正负样本都足够的情况下,可以直接用ROC曲线、AUC、KS评价模型效果。在确定阈值过程中,可以根据Precision、Recall或者F1来评价模型的分类效果。
对于多分类问题,可以对每一类分别计算Precision、Recall和F1,综合作为模型评价指标。
机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋的更多相关文章
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- LightGBM详细用法--机器学习算法--周振洋
LightGBM算法总结 2018年08月21日 18:39:47 Ghost_Hzp 阅读数:2360 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 机器学习sklearn的快速使用--周振洋
ML神器:sklearn的快速使用 传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类.本文我们将依据传统 ...
- XGBoost——机器学习--周振洋
XGBoost——机器学习(理论+图解+安装方法+python代码) 目录 一.集成算法思想 二.XGBoost基本思想 三.MacOS安装XGBoost 四.用python实现XGBoost算法 在 ...
- LightGBM的并行优化--机器学习-周振洋
LightGBM的并行优化 上一篇文章介绍了LightGBM算法的特点,总结起来LightGBM采用Histogram算法进行特征选择以及采用Leaf-wise的决策树生长策略,使其在一批以树模型为基 ...
- 准确率、精确率、召回率、F1
在搭建一个AI模型或者是机器学习模型的时候怎么去评估模型,比如我们前期讲的利用朴素贝叶斯算法做的垃圾邮件分类算法,我们如何取评估它.我们需要一套完整的评估方法对我们的模型进行正确的评估,如果模型效果比 ...
- [机器学习] 性能评估指标(精确率、召回率、ROC、AUC)
混淆矩阵 介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix).对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果.对于常见的二元分类,它的混淆矩阵是 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- Recall(召回率)and Precision(精确率)
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7668501.html 前言 机器学习中经过听到" ...
随机推荐
- Android学习笔记_43_网络通信之文件断点上传
1.建立服务端,用于接收上传的文件.这里使用Socket,文件可能会比较大.采用多线程编程,防止并发. package com.socket.service; import java.io.File; ...
- Xtrabackup备份与恢复MySQL
1.innobackupex备份原理 .innobackupex启动并fork一个进程启动xtrabackup,然后等待xtrabackup备份InnoDB文件; .xtrabackup备份时存在两个 ...
- NSString+JSON - iOS
日常开发中常用的一个相互转换的方法; 直接创建对应的类,引用如下方法即可实现; 具体 code 如下: 声明: #import <Foundation/Foundation.h> @int ...
- vue、html与iframe html事件相互调用
一.html文件中引入的iframe标签 1.在父html中调用子iframe html 中的事件 通过contentwindow属性 document.getElementById("my ...
- ETO的公开赛T2《宏聚变》 题解(BY 萌萌哒123456 )
我们注意到这道题中最多有 $(n+q)$ 个数被加入,而每个数最多被删除一次,因此每次操作 $O(logn)$的复杂度是可以接受的. 我们对于$1..100000$之间每个数分别开一个set,维护这个 ...
- python实现简单决策树(信息增益)——基于周志华的西瓜书数据
数据集如下: 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 青绿 蜷缩 沉闷 清晰 ...
- 分布式日志系统ELK搭建
ELK:Elasticsearch Logstash Kibana Elasticsearch:是基于JSON的分布式搜索和分析引擎,专为实现水平扩展.高可用和管理便捷性而设计 Logstash:是 ...
- web前端总结面试问题<经常遇到的手写代码>
冒泡排序 var arr = [5,8,3,6,9] for(var i=0;i<arr.length;i++){ for(var j=i+1;j<arr.length;j++){ if( ...
- Sencha Themer
Sencha Themer 1:介绍 在Ext JS中创建自定义主题一直是一项挑战.但是使用Sencha Themer,我们已经删除了所有的猜测工作,并添加了一个简单的图形界面来定制应用程序的任何方面 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...