数据结构-二叉树(Binary Tree)
1、二叉树(Binary Tree)
是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根节点和两棵互不相交的,分别称为根节点的左子树和右子树的二叉树组成。
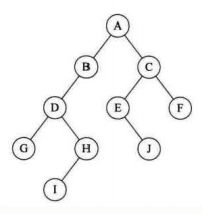
2、特数二叉树
1)斜二叉树
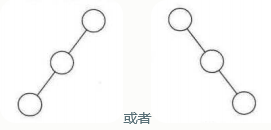
所有的结点都只有左子树的二叉树叫做左斜树
所有的结点都只有右子树的二叉树叫做右斜树
相当于链表,所以线性结构可以理解为是树的一种极其特殊的表现形式
2)满二叉树(完美二叉树)

所有分支结点都存在左子树和右子树。
所有叶子结点都在同一层
3)完全二叉树

对树按照上->下,左->右,编号为i的与满二叉树中为i的位置相同。
3、二叉树的重要性质
性质一:第i层最大结点数位2^(i-1)个,(i>=1)
性质二:深度为k的二叉树至多有2^k-1个结点
性质三:叶结点n0与度为2的结点n2的个数关系n0=n2+1
性质四:具有n个结点的完全二叉树的深度为[log2n]+1
性质五:对一棵有n个结点的完全二叉树,从第一层到最大层,对任一结点i(1=<i<=n)有:
注意:下标是从1开始的。
1.非根节点的父节点序号是[i/2]
2.结点(序号i)的左孩子为2i,若2i>n没有左孩子
3.结点(序号i)的右孩子为2i+1,若2i+1>n没有右孩子

但一般数组下标是从0开始的:
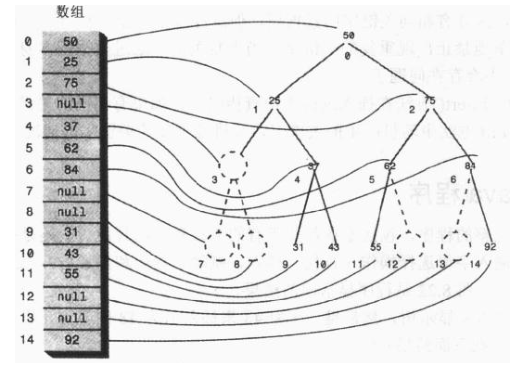
树中的每个位置,无论是否存在节点,都对应于数组中的一个位置,树中没有节点的在数组中用0或者null表示。
假设节点的索引值为index,那么节点的左子节点是 2*index+1,节点的右子节点是 2*index+2,它的父节点是 (index-1)/2。
4、二叉树的顺序存储结构
一般树很难用数组存储,但完全二叉树可以,(从上->下,从左->右,层序遍历)。同时可以利用完全二叉树的性质5,快速获得结点的双亲与孩子位置。
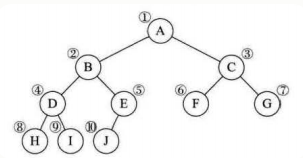

二叉树的顺序存储结构就是用一维数组存储二叉树中的结点,并且结点的存储位置,可以使用性质五来提现结点之间关系。这就是完全二叉树的优越性。
补充:对于一般二叉树也可以使用顺序存储(不过需要对空结点进行补全为^,变为一棵完全二叉树先)
我们需要结合数的结构来考虑,一棵普通的二叉树能否使用该方法。
如果是接近完全二叉树的二叉树,我们可以补全,
但是对于一棵类似于右斜二叉树,则完全没有必要,会大量浪费空间
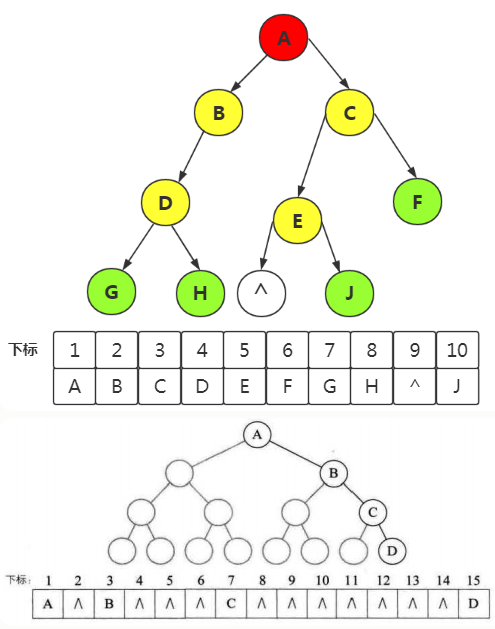
5、二叉链表

