8.drf-序列化器
在序列化类中,如果想使用request,则可以通过self.context['request']获取
序列化器的主要由两大功能
- 对请求的数据进行校验(底层调用的是Django的Form和ModelForm)
- 对数据库查询的数据进行序列化
1.数据的校验
注意自定义的钩子函数中的参数value,对于FK或者M2M的字段,是一个对象而不是文本
1.1Serializer
基于Serializer类,类似Django中的Form
import re
from rest_framework.views import APIView
from rest_framework.views import Response
from rest_framework import serializers
from django.core.validators import EmailValidator class MyEmailValidator(object):
def __init__(self, base):
self.base = base def __call__(self, value):
match_object = re.match(self.base, value)
if not match_object:
raise serializers.ValidationError('格式错误') class UserSerializer(serializers.Serializer):
username = serializers.CharField(label='姓名', min_length=6, max_length=32)
age = serializers.IntegerField(label='年龄', min_value=0, max_value=200)
level = serializers.ChoiceField(choices=((1, '董事长'), (2, '经理'), (3, '员工')))
email1 = serializers.EmailField(label='邮箱1')
email2 = serializers.CharField(label='邮箱2', validators=[EmailValidator, ])
email3 = serializers.CharField(label='邮箱3')
email4 = serializers.CharField(label='邮箱4', validators=[MyEmailValidator(r"^w+@\w+\.\w+$")]) def validate_email3(self, value):
"钩子函数"
if not re.match(r"^w+@\w+\.\w+$", value):
