ES 内存深度解析
注: 本文主要针对ES 2.x。
“该给ES分配多少内存?”
“JVM参数如何优化?“
“为何我的Heap占用这么高?”
“为何经常有某个field的数据量超出内存限制的异常?“
“为何感觉上没多少数据,也会经常Out Of Memory?”
以上问题,显然没有一个统一的数学公式能够给出答案。
和数据库类似,ES对于内存的消耗,和很多因素相关,诸如数据总量、mapping设置、查询方式、查询频度等等。默认的设置虽开箱即用,但不能适用每一种使用场景。作为ES的开发、运维人员,如果不了解ES对内存使用的一些基本原理,就很难针对特有的应用场景,有效的测试、规划和管理集群,从而踩到各种坑,被各种问题挫败。
要理解ES如何使用内存,先要理解下面两个基本事实:
1. ES是JAVA应用
2. 底层存储引擎是基于Lucene的
看似很普通是吗?但其实没多少人真正理解这意味着什么。
首先,作为一个JAVA应用,就脱离不开JVM和GC。很多人上手ES的时候,对GC一点概念都没有就去网上抄各种JVM“优化”参数,却仍然被heap不够用,内存溢出这样的问题搞得焦头烂额。了解JVM
GC的概念和基本工作机制是很有必要的,本文不在此做过多探讨,读者可以自行Google相关资料进行学习。如何知道ES heap是否真的有压力了?
推荐阅读这篇博客:Understanding Memory Pressure Indicator。
即使对于JVM GC机制不够熟悉,头脑里还是需要有这么一个基本概念:
应用层面生成大量长生命周期的对象,是给heap造成压力的主要原因,例如读取一大片数据在内存中进行排序,或者在heap内部建cache缓存大量数据。如果GC释放的空间有限,而应用层面持续大量申请新对象,GC频度就开始上升,同时会消耗掉很多CPU时间。严重时可能恶性循环,导致整个集群停工。因此在使用ES的过程中,要知道哪些设置和操作容易造成以上问题,有针对性的予以规避。
其次,Lucene的倒排索引(Inverted Index)是先在内存里生成,然后定期以段文件(segment
file)的形式刷到磁盘的。每个段实际就是一个完整的倒排索引,并且一旦写到磁盘上就不会做修改。
API层面的文档更新和删除实际上是增量写入的一种特殊文档,会保存在新的段里。不变的段文件易于被操作系统cache,热数据几乎等效于内存访问。
基于以上2个基本事实,我们不难理解,为何官方建议的heap size不要超过系统可用内存的一半。heap以外的内存并不会被浪费,操作系统会很开心的利用他们来cache被用读取过的段文件。
Heap分配多少合适?遵从官方建议就没错。
不要超过系统可用内存的一半,并且不要超过32GB。JVM参数呢?对于初级用户来说,并不需要做特别调整,仍然遵从官方的建议,将xms和xmx设置成和heap一样大小,避免动态分配heap
size就好了。虽然有针对性的调整JVM参数可以带来些许GC效率的提升,当有一些“坏”用例的时候,这些调整并不会有什么魔法效果帮你减轻heap压力,甚至可能让问题更糟糕。
那么,ES的heap是如何被瓜分掉的? 说几个我知道的内存消耗大户并分别做解读:
1. segment memory
2. filter cache
3. field data cache
4. bulk queue
5. indexing buffer
6. state buffer
7. 超大搜索聚合结果集的fetch
8. 对高cardinality字段做terms aggregation
Segment Memory
Segment不是file吗?segment
memory又是什么?前面提到过,一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term
Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。
由于词典的size会很大,全部装载到heap里不现实,因此Lucene为词典做了一层前缀索引(Term
Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。
这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
下面是词典索引和词典主存储之间的一个对应关系图:
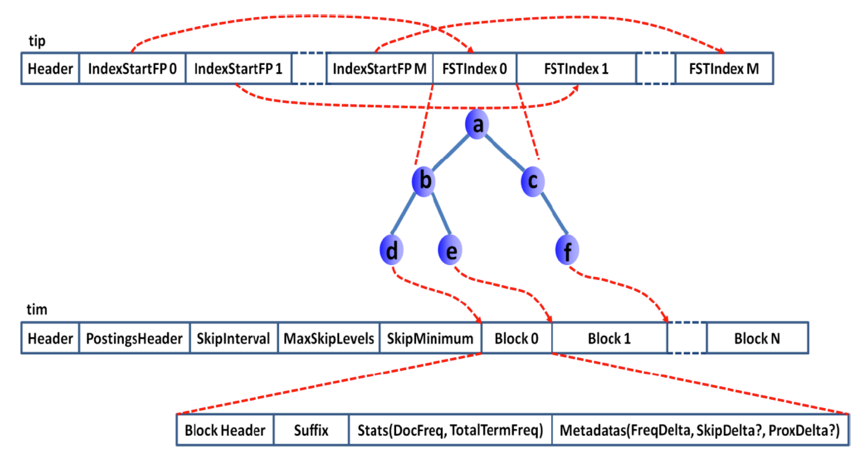
Lucene file的完整数据结构参见Apache Lucene - Index File Formats
说了这么多,要传达的一个意思就是,ES的data
node存储数据并非只是耗费磁盘空间的,为了加速数据的访问,每个segment都有会一些索引数据驻留在heap里。因此segment越多,瓜分掉的heap也越多,并且这部分heap是无法被GC掉的!
