Logstash 性能及其替代方案
介绍
当谈及集中日志到 Elasticsearch 时,首先想到的日志传输(log shipper)就是 Logstash。开发者听说过它,但是不太清楚它具体是干什么事情的:
当深入这个话题时,我们才明白集中存储日志通常隐含着很多的事情,Logstash 也不是唯一的日志传输工具(log shipper)
- 从数据源获取数据:文件、UNIX socket、TCP、UDP 等等
- 处理:添加时间戳、解析非结构化数据、根据 IP 添加地理位置信息
- 传输:到目标存储。比如,Elasticsearch 。由于 Elasticsearch 可能会宕机,或正存在性能问题,或网络存在问题,那么传输工具最好就需要有能力提供缓冲以及重试。
本篇博文旨在比较 Logstash 已经它的五种替代方案(Filebeat、Fluentd、rsyslog、syslog-ng 以及 Logagent),这样就可以知道它们各适合于何种场景。
分析
Logstash
Logstash 不是这个列表里最老的传输工具(最老的应该是 syslog-ng ,讽刺的是它也是唯一一个名字里带有 new 的),但 Logstash 绝对可以称得上最有名的。因为它有很多插件:输入、编解码器、过滤器以及输出。基本上,可以获取并丰富任何数据,然后将它们推送到多种目标存储。
优势
Logstash 主要的有点就是它的灵活性,这还主要因为它有很多插件。然后它清楚的文档已经直白的配置格式让它可以再多种场景下应用。这样的良性循环让我们可以在网上找到很多资源,几乎可以处理任何问题。以下是一些例子:
- 5 minute intro
- reindexing data in Elasticsearch
- parsing Elasticsearch logs
- rewriting Elasticsearch slowlogs so you can replay them with JMeter
劣势
Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的。这里有 Logstash 与 rsyslog 性能对比以及Logstash 与 filebeat 的性能对比。它在大数据量的情况下会是个问题。
另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池:
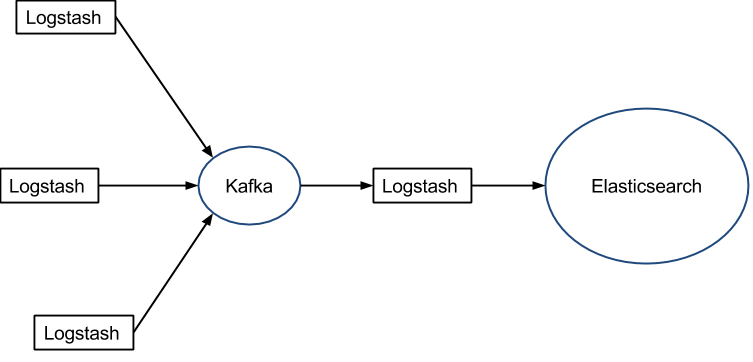
典型应用场景
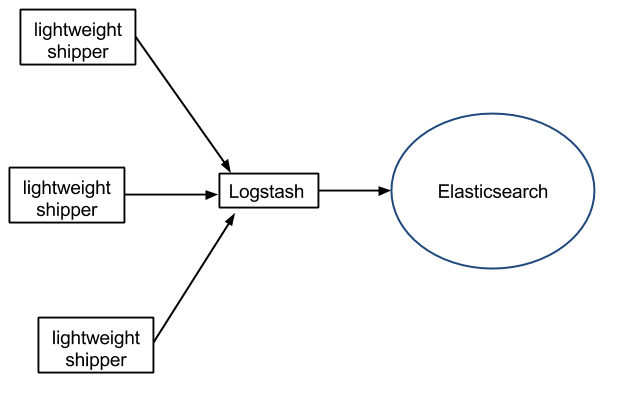
因为 Logstash 自身的灵活性以及网络上丰富的资料,Logstash 适用于原型验证阶段使用,或者解析非常的复杂的时候。在不考虑服务器资源的情况下,如果服务器的性能足够好,我们也可以为每台服务器安装 Logstash 。我们也不需要使用缓冲,因为文件自身就有缓冲的行为,而 Logstash 也会记住上次处理的位置。
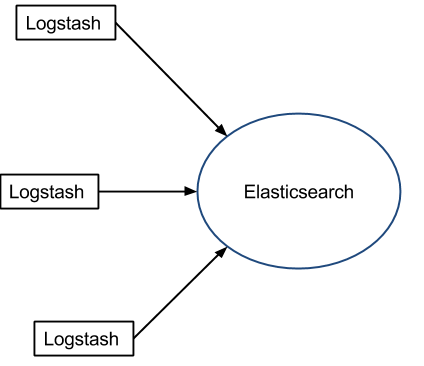
如果服务器性能较差,并不推荐为每个服务器安装 Logstash ,这样就需要一个轻量的日志传输工具,将数据从服务器端经由一个或多个 Logstash 中心服务器传输到 Elasticsearch:
