【Hadoop】ZooKeeper组件
需要在Hadoop-全分布式配置的基础上进行配置
一、配置时间同步
(在所有节点上)
# 以master为例
# 安装chrony
[root@master ~]# yum -y install chrony
# 编辑配置文件
[root@master ~]# vi /etc/chrony.conf
server 0.time1.aliyun.com iburst
# 开启chronyd
[root@master ~]# systemctl restart chronyd
[root@master ~]# systemctl enable chronyd
Created symlink from /etc/systemd/system/multi-user.target.wants/chronyd.service to /usr/lib/systemd/system/chronyd.service.
# 查看状态
[root@master ~]# systemctl status chronyd
● chronyd.service - NTP client/server
Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2022-04-22 15:00:38 CST; 3min 31s ago
Process: 795 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS)
Process: 762 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 781 (chronyd)
CGroup: /system.slice/chronyd.service
└─781 /usr/sbin/chronyd
Apr 22 15:00:37 master.example.com systemd[1]: Starting NTP client/server...
Apr 22 15:00:37 master.example.com chronyd[781]: chronyd version 2.1.1 starting (+CMDMON +NT...H)
Apr 22 15:00:38 master.example.com chronyd[781]: Frequency 0.000 +/- 1000000.000 ppm read fr...ft
Apr 22 15:00:38 master.example.com systemd[1]: Started NTP client/server.
Hint: Some lines were ellipsized, use -l to show in full.
# 看到running则表示成功
二、部署zookeeper(master节点)
1、使用xftp上传软件包至~
2、解压安装包
[root@master ~]# tar xf zookeeper-3.4.8.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# mv zookeeper-3.4.8 zookeeper
3、创建 data 和 logs 文件夹
[root@master src]# cd /usr/local/src/zookeeper/
[root@master zookeeper]# mkdir data logs
4、写入该节点的标识编号
[root@master zookeeper]# echo '1' > /usr/local/src/zookeeper/data/myid
5、修改配置文件 zoo.cfg
[root@master zookeeper]# cd /usr/local/src/zookeeper/conf/
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
dataDir=/usr/local/src/zookeeper/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
# 表示三个 ZooKeeper 节点的访问端口号
6、配置环境变量zookeeper.sh
[root@master conf]# vi /etc/profile.d/zookeeper.sh
export ZOOKEEPER_HOME=/usr/local/src/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
7、修改目录的归属用户
[root@master conf]# chown -R hadoop.hadoop /usr/local/src/
8、拷贝文件到slave
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave1:/etc/profile.d/
zookeeper.sh 100% 87 0.1KB/s 00:00
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave2:/etc/profile.d/
zookeeper.sh 100% 87 0.1KB/s 00:00
9、修改目录的归属用户
# 在slave1节点
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
# 在slave2节点
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
10、写入每个节点的标识编号
# 在slave1节点
[root@slave1 ~]# echo '2' > /usr/local/src/zookeeper/data/myid
# 在slave2节点
[root@slave2 ~]# echo '3' > /usr/local/src/zookeeper/data/myid
三、启动 ZooKeeper
master节点
[root@master conf]# su - hadoop
Last login: Fri Apr 22 16:26:07 CST 2022 on pts/0
[hadoop@master ~]$ jps
43248 QuorumPeerMain
44316 Jps
# 看到QuorumPeerMain进程才表示成功
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
# 确保能够看到1个leader, 2个follower才表示启动成功
slave1节点
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 42747.
[hadoop@slave1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
slave2节点
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
四、部署HBase
步骤和【Hadoop】HBase组件配置步骤一样
只有hbase-env.sh配置文件下true改为false