理解这点对于监控和管理集群容量很重要,当一个node的segment memory占用过多的时候,就需要考虑删除、归档数据,或者扩容了。
怎么知道segment memory占用情况呢? CAT API可以给出答案。
1. 查看一个索引所有segment的memory占用情况:
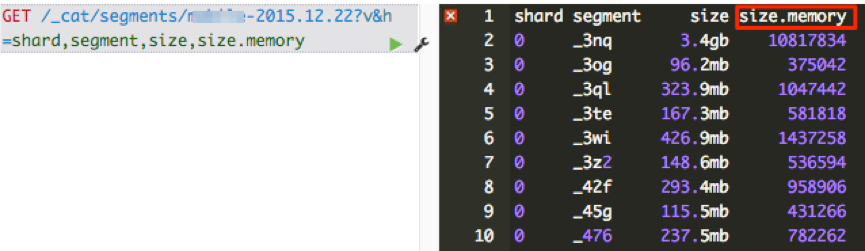
2. 查看一个node上所有segment占用的memory总和:
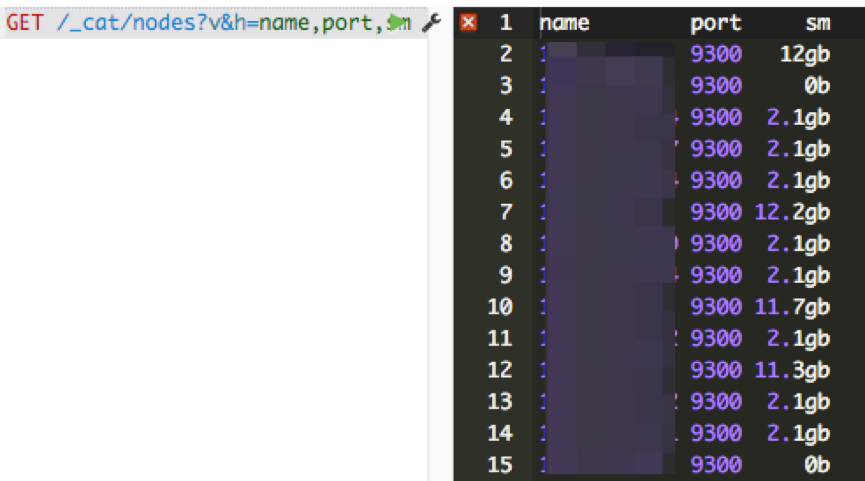
那么有哪些途径减少data node上的segment memory占用呢? 总结起来有三种方法:
1. 删除不用的索引
2. 关闭索引 (文件仍然存在于磁盘,只是释放掉内存)。需要的时候可以重新打开。
3. 定期对不再更新的索引做optimize (ES2.0以后更改为force merge api)。这Optimze的实质是对segment file强制做合并,可以节省大量的segment memory。
Filter Cache (5.x里叫做Request cache)
Filter cache是用来缓存使用过的filter的结果集的,需要注意的是这个缓存也是常驻heap,在被evict掉之前,是无法被GC的。我的经验是默认的10% heap设置工作得够好了,如果实际使用中heap没什么压力的情况下,才考虑加大这个设置。
Field Data cache
在有大量排序、数据聚合的应用场景,可以说field data cache是性能和稳定性的杀手。
对搜索结果做排序或者聚合操作,需要将倒排索引里的数据进行解析,按列构造成docid->value的形式才能够做后续快速计算。
对于数据量很大的索引,这个构造过程会非常耗费时间,因此ES
2.0以前的版本会将构造好的数据缓存起来,提升性能。但是由于heap空间有限,当遇到用户对海量数据做计算的时候,就很容易导致heap吃紧,集群频繁GC,根本无法完成计算过程。
ES2.0以后,正式默认启用Doc Values特性(1.x需要手动更改mapping开启),将field data在indexing
time构建在磁盘上,经过一系列优化,可以达到比之前采用field data cache机制更好的性能。因此需要限制对field data
cache的使用,最好是完全不用,可以极大释放heap压力。
需要注意的是,很多同学已经升级到ES2.0,或者1.0里已经设置mapping启用了doc values,在kibana里仍然会遇到问题。
这里一个陷阱就在于kibana的table panel可以对所有字段排序。
设想如果有一个字段是analyzed过的,而用户去点击对应字段的排序表头是什么后果? 一来排序的结果并不是用户想要的,排序的对象实际是词典;
二来analyzed过的字段无法利用doc values,需要装载到field data
cache,数据量很大的情况下可能集群就在忙着GC或者根本出不来结果。
Bulk Queue
一般来说,Bulk queue不会消耗很多的heap,但是见过一些用户为了提高bulk的速度,客户端设置了很大的并发量,并且将bulk
Queue设置到不可思议的大,比如好几千。 Bulk Queue是做什么用的?当所有的bulk thread都在忙,无法响应新的bulk
request的时候,将request在内存里排列起来,然后慢慢清掉。
这在应对短暂的请求爆发的时候有用,但是如果集群本身索引速度一直跟不上,设置的好几千的queue都满了会是什么状况呢?
取决于一个bulk的数据量大小,乘上queue的大小,heap很有可能就不够用,内存溢出了。一般来说官方默认的thread
pool设置已经能很好的工作了,建议不要随意去“调优”相关的设置,很多时候都是适得其反的效果。
Indexing Buffer