raise serializers.ValidationError('格式错误')
return value class User(APIView):
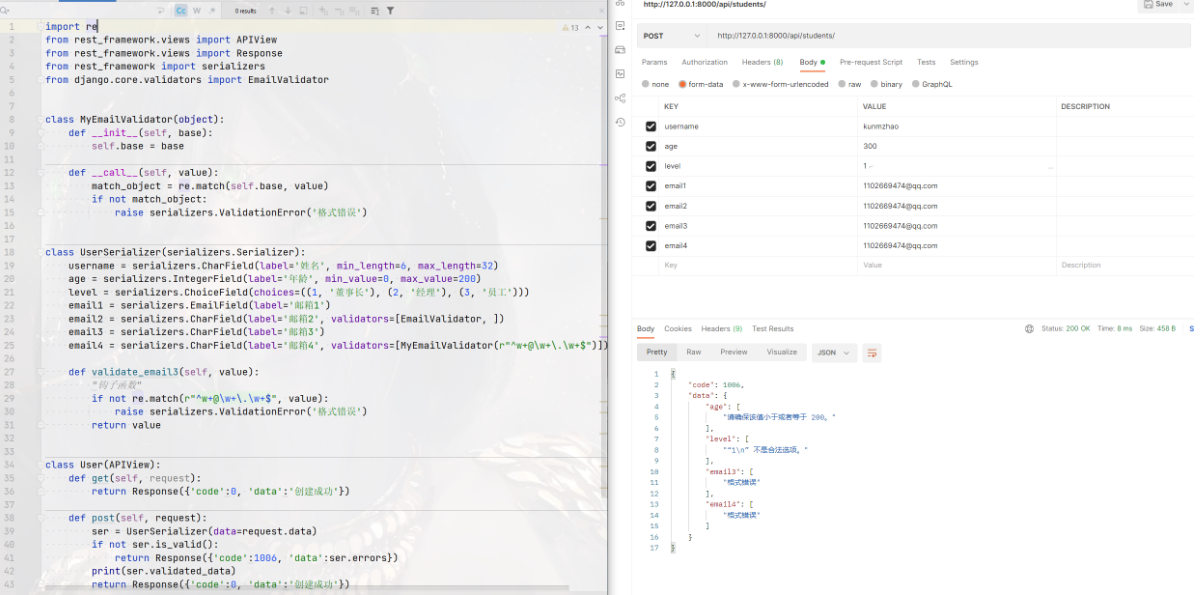
def get(self, request):
return Response({'code':0, 'data':'创建成功'}) def post(self, request):
ser = UserSerializer(data=request.data)
if not ser.is_valid():
return Response({'code':1006, 'data':ser.errors})
print(ser.validated_data)
return Response({'code':0, 'data':'创建成功'})
1.2 ModelSerializer
基于ModelSerializer类,类似Django中的ModelForm
import re
from rest_framework.views import APIView
from rest_framework.views import Response
from rest_framework import serializers class UserModelSerializer(serializers.ModelSerializer): class Meta:
model = UserInfo
# fields = '__all__'
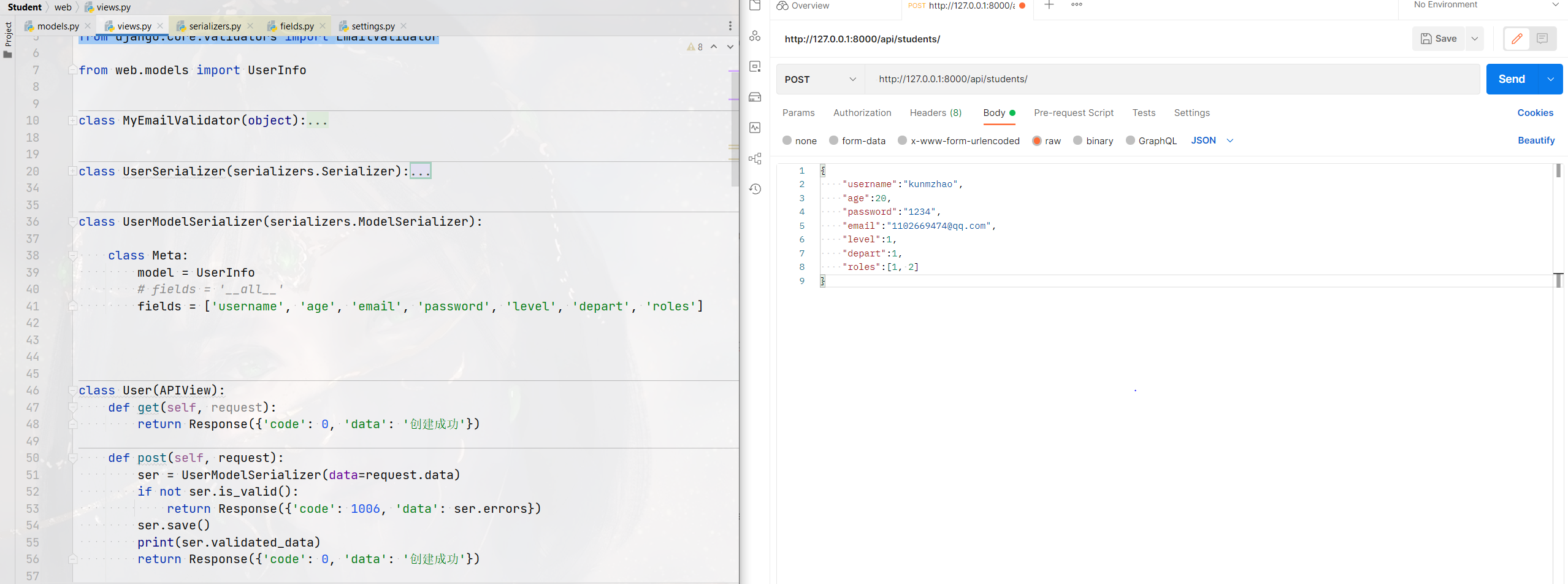
fields = ['username', 'age', 'email', 'password', 'level', 'depart', 'roles'] class User(APIView):
def get(self, request):
return Response({'code': 0, 'data': '创建成功'}) def post(self, request):
ser = UserModelSerializer(data=request.data)
if not ser.is_valid():
return Response({'code': 1006, 'data': ser.errors})
ser.save()
print(ser.validated_data)
return Response({'code': 0, 'data': '创建成功'})
2.序列化
通过ORM从数据库中获取QuerySet或者对象,然后序列化为json格式的数据
模型类
from django.db import models # Create your models here.