随着日志项目的推进,可能会因为性能或代价的问题,需要调整日志传输的方式(log shipper)。当判断 Logstash 的性能是否足够好时,重要的是对吞吐量的需求有着准确的估计,这也决定了需要为 Logstash 投入多少硬件资源。
Filebeat
作为 Beats 家族的一员,Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点:Filebeat 作为一个轻量级的日志传输工具可以将日志推送到中心 Logstash。
在版本 5.x 中,Elasticsearch 具有解析的能力(像 Logstash 过滤器)— Ingest。这也就意味着可以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存储的事情。也不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移:
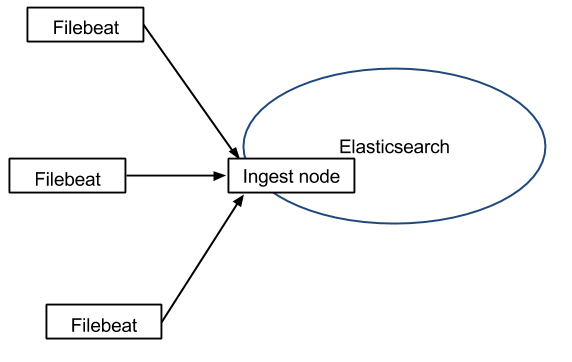
如果需要缓冲(例如,不希望将日志服务器的文件系统填满),可以使用 Redis/Kafka,因为 Filebeat 可以与它们进行通信:
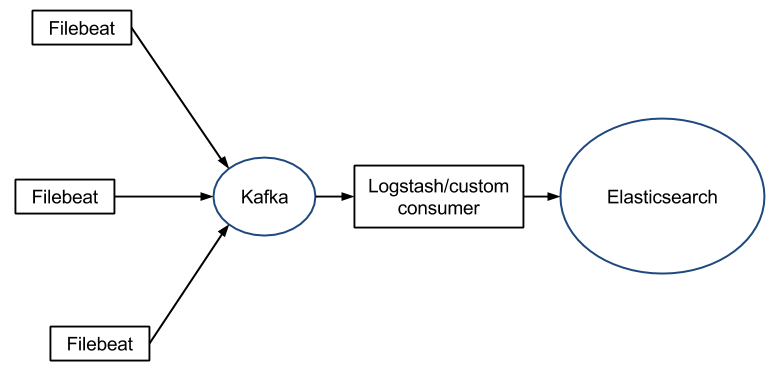
优势
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。
劣势
Filebeat 的应用范围十分有限,所以在某些场景下我们会碰到问题。例如,如果使用 Logstash 作为下游管道,我们同样会遇到性能问题。正因为如此,Filebeat 的范围在扩大。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。
典型应用场景
Filebeat 在解决某些特定的问题时:日志存于文件,我们希望
- 将日志直接传输存储到 Elasticsearch。这仅在我们只是抓去(grep)它们或者日志是存于 JSON 格式(Filebeat 可以解析 JSON)。或者如果打算使用 Elasticsearch 的 Ingest 功能对日志进行解析和丰富。
- 将日志发送到 Kafka/Redis。所以另外一个传输工具(例如,Logstash 或自定义的 Kafka 消费者)可以进一步丰富和转发。这里假设选择的下游传输工具能够满足我们对功能和性能的要求。
Logagent
Logagent 是 Sematext 提供的传输工具,它用来将日志传输到 Logsene(一个基于 SaaS 平台的 Elasticsearch API),因为 Logsene 会暴露 Elasticsearch API,所以 Logagent 可以很容易将数据推送到 Elasticsearch 。
优势
可以获取 /var/log 下的所有信息,解析各种格式(Elasticsearch,Solr,MongoDB,Apache HTTPD等等),它可以掩盖敏感的数据信息,例如,个人验证信息(PII),出生年月日,信用卡号码,等等。它还可以基于 IP 做 GeoIP 丰富地理位置信息(例如,access logs)。同样,它轻量又快速,可以将其置入任何日志块中。在新的 2.0 版本中,它以第三方 node.js 模块化方式增加了支持对输入输出的处理插件。重要的是 Logagent 有本地缓冲,所以不像 Logstash ,在数据传输目的地不可用时会丢失日志。