Indexing Buffer是用来缓存新数据,当其满了或者refresh/flush interval到了,就会以segment
file的形式写入到磁盘。 这个参数的默认值是10% heap size。根据经验,这个默认值也能够很好的工作,应对很大的索引吞吐量。
但有些用户认为这个buffer越大吞吐量越高,因此见过有用户将其设置为40%的。到了极端的情况,写入速度很高的时候,40%都被占用,导致OOM。
Cluster State Buffer
ES被设计成每个node都可以响应用户的api请求,因此每个node的内存里都包含有一份集群状态的拷贝。这个cluster
state包含诸如集群有多少个node,多少个index,每个index的mapping是什么?有少shard,每个shard的分配情况等等
(ES有各类stats api获取这类数据)。
在一个规模很大的集群,这个状态信息可能会非常大的,耗用的内存空间就不可忽视了。并且在ES2.0之前的版本,state的更新是由master
node做完以后全量散播到其他结点的。 频繁的状态更新就可以给heap带来很大的压力。 在超大规模集群的情况下,可以考虑分集群并通过tribe
node连接做到对用户api的透明,这样可以保证每个集群里的state信息不会膨胀得过大。
超大搜索聚合结果集的fetch
ES是分布式搜索引擎,搜索和聚合计算除了在各个data
node并行计算以外,还需要将结果返回给汇总节点进行汇总和排序后再返回。无论是搜索,还是聚合,如果返回结果的size设置过大,都会给heap造成很大的压力,特别是数据汇聚节点。超大的size多数情况下都是用户用例不对,比如本来是想计算cardinality,却用了terms
aggregation + size:0这样的方式; 对大结果集做深度分页;一次性拉取全量数据等等。
对高cardinality字段做terms aggregation
所谓高cardinality,就是该字段的唯一值比较多。 比如client ip,可能存在上千万甚至上亿的不同值。 对这种类型的字段做terms
aggregation时,需要在内存里生成海量的分桶,内存需求会非常高。如果内部再嵌套有其他聚合,情况会更糟糕。
在做日志聚合分析时,一个典型的可以引起性能问题的场景,就是对带有参数的url字段做terms aggregation。
对于访问量大的网站,带有参数的url字段cardinality可能会到数亿,做一次terms
aggregation内存开销巨大,然而对带有参数的url字段做聚合通常没有什么意义。
对于这类问题,可以额外索引一个url_stem字段,这个字段索引剥离掉参数部分的url。可以极大降低内存消耗,提高聚合速度。
小结:
- 倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
- 各类缓存,field
cache, filter cache, indexing cache, bulk
queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear
cache等“自欺欺人”的方式来释放内存。 - 避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
- cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
- 想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
- 根据监控数据理解内存需求,合理配置各类circuit breaker,将内存溢出风险降低到最低
ES 内存深度解析的更多相关文章
- java 内存深度解析
java 中的包括以下几大种的内存区域:1.寄存器 2.stack(栈) 3.heap(堆) 4.数据段 5.常量池 那么相应的内存区域中又存放什么东西(主要介绍 stack heap)? 栈: ...