class Role(models.Model):
title = models.CharField(verbose_name='名称', max_length=32) class Department(models.Model):
title = models.CharField(verbose_name='名称', max_length=32) class UserInfo(models.Model):
level_choices = ((1, '普通会员'), (2, 'VIP'), (3, 'SVIP'))
level = models.IntegerField(verbose_name='级别', choices=level_choices, default=1) username = models.CharField(verbose_name='用户名', max_length=32)
password = models.CharField(verbose_name='密码', max_length=32)
age = models.IntegerField(verbose_name='年龄', default=18)
email = models.CharField(verbose_name='邮箱', max_length=64)
token = models.CharField(verbose_name='TOKEN', max_length=64, null=True, blank=True) depart = models.ForeignKey(verbose_name='部门', to='Department', null=True, blank=True, on_delete=models.CASCADE)
roles = models.ManyToManyField(verbose_name='角色', to="Role")
2.1 基本使用
序列化的是一个queryset,则many=True
序列化的是一个对象,则many=False
视图类
from rest_framework.views import APIView
from rest_framework.views import Response
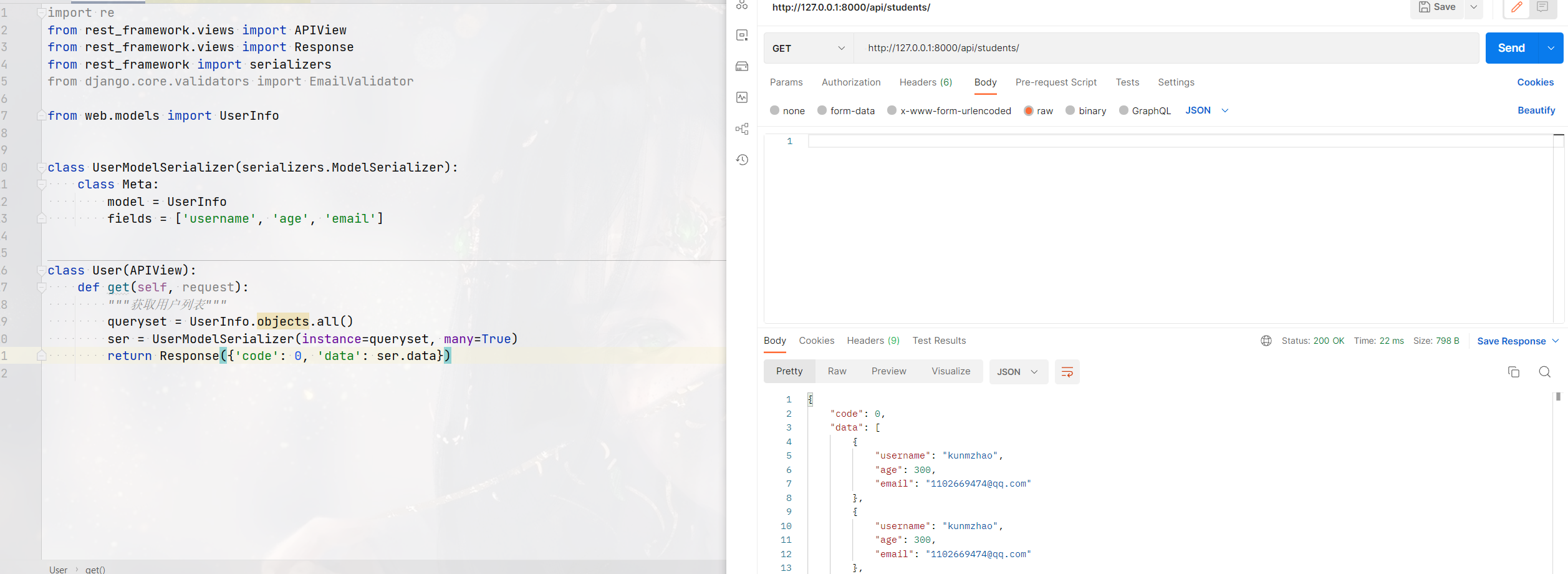
from rest_framework import serializers from web.models import UserInfo class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = UserInfo
fields = ['username', 'age', 'email'] class User(APIView):
def get(self, request):
"""获取用户列表"""
queryset = UserInfo.objects.all()
ser = UserModelSerializer(instance=queryset, many=True)
return Response({'code': 0, 'data': ser.data})
2.2 自定义字段
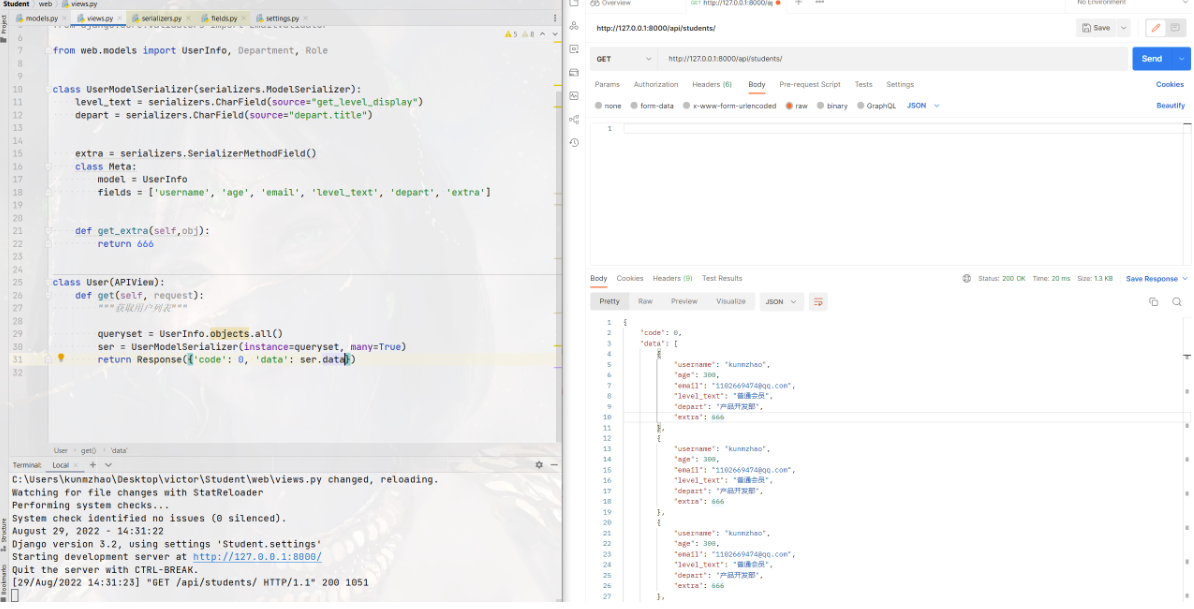
将数据库中的choice字段显示中文,如level_text
将ForeignKey字段显示,如depart
自定义字段,如extra,
如果类中自定义的字段名和数据库的一样,则覆盖掉数据库的字段,如depart
extra = serializers.SerializerMethodField()
def get_extra(self,obj):
return 666