劣势
尽管 Logagent 有些比较有意思的功能(例如,接收 Heroku 或 CloudFoundry 日志),但是它并没有 Logstash 灵活。
典型应用场景
Logagent 作为一个可以做所有事情的传输工具是值得选择的(提取、解析、缓冲和传输)。
rsyslog
绝大多数 Linux 发布版本默认的 syslog 守护进程,rsyslog 可以做的不仅仅是将日志从 syslog socket 读取并写入 /var/log/messages 。它可以提取文件、解析、缓冲(磁盘和内存)以及将它们传输到多个目的地,包括 Elasticsearch 。可以从此处找到如何处理 Apache 以及系统日志。
优势
rsyslog 是经测试过的最快的传输工具。如果只是将它作为一个简单的 router/shipper 使用,几乎所有的机器都会受带宽的限制,但是它非常擅长处理解析多个规则。它基于语法的模块(mmnormalize)无论规则数目如何增加,它的处理速度始终是线性增长的。这也就意味着,如果当规则在 20-30 条时,如解析 Cisco 日志时,它的性能可以大大超过基于正则式解析的 grok ,达到 100 倍(当然,这也取决于 grok 的实现以及 liblognorm 的版本)。
它同时也是我们能找到的最轻的解析器,当然这也取决于我们配置的缓冲。
劣势
rsyslog 的配置工作需要更大的代价(这里有一些例子),这让两件事情非常困难:
- 文档难以搜索和阅读,特别是那些对术语比较陌生的开发者。
- 5.x 以上的版本格式不太一样(它扩展了 syslogd 的配置格式,同时也仍然支持旧的格式),尽管新的格式可以兼容旧格式,但是新的特性(例如,Elasticsearch 的输出)只在新的配置下才有效,然后旧的插件(例如,Postgres 输出)只在旧格式下支持。
尽管在配置稳定的情况下,rsyslog 是可靠的(它自身也提供多种配置方式,最终都可以获得相同的结果),它还是存在一些 bug 。
典型应用场景
rsyslog 适合那些非常轻的应用(应用,小VM,Docker容器)。如果需要在另一个传输工具(例如,Logstash)中进行处理,可以直接通过 TCP 转发 JSON ,或者连接 Kafka/Redis 缓冲。
rsyslog 还适合我们对性能有着非常严格的要求时,特别是在有多个解析规则时。那么这就值得为之投入更多的时间研究它的配置。
syslog-ng
可以将 syslog-ng 当作 rsyslog 的替代品(尽管历史上它们是两种不同的方式)。它也是一个模块化的 syslog 守护进程,但是它可以做的事情要比 syslog 多。它可以接收磁盘缓冲并将 Elasticsearch HTTP 作为输出。它使用 PatternDB 作为语法解析的基础,作为 Elasticsearch 的传输工具,它是一个不错的选择。
优势
