【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
阅读目录
概要
- 独立(或本地)模式 : 无需运行任何守护进程,所有程序都在同一个JVM上运行。在此模式下测试和调试MapReduce程序很方便,因此该模式在开发阶段比较合适。
- 伪分布模式: Hadoop守护进程运行在本地机器上,模拟一个小规模的集群;
- 全分布模式: Hadoop守护进程运行在一个集群上。
- 操作系统 :Centos 6.8
- java版本 :jdk1.6.0_45
- hadoop版本:hadoop-1.2.1
- java文件 :jdk-6u45-linux-x64.bin
- hapoop文件:hadoop-1.2.1.tar.gz
- 安装Java1.6;
- 设置ssh无密码登录;
- 安装hadoop1.2.1,并修改配置文件;
- Hadoop启动;
- 测试hadoop;
二、设置ssh无密码登录
- 在伪分布模式下工作必须启动守护进程,而启动守护进程的前提是已经安装SSH。
- Hadoop并不严格区分伪分布模式和全分布模式,它只是在集群内的(多台)主机(由slaves文件定义)上启动守护进程:SSH到各个主机并启动一个守护进程。
- 伪分布模式是全分布模式的一个特例。
- 在伪分布模式下,(单)主机就是本地计算机(localhost),因此需要确保用户能够SSH到本地机器,并且可以不输入密码。
rpm -qa| grep ssh //检查是否安装service sshd status //查看ssh运行状态yum install ssh //安装sshchkconfig --list sshd //查看是否开机启动chkconfig sshd on //设置开机启动
groupadd hadoopuseradd -g hadoop -d /home/hadoop hadooppasswd hadoop
3. 设置ssh无密码登录
su - hadoopssh-keygen -t rsa //在~/.ssh/目录下生成id_rsa私钥和id_rsa.pub公钥cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys
su - hadoopssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys
ssh localhost //首次时会让输入yes/no,但是不需要密码
三、Hadoop的安装(在Hadoop用户下)
su - hadoopmkdir ~/hadoop-env //将hadoop-1.2.1.tar.gz拷贝到该文件夹下cd hadoop-env/tar zxvf hadoop-1.2.1.tar.gz //安装Hadoop
su -vi /etc/profile
# set hadoopexport HADOOP_HOME=/home/hadoop/hadoop-env/hadoop-1.2.1export PATH=$HADOOP_HOME/bin:$PATH
source /etc/profileexit //退回到Hadoop用户
四、配置Hadoop相关配置文件
- hadoop-env.sh;
- core-site.xml:用于配置通用属性;
- hdfs-site.xml:用于配置HDFS属性;
- mapred-site.xml:用于配置MapReduce属性;
- masters和slaves文件;
- /etc/hosts;
- core-default.html
- hdfs-default.html
- mapred-default.html
下面介绍不同模式的关键配置属性:
| 组件名称 | 属性名称 | 独立模式 | 伪分布模式 | 全分布模式 |
| Common | fs.default.name | file:///(默认) | hdfs://localhost/ |
hdfs://namenode/ |
| HDFS | dfs.replication | N/A | 1 | 3(默认) |
| MapReduce 1 | mapred.job.tracker | local | localhost:8021 | jobtracker:8021 |
| YARN(MapReduce 2) | yarn.resource.manager.address | N/A |
localhost:8032 |
resourcemanager:8032 |
cd /home/hadoop/hadoop-env/hadoop-1.2.1/conf/cp hadoop-env.sh hadoop-env.sh.origvi hadoop-env.sh
#set java environmentexport JAVA_HOME=/usr/program/jdk1.6.0_45export HADOOP_HOME_WARN_SUPPRESS=true
cd /home/hadoop/hadoop-envmkdir hadooptmpchmod 777 -R /home/hadoop/hadoop-env/hadooptmp/ (以root用户执行)cp core-site.xml core-site.xml.origvi core-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000/</value> 注:9000后面的“/”不能少</property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-env/hadooptmp</value></property></configuration>
cp hdfs-site.xml hdfs-site.xml.origvi hdfs-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
cp mapred-site.xml mapred-site.xml.origvi mapred-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>mapred.job.tracker</name><value>localhost:9001</value></property></configuration>
