自己用 python 实现 base64 编码
自己用 python 实现 base64 编码
base64 编码原理
二进制文件中包含有很多无法显示和打印的字符,二进制的数据一般以 ASCII 码形式(8 bit,即一个字节)存储,8 bit 可以表示 128 个不同的编码,而 ASCII 码中有 33 个编码表示的不是显示或打印的字符:
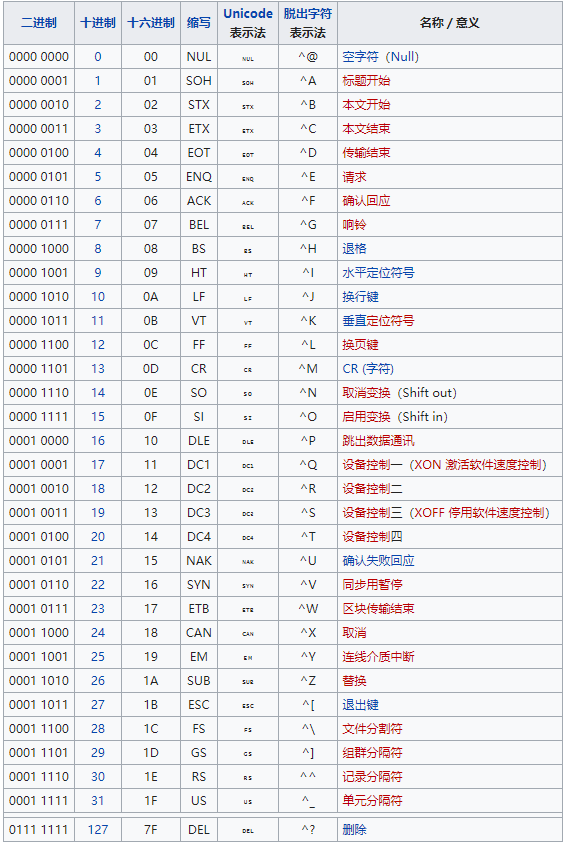
图片来自维基百科
剩下的编码表示的是可以打印的字符:

图片来自维基百科
当处理二进制文件中的数据时,就需要将无法显示或打印的字符进行转换,Base64 编码的原理就是将这 128 个不同的编码(可以打印或不可打印的字符)映射到 64 个可以打印的字符集中。
准备字符数组/字符串
首先准备 64 个可以显示/打印的字符数组(字符串),可以用 chr 将十进制数据转换成相应的字符,然后构造成字符数组:
def constructTable():
array = []
for i in range( 65, 91 ):
array.append( chr( i ) )
for i in range( 97, 123 ):
array.append( chr( i ) )
for i in range( 0, 10 ):
array.append( str( i ) )
array.append( '+' )
array.append( '-' )
# print( array )
return array
也可以用 string 提供的常量构造出一个字符串:
def constructTable2():
str = string.ascii_uppercase + string.ascii_lowercase + string.digits
return str + '+' + '-'
两者取出相应位置的字符都可以用数组的形式,比如用 table 保存字符数组/字符串,table[2] 就是 C。
处理数据
接下来对二进制数据进行处理,每 3 个字节一组进行处理即可:
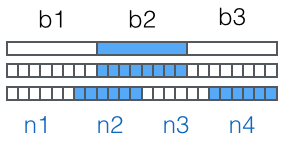
图片来自廖雪峰的官方教程
只考虑数据字节数为 3 的情况,将其重新编码:
def _b64encode_str( s0, s1, s2 ):
"""
s0、s1、s2 依次为第一、二、三个字符
"""
d = s2 & 63
d = array[ d ]
c1 = ( s1 & 15 ) << 2
c2 = ( s2 & 192 ) >> 6
c = c1 + c2
c = array[ c ]
b1 = ( s0 & 3 ) << 4
b2 = ( s1 & 240 ) >> 4
b = b1 + b2
b = array[ b ]
a = ( s0 & 252 ) >> 2
a = array[ a ]
return ''.join( [ a, b, c, d ] )
这里的思路是从右往左,依次计算出 d、c、b、a,也就是对应着上图的 n4、n3、n2、n1。当要编码的数据不是 3 的倍数时,需要在数据末尾用 \x00 补足成 3 的倍数,最后根据补 \x00 的次数在编码后的字符串中添加相应个数的 =。
# input is str
length = len( str )
remainder = length % 3
# fill with zero
if( remainder == 1 ):
str = str + b'\x00\x00' # add twice
length += 2
elif( remainder == 2 ):
str = str + b'\x00' # add once
length += 1
之后,再将原始数据进行编码,先考虑简单的 remainder == 0 的情况,每 3 个字符一组进行编码即可:
i = 0
buf = StringIO()
while i < length:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3
如果 remainder != 0,那么最后的三个字符中有添加的 =,这三个字符需要特殊处理,前面的字符和上面的处理方式一样,在最后返回的时候调用字符串的 encode 方法将其转为二进制:
while i < length - 3:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3
# print( remainder, i, buf.getvalue() )
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en[ 0 ] )
buf.write( en[ 1 ] )
if( remainder == 2 ):
buf.write( en[ 2 ] ) # add once
buf.write( '=' )
elif( remainder == 1 ):
buf.write( '==' ) # add twice
然后编写一个简单的测试文件,简单验证下自己编写的 b64encode 方法是否正确:
def randomString():
# print( chars )
size = random.randint( 70, 100 )
rstr = ''.join( random.SystemRandom().choices( _CHARS, k = size ) )
return rstr.encode()
def compare():
rstr = randomString()
exp = base64.b64encode( rstr )
act = mybase64.b64encode( rstr )
if( exp != act ):
print( rstr )
print( exp )
print( act )
raise ValueError
loops = 10000
print( 'encode comp: ', timeit.timeit( stmt = compare, number = loops ) )
按照标准的 Base64 编码编写的代码没有问题。
性能比较
最后将 Python 自带的 base64 编码和自己编写的编码函数进行比较:
def encode1():
rstr = randomString()
base64.b64encode( rstr )
def encode2():
rstr = randomString()
mybase64.b64encode( rstr )
loops = 10000
print( sys.version )
print( 'random: ', timeit.timeit( randomString, number = loops ) )
print( 'encode1: ', timeit.timeit( stmt = encode1, number = loops ) )
print( 'encode2: ', timeit.timeit( stmt = encode2, number = loops ) )
输出结果如下:

小结
可以看到,自己编写的编码方法用时大约 0.447 seconds, base64 库提供的方法的用时约为 0.030 seconds,性能差距约 15 倍。所以一般没有必要自己实现 base64 编码。
另外测试中相应的 decode 方法是没有实现的,实现起来也比较简单,按照编码的方式反过来做就好了。
代码地址:github
Notable
- python 中 str 对象执行 encode 方法后字符串将会以二进制形式保存
- chr( 1 ) 返回值是
'\x01',对应的是不可打印的字符,str( 1 ) 返回值是'1',是可以打印的字符。
Reference
- convert-string-to-binary-in-python
- Python 语言中的按位运算
- 与 Java SrtingBuffer 等效的 python 对象
- 随机字符串
- 廖雪峰的 Python 教程
自己用 python 实现 base64 编码的更多相关文章
- Python 模拟 Base64编码
Base64编码原理:https://blog.csdn.net/wo541075754/article/details/81734770 def Enbs64(s): # 编码后的结果 result ...
- Python 中 base64 编码与解码
base64 是经常使用的一种加密方式,在 Python 中有专门的库支持. 本文主要介绍在 Python2 和 Python3 中的使用区别: 在 Python2 环境: Python 2.7.16 ...