和 rsyslog 一样,作为一个轻量级的传输工具,它的性能也非常好。它曾经比 rsyslog 慢很多,但是 2 年前能达到 570K Logs/s 的性能并不差。并不像 rsyslog ,它有着明确一致的配置格式以及完好的文档。
劣势
Linux 发布版本转向使用 rsyslog 的原因是 syslog-ng 高级版曾经有很多功能在开源版中都存在,但是后来又有所限制。我们这里只关注与开源版本,所有的日志传输工具都是开源的。现在又有所变化,例如磁盘缓冲,曾经是高级版存在的特性,现在开源版也有。但有些特性,例如带有应用层的通知的可靠传输协议(reliable delivery protocol)还没有在开源版本中。
典型应用场景
和 rsyslog 类似,可能将 syslog-ng 部署在资源受限的环境中,但仍希望它能在处理复杂计算时有着良好的性能。如果使用 rsyslog ,它可以输出至 Kafka ,以 Kafka 作为一个中心队列,并以 Logstash 作为一个自定义消费者:
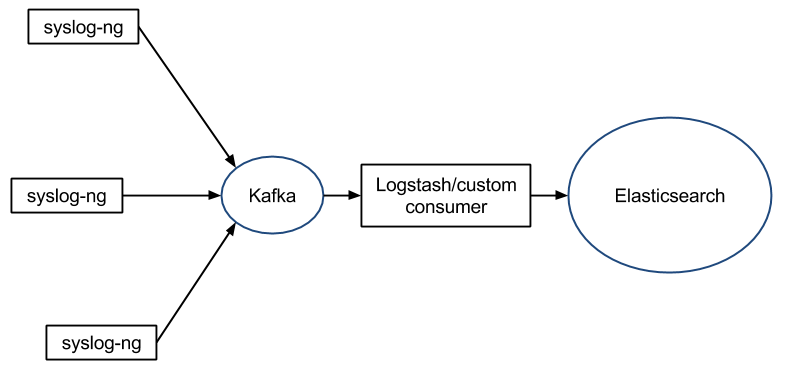
不同的是,syslog-ng 使用起来比 rsyslog 更容易,性能没有 rsyslog 那么极致:例如,它只对输出进行缓冲,所以它所有的计算处理在缓冲之前就完成了,这也意味着它会给日志流带来压力。
Fluentd
Fluentd 创建的初衷主要是尽可能的使用 JSON 作为日志输出,所以传输工具及其下游的传输线不需要猜测子字符串里面各个字段的类型。这样,它为几乎所有的语言都提供库,这也意味着,我们可以将它插入到我们自定义的程序中。
优势
和多数 Logstash 插件一样,Fluentd 插件是用 Ruby 语言开发的非常易于编写维护。所以它数量很多,几乎所有的源和目标存储都有插件(各个插件的成熟度也不太一样)。这也意味这我们可以用 Fluentd 来串联所有的东西。
劣势
因为在多数应用场景下,我们会通过 Fluentd 得到结构化的数据,它的灵活性并不好。但是我们仍然可以通过正则表达式,来解析非结构化的数据。尽管,性能在大多数场景下都很好,但它并不是最好的,和 syslog-ng 一样,它的缓冲只存在与输出端,单线程核心以及 Ruby GIL 实现的插件意味着它大的节点下性能是受限的,不过,它的资源消耗在大多数场景下是可以接受的。对于小的或者嵌入式的设备,可能需要看看 Fluent Bit,它和 Fluentd 的关系与 Filebeat 和 Logstash 之间的关系类似
典型应用场景
Fluentd 在日志的数据源和目标存储各种各样时非常合适,因为它有很多插件。而且,如果大多数数据源都是自定义的应用,所以可以发现用 fluentd 的库要比将日志库与其他传输工具结合起来要容易很多。特别是在我们的应用是多种语言编写的时候,即我们使用了多种日志库,日志的行为也不太一样。
结论
工具的选择由使用场景决定。
Logstash 性能及其替代方案的更多相关文章
- ELK 性能(1) — Logstash 性能及其替代方案
ELK 性能(1) - Logstash 性能及其替代方案 介绍 当谈及集中日志到 Elasticsearch 时,首先想到的日志传输(log shipper)就是 Logstash.开发者听说过它, ...