1 from rest_framework.views import APIView
2 from rest_framework.views import Response
3 from rest_framework import serializers
4 from django.core.validators import EmailValidator
5
6 from web.models import UserInfo, Department, Role
7
8
9 class UserModelSerializer(serializers.ModelSerializer):
10 level_text = serializers.CharField(source="get_level_display")
11 depart = serializers.CharField(source="depart.title")
12
13
14 extra = serializers.SerializerMethodField()
15 class Meta:
16 model = UserInfo
17 fields = ['username', 'age', 'email', 'level_text', 'depart', 'extra']
18
19
20 def get_extra(self,obj):
21 return 666
22
23
24 class User(APIView):
25 def get(self, request):
26 """获取用户列表"""
27
28 queryset = UserInfo.objects.all()
29 ser = UserModelSerializer(instance=queryset, many=True)
30 return Response({'code': 0, 'data': ser.data})
2.3 序列化的嵌套
在一个序列化类中,可以嵌套另外一个序列化类
视图
import re
from rest_framework.views import APIView
from rest_framework.views import Response
from rest_framework import serializers
from django.core.validators import EmailValidator from web.models import UserInfo, Department, Role class DepartModelSerializer(serializers.ModelSerializer):
class Meta:
model = Department
fields = '__all__' class RoleModelSerializer(serializers.ModelSerializer):
class Meta:
model = Role
fields = '__all__' class UserModelSerializer(serializers.ModelSerializer):
depart = DepartModelSerializer()
roles = RoleModelSerializer(many=True) class Meta:
model = UserInfo
fields = ['username', 'age', 'email', 'depart', 'roles'] class User(APIView):
def get(self, request):
"""获取用户列表""" queryset = UserInfo.objects.all()