cd /home/hadoop/hadoop-env/hadoop-1.2.1/confcp masters masters.origcp slaves slaves.origvi mastersvi slaves
localhost
cp /etc/hosts /etc/hosts.origvi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6127.0.0.1 master127.0.0.1 slave
五、Hadoop启动
- 在使用Hadoop前必须格式化生成一个全新的HDFS安装。
- 该过程创建一个空文件系统,仅包含存储目录和namenode持久化数据结构的初始版本。由于namenode管理文件系统的元数据,并且datanode可以动态的加入或离开集群,因此这个格式化过程不针对datanode。
- 同理,文件系统的规模也无从谈起,集群中datanode的数量将决定文件系统的规模。
- datanode可以在文件系统格式化很久之后按需增加。
su - hadoopcd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/hadoop namenode -format //nodename和-format中间有空格
- hadoop.tmp.dir/dfs/name目录;
su -chmod -R 777 /home/hadoop/hadoop-env/hadoop-1.2.1/libexec/../logs/service iptables stop //关闭防火墙
su - hadoopcd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/./start-all.sh
- hadoop.tmp.dir/dfs/data: 存放datanode上的数据块数据;
- hadoop.tmp.dir/dfs/namesecondary :是namenode的一个备份;
- hadoop.tmp.dir/mapred/local目录;
jps
- start-dfs.sh
- start-mapred.sh
- namenode;
- datanode;
- secondarynamenode;
- jobtracker;
- tasktracker;
11761 SecondaryNameNode //是namenode的一个备份12097 Jps11637 DataNode11524 NameNode11862 JobTracker11981 TaskTracker
- secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
- 启动之后,会在$hadoop.tmp.dir/dfs目录下生成data目录,这里面存放的是datanode上的数据块数据;因为笔者用的是单机,所以name和 data都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
- 在Linux下关闭防火墙:使用service iptables stop命令;关闭hadoop:stop-all.sh
- 再次对namenode进行格式化:/home/hadoop/hadoop-env/hadoop-1.2.1/bin目录下执行hadoop namenode -format命令;
- 对服务器进行重启;
- 查看datanode或是namenode对应的日志文件,日志文件保存在/home/hadoop/hadoop-env/hadoop-1.2.1/logs目录下;
- 再次在/bin目录下用start-all.sh命令启动所有进程,通过以上的几个方法应该能解决进程启动不完全的问题了;
cd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/hadoop dfsadmin -report
- Namenode:localhost:50070
- JobTracker:localhost:50030
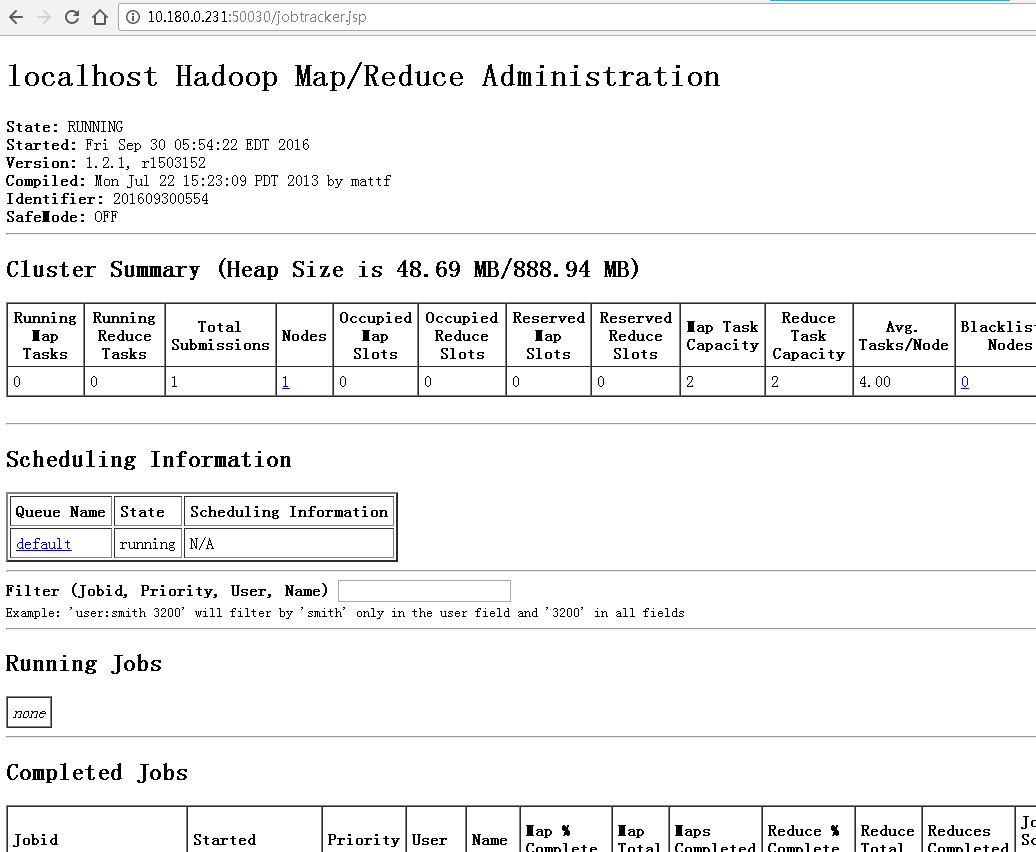
下面是查看的结果:
- localhost:50070(或者 ip:50070查重,如:10.180.0.231::50070)
- 查看namenode

- localhost:50030(或者 ip:50030查重)
- 查看jobtracker启动情况
六、Hadoop环境测试
/home/hadoop/hadoop-env/hadoop-1.2.1mkdir testcd testvi file01 (输入数个单词)vi file02 (输入数个单词)
hadoop fs -mkdir input
hadoop fs -ls
drwxr-xr-x - hadoop supergroup 0 2016-09-30 06:30 /user/hadoop/input
hadoop dfsadmin -safemode leave
hadoop dfsadmin -safemode enter/leave/get/wait
hadoop fs -put /home/hadoop/hadoop-env/hadoop-1.2.1/test/* input
hadoop jar /home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar wordcount input output
- hadoop jar:执行“jar”命令
- /home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar:wordcount所在的jar包
- wordcount:程序主函数名
- input output:输入输出文件夹
hadoop fs -ls
drwxr-xr-x - hadoop supergroup 0 2016-09-30 06:53 /user/hadoop/inputdrwxr-xr-x - hadoop supergroup 0 2016-09-30 06:56 /user/hadoop/output
hadoop dfs -cat output/*
......Summary 1The 1This 2Trap 1at 4by 1client 1counts 1......