- 【日志处理】logstash性能优化配置
2W条数据用时4秒完成,每秒5000条左右,昨天是同时写入到文件和标准输出,看起来是output的问题,这块性能应当可以满足性能要求了 后继我会继续把结果输出到tcp,kafka来测试经过grok后的 ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- 之前做web性能优化的一些个人心得
一个web项目后期的维护主要在于性能方面.数据吞吐量一旦增大各种bug都出来了.那些通过硬件<数据库分表,数据库主从分离,读写分离>等的一些手段此处就不多说了.本文主要在编码方面做一个性能 ...
- 关于优化性能<主要是速度方面>的个人心得 【转】
一个web项目后期的维护主要在于性能方面.数据吞吐量一旦增大各种bug都出来了.那些通过硬件<数据库分表,数据库主从分离,读写分离>等的一些手段此处就不多说了.本文主要在编码方面做一个性能 ...
- ELK(elasticsearch+kibana+logstash)搜索引擎(一): 环境搭建
1.ELK简介 这里简单介绍一下elk架构中的各个组件,关于elk的详细介绍的请自行百度 Elasticsearch是个开源分布式搜索引擎,是整个ELK架构的核心 Logstash可以对数据进行收集. ...
- ELK 性能(4) — 大规模 Elasticsearch 集群性能的最佳实践
ELK 性能(4) - 大规模 Elasticsearch 集群性能的最佳实践 介绍 集群规模 集群数:6 整体集群规模: 300 Elasticsearch 实例 141 物理服务器 4200 CP ...
- 微服务日志监控与查询logstash + kafka + elasticsearch
使用 logstash + kafka + elasticsearch 实现日志监控 https://blog.csdn.net/github_39939645/article/details/788 ...
- ELK学习实验011:Logstash工作原理
Logstash事件处理管道包括三个阶段:输入→过滤器→输出.输入会生成事件,过滤器会对其进行修改,输出会将它们发送到其他地方.输入和输出支持编解码器,使您可以在数据进入或退出管道时对其进行编码或解码 ...
随机推荐
- sax解析xml文件,封装到对象中
创建User.java类 public class User { private String id; private String name; private String age; private ...
- C++——堆、栈、静态存储区
栈 堆 静态存储区 生命周期 函数结束即释放 new,malloc开辟,delete,free释放 释放前,一直存在 最长,程序退出才释放 程序.局部变量 new,malloc申请的空间,用于 ...
- iOS判断字母、数字串
以下为NSString类的扩展方法,分别是判断字符串是否只是包含字母.是否只包含数字.是否只包含字母和数字: //字母 - (BOOL)cdm_isOnlyLetters { NSCharacterS ...
- Opencv3 图片膨胀与腐蚀
#include <iostream>#include <opencv2/opencv.hpp> using namespace std;using namespace cv; ...
- 3-为什么很多 对 1e9+7(100000007)取模
首先有很多题目的答案是很大的,然而出题人的本意也不是让选手写高精度或者Java,所以势必要让答案落在整型的范围内.那么怎么做到这一点呢,对一个很大的质数取模即可(自行思考为什么不是小数).那么如果您学 ...
- Qt5.7学习
一 Qt简介(Build your world with Qt) 二 Qt5.7.0的安装 三 Qt系统构造库及常用类 四 信号(signal)与槽(slot)通信机制 五 QtDesigner开发工 ...
- REDIS与MEMCACHED的区别(转)
出处:http://www.blogjava.net/paulwong/archive/2013/09/06/403746.html 如果简单地比较Redis与Memcached的区别,大多数都会得到 ...
- Android 修改 TextView 的全局默认颜色。
如果你的应用中大多数TextView的颜色是红色, 或者其他颜色, 你是为每一个TextView都设置一次颜色, 还是有其他更好的办法, 这里教你怎么修改TextView的默认颜色. 当然我们Text ...
- java中jar打包的方法
jar 应用 先打开命令提示符(win2000或在运行筐里执行cmd命令,win98为DOS提示符),输入jar -help,然后回车(如果你盘上已经有了jdk1.1或以上版本),看到什么:用法:ja ...
- “undefined reference to JNI_GetCreatedJavaVM”和“File format not recognized”错误原因分析
"undefined reference to JNI_GetCreatedJavaVM"和"File format not recognized"错误原因分析 ...