ser = UserModelSerializer(instance=queryset, many=True)
return Response({'code': 0, 'data': ser.data})
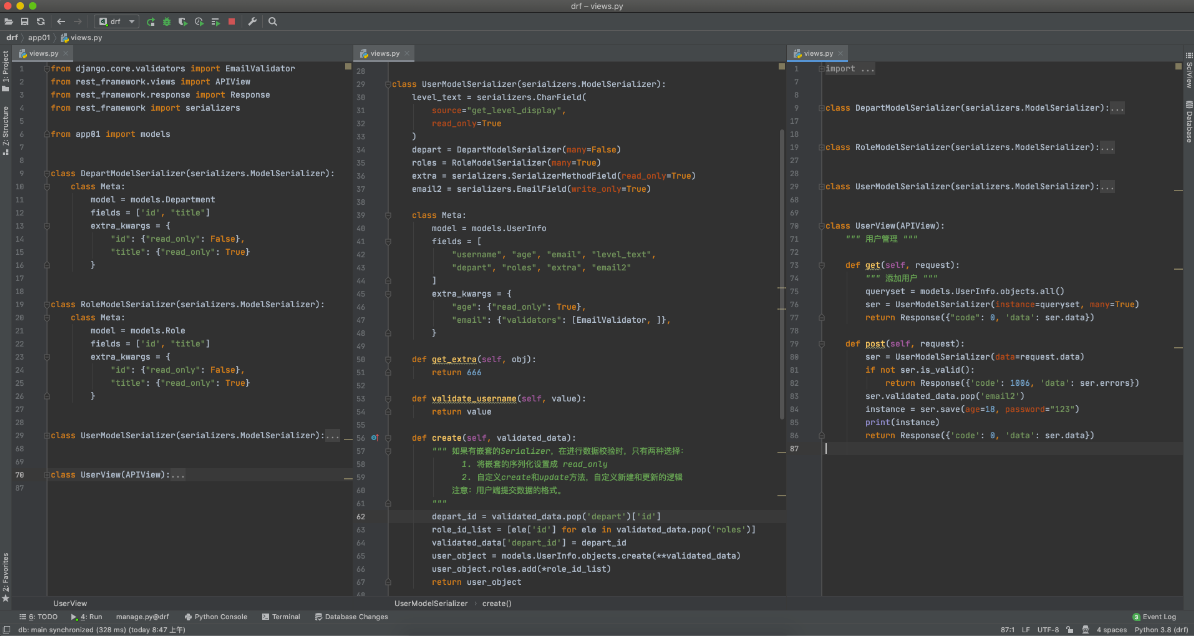
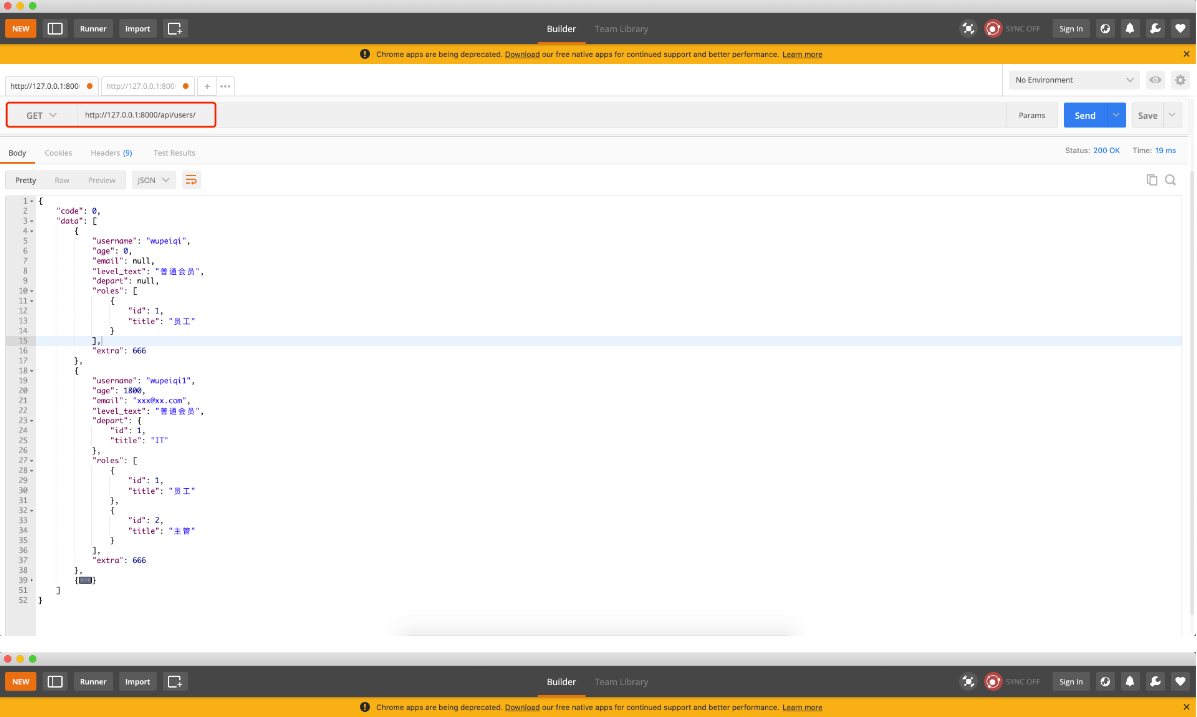
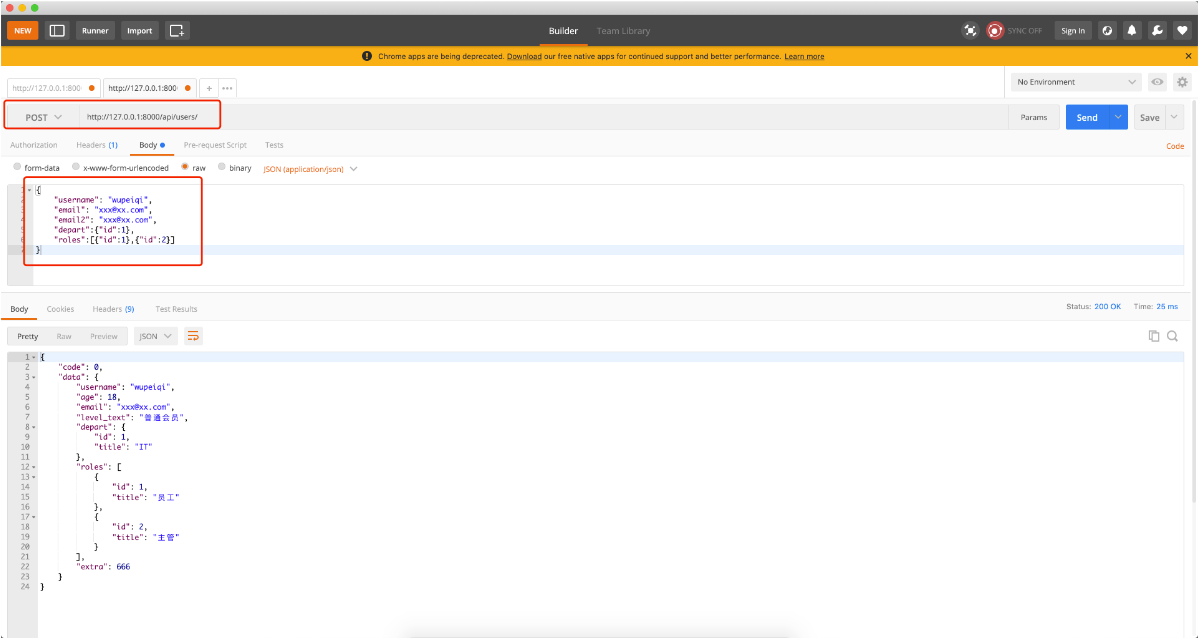
3.数据校验&序列化
有时候我们的序列化类可能既要序列化数据,也要校验数据,并且这是常有的,我们就需要给字段设置只读,只写或者可读可写来决定某个字段在序列化或者校验时是否使用本身
- read_only= True
- write_only = True
- 即可读也可写
注意:
如果有嵌套的Serializer,在进行数据校验时,只有两种选择:
1. 将嵌套的序列化设置成 read_only
2. 自定义create和update方法,自定义新建和更新的逻辑
4.源码分析
4.1 类的定义

4.2 序列化
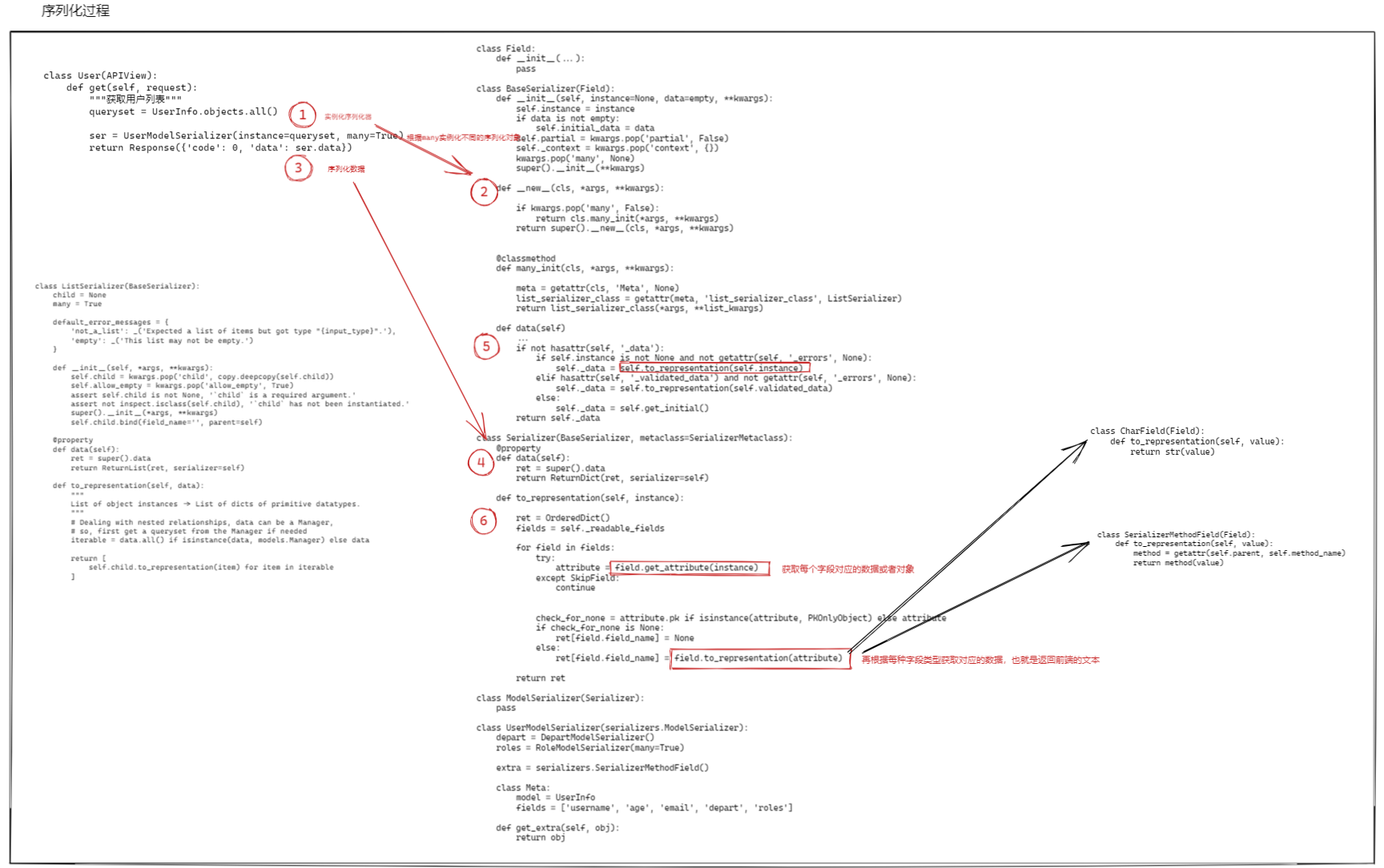
4.3 数据检验

4.4 数据保存

8.drf-序列化器的更多相关文章
- drf序列化器serializers.SerializerMethodField()的用法
问题描述: 为什么DRF中有时候返回的json中图片是带域名的,有时候是不带域名的呢? 解析: 带域名的结果是在view中对模型类序列化的,DRF在序列化图片的时候 会检查上下文有没有request, ...
- drf序列化器的实例
应用目录结构: views.py from django.shortcuts import render # Create your views here. from django.views imp ...
