【爬虫+情感判定+Top10高频词+词云图】“谷爱凌”热门弹幕python舆情分析
一、背景介绍
最近几天,谷爱凌在冬奥会赛场上夺得一枚宝贵的金牌,为中国队贡献了自己的荣誉!
针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众网友弹幕的舆论导向,下面我们来看一下,是如何实现的分析过程。
二、代码讲解-爬虫部分
2.1 分析弹幕接口
首先分析B站弹幕接口。
经过分析,得到的弹幕地址有两种:
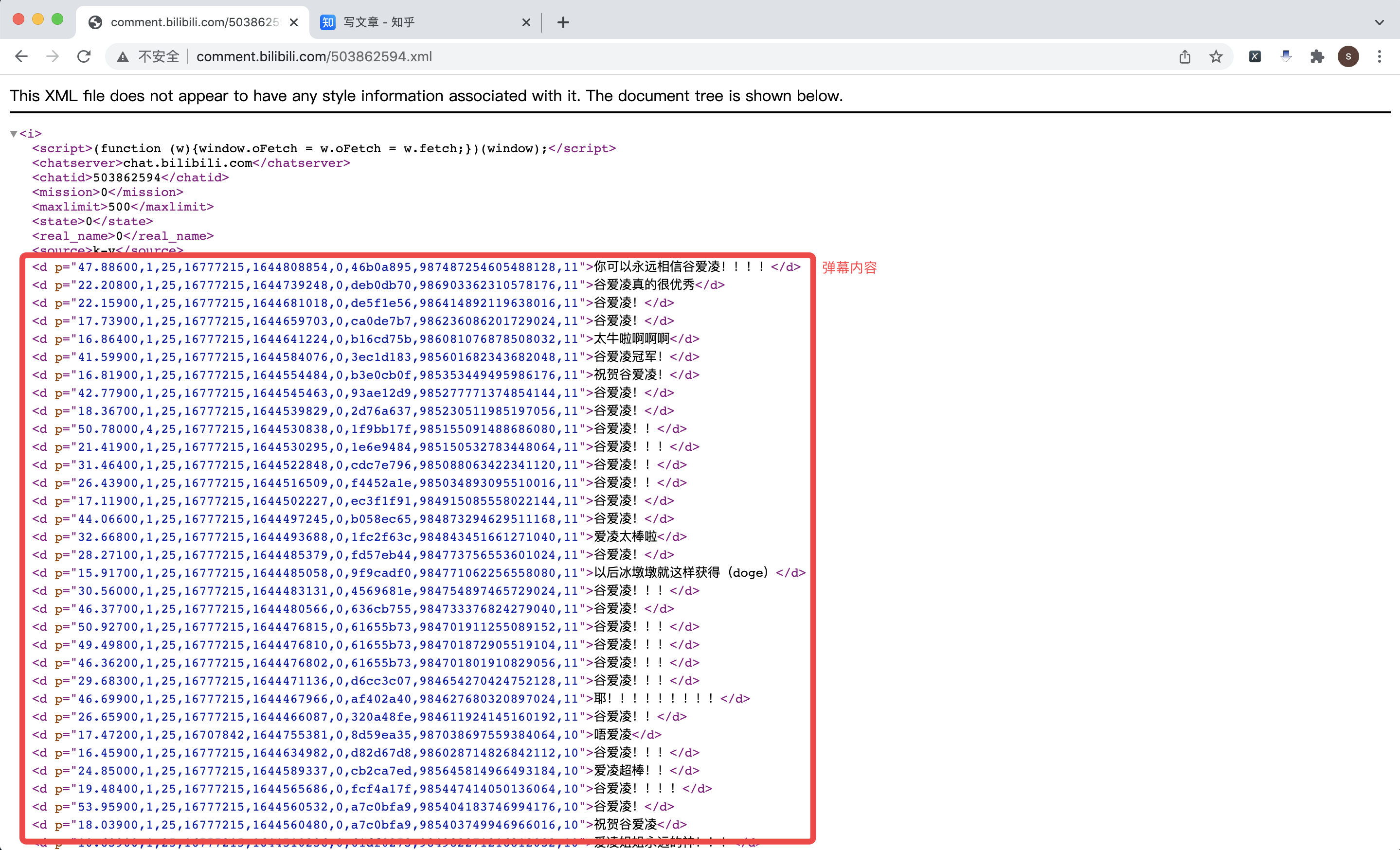
第一种:http://comment.bilibili.com/{cid}.xml
第二种:https://api.bilibili.com/x/v1/dm/list.so?oid={cid}
这两种返回的结果一致!但都不全,都是只有部分弹幕!
