用API爬取天气预报数据
1.注册免费API和阅读技术文档:
注册地址:https://console.heweather.com
文档地址:https://www.heweather.com/documents/api-url

在文档中可以看到很多参数
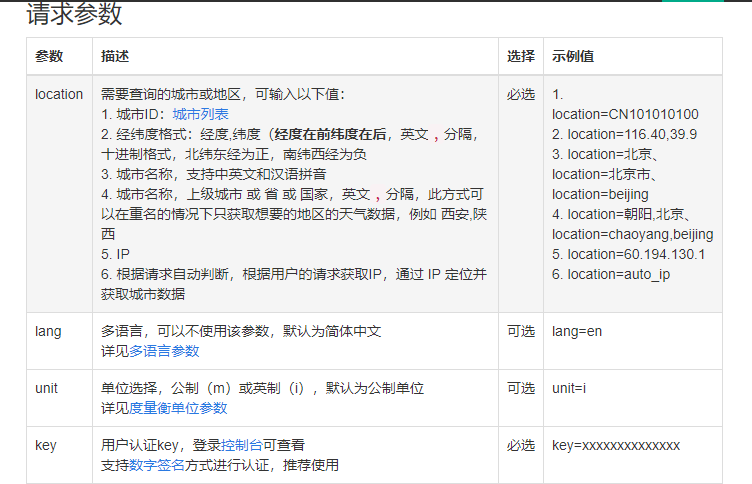

返回的是json数据
2.获取API数据:
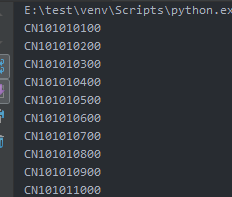
获取城市列表:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
url='https://cdn.heweather.com/china-city-list.txt'
strhtml = requests.get(url)
data = strhtml.text
data1 = data.split("\n")
for i in range(6): #因为前六行不需要,所以没有打印
data1.remove(data1[0])
for item in data1:
print(item[2:13])
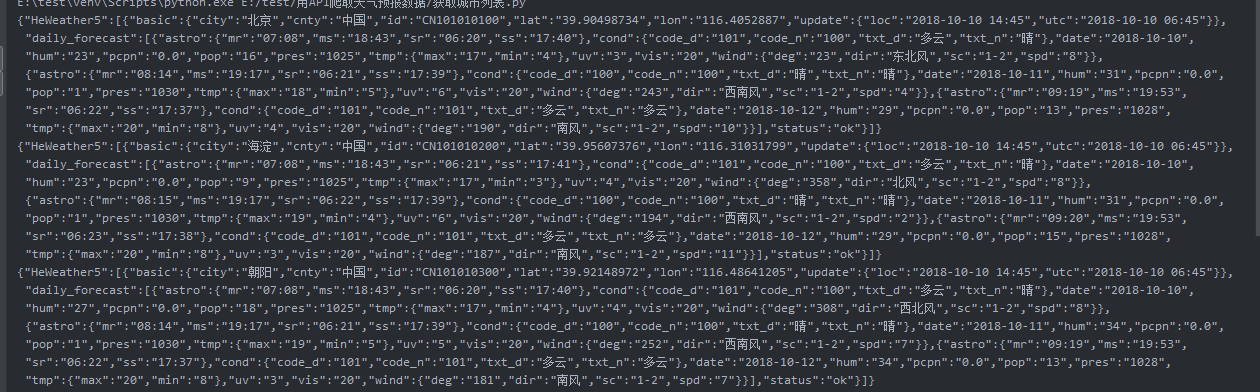
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
import time
url='https://cdn.heweather.com/china-city-list.txt'
strhtml = requests.get(url)
data = strhtml.text
data1 = data.split("\n")
for i in range(6): #因为前六行不需要,所以没有打印
data1.remove(data1[0])
for item in data1:
# print(item[2:13])
url = 'https://free-api.heweather.com/v5/forecast?city='+item[2:13]+'&key=7d0daf2a85f64736a42261161cd3060b'
strhtml = requests.get(url)
time.sleep(1)
print(strhtml.text)
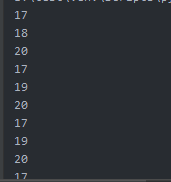
获取当天温度的最大值:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
import time
url='https://cdn.heweather.com/china-city-list.txt'
strhtml = requests.get(url)
data = strhtml.text
data1 = data.split("\n")
for i in range(6): #因为前六行不需要,所以没有打印
data1.remove(data1[0])
for item in data1:
# print(item[2:13])
url = 'https://free-api.heweather.com/v5/forecast?city='+item[2:13]+'&key=7d0daf2a85f64736a42261161cd3060b'
strhtml = requests.get(url)
time.sleep(1)
dic = strhtml.json()
for item in dic["HeWeather5"][0]["daily_forecast"]:
print(item["tmp"]["max"])
往mysql数据库中存入id,city,cnty三个字段数据:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import json
import pymysql
import requests
import time def prem(db):
cursor = db.cursor()
cursor.execute("SELECT VERSION()")
data = cursor.fetchone()
print("Database version : %s " % data) # 结果表明已经连接成功
cursor.execute("DROP TABLE IF EXISTS weatherInfo") # 如果存在表就删除原表
sql = """CREATE TABLE weatherInfo (
id varchar(20),
city varchar(20),
cnty varchar(20))"""
cursor.execute(sql) # 根据需要创建一个表格 def reviewdata_insert(db):
url = 'https://cdn.heweather.com/china-city-list.txt'
strhtml = requests.get(url)
data = strhtml.text
data1 = data.split("\n")
for i in range(6): # 因为前六行不需要,所以没有打印
data1.remove(data1[0])
for item in data1:
# print(item[2:13])
url = 'https://free-api.heweather.com/v5/forecast?city=' + item[2:13] + '&key=7d0daf2a85f64736a42261161cd3060b'
strhtml = requests.get(url)
time.sleep(1)
dic = strhtml.json()