vi hbase-env.sh
export JAVA_HOME=/usr/local/src/jdk
export HBASE_MANAGES_ZK=false
export HBASE_CLASSPATH=/usr/local/src/hadoop/etc/hadoop/
五、启动hadoop
# 在master上启动分布式hadoop集群
[hadoop@master ~]$ start-all.sh
[hadoop@master ~]$ jps
3210 Jps
2571 NameNode
2780 SecondaryNameNode
2943 ResourceManager
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2756 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3379 Jps
3239 NodeManager
3135 DataNode
#确保master上有NameNode、SecondaryNameNode、 ResourceManager进程, slave节点上要有DataNode、NodeManager进程
六、启动hbase
[hadoop@master ~]$ start-hbase.sh
[hadoop@master ~]$ jps
3569 HMaster
2571 NameNode
2780 SecondaryNameNode
3692 Jps
2943 ResourceManager
3471 HQuorumPeer
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2818 HQuorumPeer
2933 HRegionServer
3094 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3239 NodeManager
3705 Jps
3546 HRegionServer
3437 HQuorumPeer
3135 DataNode
# 确保master上有HQuorumPeer、HMaster进程,slave节点上要有HQuorumPeer、HRegionServer进程
七、查看浏览器页面
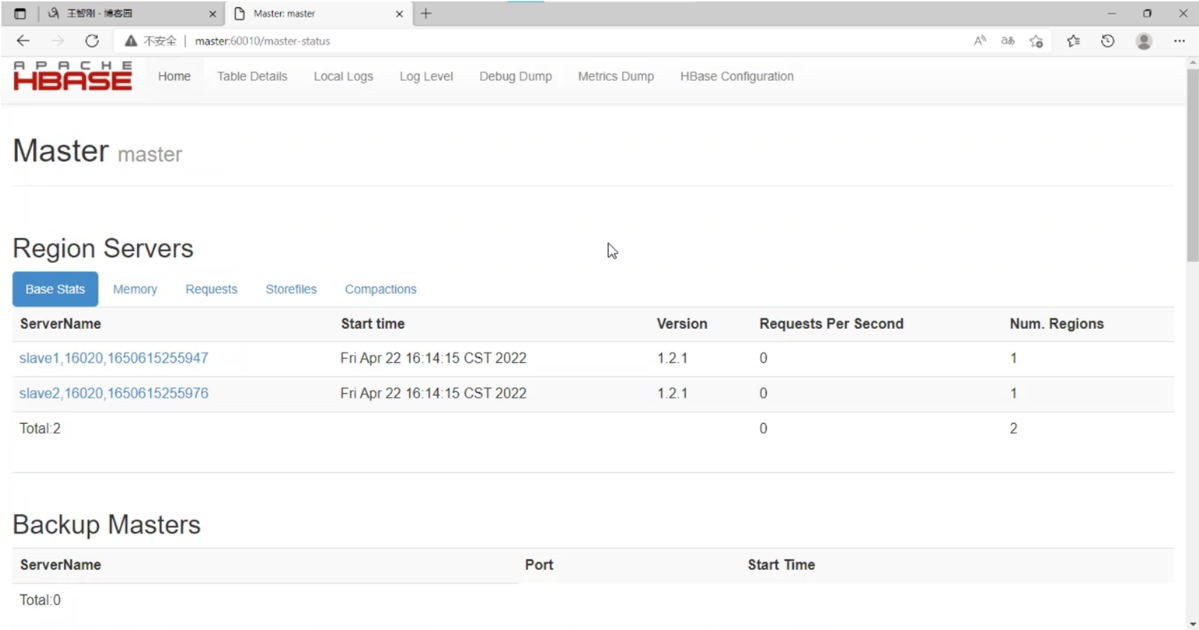
声明:未经许可,不得转载
【Hadoop】ZooKeeper组件的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
- ZooKeeper 组件安装配置
ZooKeeper 组件安装配置 下载和安装 ZooKeeper ZooKeeper最新的版本可以通过官网 http://hadoop.apache.org/zookeeper/ 来获取,安装 Zoo ...
- 安装hadoop+zookeeper ha
安装hadoop+zookeeper ha 前期工作配置好网络和主机名和关闭防火墙 chkconfig iptables off //关闭防火墙 1.安装好java并配置好相关变量 (/etc/pro ...
- HA分布式集群一hadoop+zookeeper
一:HA分布式配置的优势: 1,防止由于一台namenode挂掉,集群失败的情形 2,适合工业生产的需求 二:HA安装步骤: 1,安装虚拟机 1,型号:VMware_workstation_full_ ...
- hadoop+zookeeper+hbase分布式安装
前期服务器配置 修改/etc/hosts文件,添加以下信息(如果正常IP) 119.23.163.113 master 120.79.116.198 slave1 120.79.116.23 slav ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- (十七)整合 Zookeeper组件,管理架构中服务协调
整合 Zookeeper组件,管理架构中服务协调 1.Zookeeper基础简介 1.1 基本理论 1.2 应用场景 2.安全管理操作 2.1 操作权限 2.2 认证方式: 2.3 Digest授权流 ...
- Hadoop-HA 搭建高可用集群Hadoop Zookeeper
Hadoop Zookeeper 搭建(一) 一.准备工作 VMWARE虚拟机 CentOS 7 系统 虚拟机1:master 虚拟机2:node1 虚拟机3:node2 时间同步 ntpdate n ...
随机推荐
- ShardingSphere-Proxy(一)
1.现实中的问题 我们知道数据库的数据,基本80%的业务是查询,20%的业务涵盖了增删改,经过长期的业务变更和积累数据库的数据到达了一定的数量之后,直接影响的是用户与系统的交互,查询时的速度,插入数据 ...
- synchronized已经不在臃肿了,放下对他的成见之初识轻量级锁
前言 物竞天择,适者生存.JDK也在不断的优化中.关于JDK中synchronized锁内部也是不断的优化,前面我们分析了偏向锁用来解决初期问题,随着争抢的不断堆积轻量级锁营运而生. 关注我,一个不断 ...
- buu equation wp
知识点考察:jsfuck解码.js逆向.z3处理大量数据 源码分析 源码 根据提示猜测有jsfuck Jsfuck编码共六个字符分别为[.].+.!.(.) 观察上述不难发现l['jsfuck']=' ...
- 为什么操作 DOM 慢?
DOM本身是一个js对象, 操作这个对象本身不慢, 但是操作后触发了浏览器的行为, 如repaint和reflow等浏览器行为, 使其变慢
- 如何进行Hibernate的性能优化?
大体上,对于HIBERNATE性能调优的主要考虑点如下: l 数据库设计调整 l HQL优化 l API的正确使用(如根据不同的业务类型选用不同的集合及查询API) l 主配置参数(日志,查询缓存,f ...
- 数据库连接(Database link)?
在一个用户下,可以获取到另外的用户下的表的数据,通常在跨数据库时使用. create database link link93 connect to scott identified by tiger ...
- 什么是 ThreadLocal 变量?
ThreadLocal 是 Java 里一种特殊的变量.每个线程都有一个 ThreadLocal 就是每 个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了.它是为创建代价 高昂的对象获取线程安全 ...
- 两个相同的对象会有不同的的 hash code 吗?
不能,根据 hash code 的规定,这是不可能的.
- java支持多继承吗
java不支持多继承,只支持单继承(即一个类只能有一个父类).但是java接口支持多继承,即一个子接口可以有多个父接口.(接口的作用是用来扩展对象的功能,一个子接口继承多个父接口,说明子接口扩展了多个 ...
- Demo示例——Bundle打包和加载
Unity游戏里面的场景.模型.图片等资源,是如何管理和加载的? 这就是本文要讲的资源管理方式--bundle打包和加载. 图片 Unity游戏资源管理有很多方式: (1)简单游戏比如demo,可以直 ...