//二叉树的二叉链表结点结构定义
typedef struct BiTNode //结点结构
{
TElemType data; //结点数据
struct BiTNode *lchild, *rchild; //左右孩子指针
}BiTNode,*BiTree;
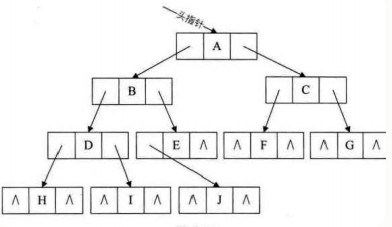
6、二叉树的遍历(递归方式)
1)前序遍历(根左右,从根节点开始遍历)

void PreOrderTraversal(BinTree BT)
{
if (BT)
{
printf("%d", BT->data);
PreOrderTraversal(BT->lchild);
PreOrderTraversal(BT->rchild);
} }
2)中序遍历(左根右,注意从最左侧叶子节点开始遍历)

void InOrderTraversal(BinTree BT)
{
if (BT)
{
InOrderTraversal(BT->lchild);
printf("%d", BT->data);
InOrderTraversal(BT->rchild);
}
}
3)后序遍历(左右根,依然从最左侧叶子节点开始)

void PostOrderTraversal(BinTree BT)
{
if (BT)
{
PostOrderTraversal(BT->lchild);
PostOrderTraversal(BT->rchild);
printf("%d", BT->data);
}
}
4)层序遍历(顺序存储)利用队列。
import java.util.*;
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
Queue<TreeNode> queue=new LinkedList<>();
ArrayList<Integer> list=new ArrayList<Integer>();
if(root==null)
return list;
queue.offer(root);
while(!queue.isEmpty())
{
int size=queue.size();
for(int i=0;i<size;i++)
{
TreeNode node=queue.poll();
list.add(node.val);
if(node.left!=null) queue.offer(node.left);
if(node.right!=null) queue.offer(node.right);
}
}
return list;
}
}
二叉树前、中、后三种遍历的非递归实现方式:

前序和后序遍历:前序遍历和后序遍历归为一类,所用思想基本一模一样:
前序遍历的步骤为 :
①对root进行异常处理
②将root压入栈
③while循环遍历,终止条件为栈为空,所有元素均已处理完
④从栈顶取元素读,取并存入结果
⑤将取出元素的右、左节点分别压入栈内,以便下次循环取元素时为本次节点的左,右子节点.
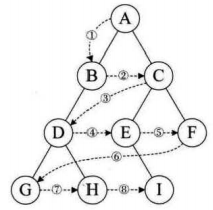
运用辅助栈,保存遍历到的节点(用栈后入先出的特性,控制已经遍历到的节点的访问顺序). 以前序深度优先遍历为例,先访问根节点,然后访问左树,左树全部访问完了,再访问右树
后续遍历思想: 左-右-根;可以视为, 根-右-左,然后结果转置即可. 如前面示意图,根右左,访问顺序则为:ACFBED;可以看出,这样访问刚好为后续遍历的转置. 根右左访问与前序(根左右)遍历操作思想一模一样
①前序遍历
/**
* 前序遍历,迭代法
*/
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null) return result;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null) stack.push(node.right); //先压入右节点,后出栈
if (node.left != null) stack.push(node.left); //后压入左节点,先出栈
}
return result;
}
②后序遍历
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if(root == null) return result;
Deque<TreeNode> stack=new ArrayDeque<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode node=stack.pop();
result.add(node.val); //结点添加顺序为 根右左
if(node.left!=null) stack.push(node.left);
if(node.right!=null) stack.push(node.right);
}
Collections.reverse(result); //反转为:左右根
return result;
}
③中序遍历
中序遍历思路: 中序遍历迭代法思路不同于前序和后序.
①首先针对对当前节点,一直对其左子树迭代并将非空节点入栈
②节点指针迭代为空(到树底了)后不再入栈,然后取栈顶元素,存结果;
③将当前指针用出栈的节点的右子节点替代,然后回到第一步继续迭代,直到当前节点为空且栈为空.
public List<Integer> inorderTraversal(TreeNode root){
List<Integer> result = new ArrayList<>();
if(root==null) return result;
Deque<TreeNode> stack = new ArrayDeque<>();
while (root!=null||!stack.isEmpty()){
while(root!=null){
stack.push(root);
root=root.left;
}
TreeNode node=stack.pop();
result.add(node.val);
root=node.right;
}
return result;
}
数据结构-二叉树(Binary Tree)的更多相关文章
- 数据结构-二叉树(Binary Tree)
#include <stdio.h> #include <string.h> #include <stdlib.h> #define LIST_INIT_SIZE ...
- 算法与数据结构基础 - 二叉树(Binary Tree)
二叉树基础 满足这样性质的树称为二叉树:空树或节点最多有两个子树,称为左子树.右子树, 左右子树节点同样最多有两个子树. 二叉树是递归定义的,因而常用递归/DFS的思想处理二叉树相关问题,例如Leet ...
- [Swift]LeetCode968.监控二叉树 | Binary Tree Cameras
Given a binary tree, we install cameras on the nodes of the tree. Each camera at a node can monitor ...
- 二叉树(Binary Tree)相关算法的实现
写在前面: 二叉树是比较简单的一种数据结构,理解并熟练掌握其相关算法对于复杂数据结构的学习大有裨益 一.二叉树的创建 [不喜欢理论的点我跳过>>] 所谓的创建二叉树,其实就是让计算机去存储 ...
- Python与数据结构[3] -> 树/Tree[0] -> 二叉树及遍历二叉树的 Python 实现
二叉树 / Binary Tree 二叉树是树结构的一种,但二叉树的每一个节点都最多只能有两个子节点. Binary Tree: 00 |_____ | | 00 00 |__ |__ | | | | ...
- Python数据结构——二叉树的实现
1. 二叉树 二叉树(binary tree)中的每个节点都不能有多于两个的儿子. 1.1 二叉树列表实现 如上图的二叉树可用列表表示: tree=['A', #root ['B', #左子树 ['D ...
- [数据结构]——二叉树(Binary Tree)、二叉搜索树(Binary Search Tree)及其衍生算法
二叉树(Binary Tree)是最简单的树形数据结构,然而却十分精妙.其衍生出各种算法,以致于占据了数据结构的半壁江山.STL中大名顶顶的关联容器--集合(set).映射(map)便是使用二叉树实现 ...
- 数据结构《9》----Threaded Binary Tree 线索二叉树
对于任意一棵节点数为 n 的二叉树,NULL 指针的数目为 n+1 , 线索树就是利用这些 "浪费" 了的指针的数据结构. Definition: "A binary ...
- [LeetCode] Serialize and Deserialize Binary Tree 二叉树的序列化和去序列化
Serialization is the process of converting a data structure or object into a sequence of bits so tha ...
随机推荐
- 睡前聊一聊"spring bean 生命周期"
spring bean 生命周期=实属初销+2个常见接口+3个Aware型接口+2个生命周期接口 实属初销:spring bean生命周期只有四个阶段,即实例化->属性赋值->初始化-&g ...
- 非关系型数据库Nosql的优缺点分析
Nosql的全称是Not Only Sql,Nosql指的是非关系型数据库,而我们常用的都是关系型数据库.就像我们常用的mysql,oralce.sqlserver等一样,这些数据库一般用来存储重要信 ...
- XCTF练习题---MISC---Training-Stegano-1
XCTF练习题---MISC---Training-Stegano-1 flag:steganoI 解题步骤: 1.观察题目,下载附件 2.打开下载的图片文件,发现就是一个点,修改文件扩展名,还是说查 ...
- 使用 docker-compose 部署 golang 的 Athens 私有代理
go中私有代理搭建 前言 为什么选择 athens 使用 docker-compose 部署 配置私有仓库的认证信息 配置下载模式 部署 使用秘钥的方式认证私有仓库 1.配置秘钥 2.配置 HTTP ...
- Keepalived入门学习
一个执着于技术的公众号 Keepalived简介 Keepalived 是使用C语言编写的路由热备软件,该项目软件起初是专门为LVS负载均衡设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后 ...
- 版本控制之git
1.Git的介绍 Git 是一个开源的分布式版本控制软件,用以有效.高速的处理从很小到非常大的项目版本管理. Git 最初是由Linus Torvalds设计开发的,用于管理Linux内核开发.Git ...
- 『现学现忘』Git基础 — 24、Git中查看历史版本记录
目录 1.查看详细的历史版本记录 2.简化显示历史版本记录 3.历史版本记录常用操作 (1)指定查看最近几次提交的内容 (2)以简单图形的方式查看分支版本历史 (3)翻页与退出 4.查看分支相关的版本 ...
- kvm 虚拟化技术 1.1 安装
1.·VMware开启虚拟化设置 2.安装一些虚拟化的必备插件 yum install -y qemu-kvm qemu-kvm-tools libvirt virt-manager virt-ins ...
- 189. Rotate Array - LeetCode
Question 189. Rotate Array Solution 题目大意:数组中最后一个元素移到第一个,称动k次 思路:用笨方法,再复制一个数组 Java实现: public void rot ...
- 143_Power BI&Power Pivot月度、季度、半年度、全年同维度展示
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一.背景 最近在做下一年度的预算,做出来需要月度.季度.半年度.全年都展示出来,在做测算的是时候,默认的透视表已经无法满足 ...