cd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/./stop-all.sh
七、参考链接
【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式的更多相关文章
- Hadoop运行模式:本地模式、伪分布模式、完全分布模式
1.本地模式:默认模式 - 不对配置文件进行修改. - 使用本地文件系统,而不是分布式文件系统. - Hadoop不会启动NameNode.DataNode.ResourceManager.NodeM ...
- 【Hadoop】Hadoop的安装,本地模式、伪分布模式的配置
Download hadoop-2.7.7.tar.gz 下载稳定版本的hadoop-2.7.7.tar.gz(我用的2.6.0,但是官网只能下载2.7.7的了) Required Software ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- linux运维、架构之路-Hadoop完全分布式集群搭建
一.介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件 ...
- 进阶2:Hadoop 环境搭建: hadoop3.1.1 jdk1.8 在centos6.5上的伪分布式安装
参考文章: https://blog.csdn.net/qq_38038143/article/details/82779016 https://blog.csdn.net/m0_37461645/a ...
- Hadoop环境搭建 (伪分布式搭建)
一,Hadoop版本下载 建议下载:Hadoop2.5.0 (虽然是老版本,但是在企业级别中运用非常稳定,新版本虽然添加了些小功能但是版本稳定性有带与考核) 1.下载地址: hadoop.apache ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
随机推荐
- linux定时
linux怎样启动定时任务 crontab -e进入以后的,定时任务写入 */1 * * * * /usr/bin/python /root/lianxi/time_1.py ,每一分钟定时执行tim ...
- Linux 常用命令笔记
Linux 常用命令笔记 1. locate locate:用来定位文件的位置,如:locate a.txt 但是这个命令有延迟,也就是新建的文件不一定能搜索到,如果非要找到新建的文件可以使用 upd ...
- JS基础知识(数组)
1,数组 var colors = new Array(); var colors = new Array(20); var colors = new Array(“red”, “blue”, “gr ...
- 使用jQuery设置disabled属性与移除disabled属性
Readonly只针对input和textarea有效,而disabled对于所有的表单元素都有效,下面为大家介绍下使用jQuery设置disabled属性 表单中readOnly和disable ...
- nagios安装配置
http://www.codeweblog.com/nagios%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE/ 上线的服务器有时会被人攻击,导致服务不可用,今天安装配置了 ...
- 用 GitHub 来部署静态网页 ꒰・◡・๑꒱
http://segmentfault.com/a/1190000002765287 在尝试过用 GitHub 部署静态 HTML 网页后,觉得其实挺容易的,这里简单说说如何用 GitHub 来完成部 ...
- ios多语言设置,操作
多语言在应用程序中一般有两种做法:一.程序中提供给用户自己选择的机会: NSArray *languages = [NSLocale preferredLanguages]; NSString *cu ...
- 《笨办法学Python》
习题一 第一个程序 print "Hello World!" print "Hello Evilxr" print "I like typing th ...
- NetStatusEvent info对象的状态或错误情况的属性
代码属性 级别属性 意义 "NetStream.Buffer.Empty" "status" 数据的接收速度不足以填充缓冲区.数据流将在缓冲区重新填充前中 ...
- Twitter 登录和分享
继上面一片介绍了FaceBook的登录和分享,现在再来实现Twitter的登录和分享. 1.首先要说明的是,我没找到官方提供的SDK,查阅很多文章都提到了一个帮助实现的包Twitter4j.jar ...