id = dic["HeWeather5"][0]["basic"]["id"]
city = dic["HeWeather5"][0]["basic"]["city"]
cnty = dic["HeWeather5"][0]["basic"]["cnty"]
result=[]
result.append((id,city,cnty))
insert_we = "insert into weatherInfo(id,city,cnty) values (%s,%s,%s)"
cursor = db.cursor()
cursor.executemany(insert_we, result)
db.commit() if __name__ == "__main__": # 起到一个初始化或者调用函数的作用
db = pymysql.connect("localhost", "root", "", "test", charset='utf8')
cursor = db.cursor()
prem(db)
reviewdata_insert(db)
cursor.close()
执行结果:
用API爬取天气预报数据的更多相关文章
- 和风api爬取天气预报数据
''' 和风api爬取天气预报数据 目标:https://free-api.heweather.net/s6/weather/forecast?key=cc33b9a52d6e48de85247779 ...
- 百度地图POI数据爬取,突破百度地图API爬取数目“400条“的限制11。
1.POI爬取方法说明 1.1AK申请 登录百度账号,在百度地图开发者平台的API控制台申请一个服务端的ak,主要用到的是Place API.检校方式可设置成IP白名单,IP直接设置成了0.0.0.0 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬虫爬取天气数据并图形化显示
前言 使用python进行网页数据的爬取现在已经很常见了,而对天气数据的爬取更是入门级的新手操作,很多人学习爬虫都从天气开始,本文便是介绍了从中国天气网爬取天气数据,能够实现输入想要查询的城市,返回该 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- Golang+chromedp+goquery 简单爬取动态数据
目录 Golang+chromedp+goquery 简单爬取动态数据 Golang的安装 下载golang软件 解压golang 配置golang 重新导入配置 chromedp框架的使用 实际的代 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- Node.js爬取豆瓣数据
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远.众所周知,vue-cli基于webpack,而webpack基于node,对node不了 ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
随机推荐
- 通过snmp监控linux
一.linux snmpd安装 yum install -y net-snmp net-snmp-utils 二.snmp的配置(vim /etc/snmp/snmpd.conf) com2sec n ...
- 基于HTML5的RDP访问实战
基于HTML5的RDP访问实战 1.安装guacamole 2.下载源码 3.安装服务端 安装报错 错误 参考 http://www.remotespark.com/html5.html ...
- 10个android开发必备的开源项目
You are here: Home » » Blog » 10 Open Source Android Apps which every Android developer must look in ...
- Openssl gendsa命令
一.简介 gendsa命令能够根据DSA密钥参数生成DSA密钥 二.语法 openssl gendsa [-out filename] [-passout out] [-rand file(s)] [ ...
- 往数据库添加的时候(只添加以前未添加的记录的写法)c#
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- scp 的时候提示WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
摘自:https://blog.csdn.net/haokele/article/details/72824847 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ ...
- LWIP数据包管理
- (转)TinyHttp源码剖析
tinyhttpd 是一个不到 500 行的超轻量型 Http Server,用来学习非常不错,可以帮助我们真正理解服务器程序的本质. 看完所有源码,真的感觉有很大收获,无论是 unix 的编程,还是 ...
- HDU 3363 Ice-sugar Gourd (贪心)
题意:给你一个串,串中有H跟T两种字符,然后切任意刀,使得能把H跟T各自分为原来的一半. 析:由于只有两个字母,那么只要可以分成两份,那么一定有一段是连续的. 代码如下: #include <c ...
- up7.1-asp.net-本地测试教程
1.1. ASP.NET 框架:.NET Framework 4.5 依赖库:csredis,Newtonsoft.Json 安装redis 下载 redis-x64:http://pan.bai ...