- python中base64编码与解码
在python3中用base64进行编码和解码的时候特别注意: 题目要求: 准备一张.jpg图片,比如:mm.jpg,读取图片数据并通过b85encode加密之后写入到新文件mm.txt文件中,然后读 ...
- Python使用base64编码的问题
有的时候,在base64解码的时候,由于字节问题出现解码错误.解决的办法就是不足原base64子串的长度: def decode_base64(data): """ De ...
- python裁剪base64编码的图片
简介 今天遇到需要裁剪base64字符串的PNG图片,并返回base64格式字符串的任务,捣鼓半天. 裁剪代码如下: def deal_inspect_img(base64_str): "& ...
- Python Base64 编码
0x00 Base64简介 0x01 常用场景举例 0x02 编.解码流程 0x03 Python中Base64编码与解码 0x00 Base64简介 我们知道在计算机中任何数据都是按ascii码存储 ...
- Python base64编码,转图片
我在做火车票抢票器的时候遇到一个问题,就是验证码提取的:一般验证码都是一些http请求的url,但是火车票网站遇到了我没有见过的以data:image/jpg;base64开头的字符串.现在我们就用P ...
- Python中进行Base64编码和解码
Base64编码 广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符.优点:速度快,ascii字符,肉眼不可理解缺点:编码比较长,非常容 ...
- Python和shell中Base64编码使用那些事
做开发第一个接触的编码方式就是Base64,当时是用url来传输一些参数,传输的两端会用Base64来编码和解码,保证数据不被url转义破坏. 下面是 维基百科 Base64 中的介绍,其实自己实现起 ...
随机推荐
- android studio中使用recyclerview小白篇(四)
经过努力,我们的recyclerview终于可以使用了,但是装配上真实的数据后,发现左边的内容太长了,如果超过一行,左边内容和右边的内容竟然重叠在一起了,好是让人心塞啊,如下图 后来发现设置左边tex ...
- [.net 多线程]AutoResetEvent, ManualResetEvent
ManualResetEvent: 通知一个或多个正在等待的线程已发生事件,允许线程通过发信号互相通信,来控制线程是否可心访问资源. Set() : 用于向 ManualResetEvent 发送信号 ...
- UI控件的位置
1.该位置指的是本控件的中心点位于点 (100, 100)上(不包含尺寸),可以用于中心对齐在使用frame设置位置的情况下 self.view.center = CGPointMake(100, 1 ...
- 深度学习之 TensorFlow(一):基础库包的安装
1.TensorFlow 简介:TensorFlow 是谷歌公司开发的深度学习框架,也是目前深度学习的主流框架之一. 2.TensorFlow 环境的准备: 本人使用 macOS,Python 版本直 ...
- 【ARC083E】Bichrome Tree 树形dp
Description 有一颗N个节点的树,其中1号节点是整棵树的根节点,而对于第ii个点(2≤i≤N)(2≤i≤N),其父节点为PiPi 对于这棵树上每一个节点Snuke将会钦定一种颜色(黑或白), ...
- Mysql导入数据时-data truncated for column..
在导入Mysql数据库时,发现怎么也导入不进去数据,报错: 查看表定义结构:可以看到comm 定义类型为double类型 原来是因为数据库文件中: 7369 smith clerk ...
- 有关git的使用,和git的一些提交冲突。
git 的一些基本用法 git init :初始化文件(创建文件夹). git add . :监控工作区的状态树(将被修改的文件提交到暂存区) git status :未跟踪状态(Untracked) ...
- Flink生态与未来
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 获取一个表中的字段总数(mysql) Navicat如何导出Excel格式表结构 获取某个库中的一个表中的所有字段和数据类型
如何获取一个表中的字段总数 1.function show columns from 表明: 结果 : 2.functiuon select count(*) from INFORMATION_SCH ...
- window 7/8/10 安装nginx
1.百度 nginx 找到 http://nginx.org/ 官网 2.找到一个nginx 版本 如 最新版本 2018-12-25 nginx-1.15.8 mainline v ...