- DRF序列化器
序列化器-Serializer 作用: 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 反序列化,把客户端发送过来的数据,经过request以后变成字典 ...
- DRF序列化器的使用
序列化器的使用 序列化器的使用分两个阶段: 在客户端请求时,使用序列化器可以完成对数据的反序列化. 在服务器响应时,使用序列化器可以完成对数据的序列化. 序列化的基本使用 使用的还是上一篇博文中使用的 ...
- DRF 序列化器-Serializer (2)
作用 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 完成数据校验功能 3. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器 ...
- drf序列化器与反序列化
什么是序列化与反序列化 """ 序列化:对象转换为字符串用于传输 反序列化:字符串转换为对象用于使用 """ drf序列化与反序列化 &qu ...
- 对drf序列化器的理解
序列化: 将对象的状态信息转换为可以存储或传输的形式的过程.(百度定义) 对应到drf中,序列化即把模型对象转换为字典形式, 再返回给前端,主要用于输出 反序列化: 把其他格式转化为程序中的格式. 对 ...
- 关于定义序列化器时,read_only和write_only有什么作用
关于序列化和反序列化 在谈论前,先说一下序列化和反序列化,这两个概念最初是在学习json的时候提出来的,回头来看,其实可以用最初的理解就可以了 序列化就是将对象转化方便传输和存储字节序列,例如js ...
- 一: DRF web应用框架基础,及序列化器的使用
---恢复内容开始--- 一: web 应用模式(有两种) 1: 前后端不分离(前端从后端直接获取数据) 2: 前后端分离 二: api 接口 原因一: 为了在团队内部形成共识.防止个人习惯差异引起的 ...
- DRF中的序列化器
DRF中的序列化器详细应用 视图的功能:说白了就是接收前端请求,进行数据处理 (这里的处理包括:如果前端是GET请求,则构造查询集,将结果返回,这个过程为序列化:如果前端是POST请求,假如要对数 ...
随机推荐
- 最短路径算法-迪杰斯特拉(Dijkstra)算法在c#中的实现和生产应用
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径. 它的主要特点是以起始点为中心向外层层扩展(广度优先遍历思想),直到扩展到终点为止 贪心算法(Greedy ...
- KingbaseES 数据库大小写敏感特性
针对不同版本.是否启用大小写敏感,特征汇总如下:
- Golang 随机淘汰算法缓存实现
缓存如果写满, 它必须淘汰旧值以容纳新值, 最近最少使用淘汰算法 (LRU) 是一个不错的选择, 因为你如果最近使用过某些值, 这些值更可能被保留. 你如果构造一个比缓存限制还长的循环, 当循环最后的 ...
- C++程序的内存分布
4.文字常量区: p与p1的指针地址一致,且字符串常量是不能被改变的. 5.程序代码区:存放一系列代码. 动态内存 1.按需分配,根据需要分配内存,不浪费. 内存拷贝函数 void *memcpy(v ...
- 使用 Loki 收集 Traefik 日志
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247492264&idx=1&sn=f443c92664 ...
- SonarQube支持Gitlab授权登录
部署好SonarQube之后,由于我们内部使用的是自建的Gitlab仓库,即每个开发同学都有Gitlab账号,SonarQube我们就可以使用上Gitlab登录,这样就不需要再维护一套用户体系了. S ...
- 使用KVM的命令行方式安装centos7虚拟机
前提条件 1.宿主机上已经安装KVM软件,参考网址:https://www.cnblogs.com/sanduzxcvbnm/p/15538881.html 2.已经上传centos7镜像到宿主机里 ...
- 第六章:Django 综合篇 - 3:使用MySQL数据库
在实际生产环境,Django是不可能使用SQLite这种轻量级的基于文件的数据库作为生产数据库.一般较多的会选择MySQL. 下面介绍一下如何在Django中使用MySQL数据库. 一.安装MySQL ...
- k8s使用心得
查看当前所有namespaces [root@master ~]# kubectl get namespaces -A NAME STATUS AGE default Active 63d hkd A ...
- do...while循环体
基本语法 不要忘记while()后还需要加分号!!! 例(输出五句hello): int i = 1; //循环变量初始化 int max = 5; //循环的最大次数 do{ printf(&quo ...