- java内存分配和String类型的深度解析
[尊重原创文章出自:http://my.oschina.net/xiaohui249/blog/170013] 摘要 从整体上介绍java内存的概念.构成以及分配机制,在此基础上深度解析java中的S ...
- 【转】java内存分配和String类型的深度解析
一.引题 在java语言的所有数据类型中,String类型是比较特殊的一种类型,同时也是面试的时候经常被问到的一个知识点,本文结合java内存分配深度分析关于String的许多令人迷惑的问题.下面是本 ...
- Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
前言 如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的.最着名的例子是 Apache Hadoop,还有较新的框架,如 Apache Spark.Apach ...
- Flink Connector 深度解析
作者介绍:董亭亭,快手大数据架构实时计算引擎团队负责人.目前负责 Flink 引擎在快手内的研发.应用以及周边子系统建设.2013 年毕业于大连理工大学,曾就职于奇虎 360.58 集团.主要研究领域 ...
- 第37课 深度解析QMap与QHash
1. QMap深度解析 (1)QMap是一个以升序键顺序存储键值对的数据结构 ①QMap原型为 class QMap<K, T>模板 ②QMap中的键值对根据Key进行了排序 ③QMap中 ...
- Kafka深度解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- Unity加载模块深度解析(Shader)
作者:张鑫链接:https://zhuanlan.zhihu.com/p/21949663来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 接上一篇 加载模块深度解析(二 ...
- Unity加载模块深度解析(网格篇)
在上一篇 加载模块深度解析(一)中,我们重点讨论了纹理资源的加载性能.这次,我们再来为你揭开其他主流资源的加载效率. 这是侑虎科技第53篇原创文章,欢迎转发分享,未经作者授权请勿转载.同时如果您有任何 ...
随机推荐
- mysql压缩表空间
REPAIR TABLE `table_name` 修复表 OPTIMIZE TABLE `table_name` 优化表 OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] ...
- javascript slice array to num subarray
var data = ['法国','澳大利亚','智利','新西兰','西班牙','加拿大','阿根廷','美国','0','国产','波多黎各','英国','比利时','德国','意大利','意大利 ...
- 第6章Zabbix分布式监控
Zabbix是一个分布式的监控系统.分布式监控适合跨机房.跨地域的网络监控.从多个Proxy收集数据,而每个Proxy可以采集多个设备的数据,从而轻松地构建分布式监控系统. ZabbixProxy可以 ...
- [Z]QPS、PV和需要部署机器数量计算公式
QPS = req/sec = 请求数/秒 [QPS计算PV和机器的方式] QPS统计方式 [一般使用 http_load 进行统计]QPS = 总请求数 / ( 进程总数 * 请求时间 )QPS ...
- 摆脱Login控件,自己定义登录操作
protected void ImageButton1_Click(object sender, ImageClickEventArgs e) { //在登录过程中,程序自动使用login.aspx进 ...
- rails 网站跨域
7down voteaccepted gem install rack-cors Or in your Gemfile: gem 'rack-cors', :require => 'rack/c ...
- 双 MySQL 启动、停止脚本
5.5 启动 #!/bin/bash # author: Wang Xiaoqiang # func: Start MySQL 5.5 pid=`netstat -lnpt | awk -F '[ / ...
- README.md的编写
1.编辑README文件 大标题(一级标题):在文本下面加等于号,那么上方的文字就变成了大标题,等于号的个数无限制,但一定要大于0 大标题 ==== 中标题(二级标题):在文本下面加下划线,那么上方的 ...
- MonoDevelop Assembly Browser
[MonoDevelop Assembly Browser] View -> Assembly Browser,通过此窗口可以查看Dll的反编译后的代码. 还有几款免费的替代产品可以使用, 虽然 ...
- Unity 导出NavMesh (可行走区域判定) 数据给服务器使用
cp790621656 博客专家 Unity 导出NavMesh (可行走区域判定) 数据给服务器使用 发表于2016/9/26 18:15:11 1089人阅读 分类: Unity MMO 这个 ...