以视频 https://www.bilibili.com/video/BV1YY41157dk 为例,查看网页源代码,可以找到对应的cid为503862594,所以该视频对应的弹幕接口地址是:http://comment.bilibili.com/503862594.xml
既然这样,就好办了,开始撸代码!
2.2 讲解爬虫代码
首先,导入需要用到的库:
import re # 正则表达式提取文本
import requests # 爬虫发送请求
from bs4 import BeautifulSoup as BS # 爬虫解析页面
import time
import pandas as pd # 存入csv文件
import os
然后,向视频地址发送请求,解析出cid号:
r1 = requests.get(url=v_url, headers=headers)
html1 = r1.text
cid = re.findall('cid=(.*?)&aid=', html1)[0] # 获取视频对应的cid号
print('该视频的cid是:', cid)
根据cid号,拼出xml接口地址,并再次发送请求:
danmu_url = 'http://comment.bilibili.com/{}.xml'.format(cid) # 弹幕地址
print('弹幕地址是:', danmu_url)
r2 = requests.get(danmu_url)
解析xml页面:标签的文本内容为弹幕,标签内p属性值(按逗号分隔)的第四个字段是时间戳:
soup = BS(html2, 'xml')
danmu_list = soup.find_all('d')
print('共爬取到{}条弹幕'.format(len(danmu_list)))
video_url_list = [] # 视频地址
danmu_url_list = [] # 弹幕地址
time_list = [] # 弹幕时间
text_list = [] # 弹幕内容
for d in danmu_list:
data_split = d['p'].split(',') # 按逗号分隔
temp_time = time.localtime(int(data_split[4])) # 转换时间格式
danmu_time = time.strftime("%Y-%m-%d %H:%M:%S", temp_time)
video_url_list.append(v_url)
danmu_url_list.append(danmu_url)
time_list.append(danmu_time)
text_list.append(d.text)
print('{}:{}'.format(danmu_time, d.text))
保存时应注意,为了避免多次写入csv标题头,像这样:
这里,我写了一个处理逻辑,大家看注释,应该能明白:
if os.path.exists(v_result_file): # 如果文件存在,不需写入字段标题
header = None
else: # 如果文件不存在,说明是第一次新建文件,需写入字段标题
header = ['视频地址', '弹幕地址', '弹幕时间', '弹幕内容']
df.to_csv(v_result_file, encoding='utf_8_sig', mode='a+', index=False, header=header) # 数据保存到csv文件
三、代码讲解-情感分析部分
3.1 整体思路
针对情感分析需求,我主要做了三个步骤的分析工作:
- 用SnowNLP给弹幕内容打标:积极、消极,并统计占比情况
- 用jieba.analyse分词,并统计top10高频词
- 用WordCloud绘制词云图
首先,导入csv数据,并做数据清洗工作,不再赘述。
下面,正式进入情感分析代码部分:
3.2 情感分析打标
情感分析计算得分值、分类打标,并统计积极/消极占比。
# 情感分析打标
def sentiment_analyse(v_cmt_list):
"""
情感分析打分
:param v_cmt_list: 需要处理的评论列表
:return:
"""
score_list = [] # 情感评分值
tag_list = [] # 打标分类结果
pos_count = 0 # 计数器-积极
neg_count = 0 # 计数器-消极
for comment in v_cmt_list:
tag = ''
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.3:
tag = '消极'
neg_count += 1
else:
tag = '积极'
pos_count += 1
score_list.append(sentiments_score) # 得分值
tag_list.append(tag) # 判定结果
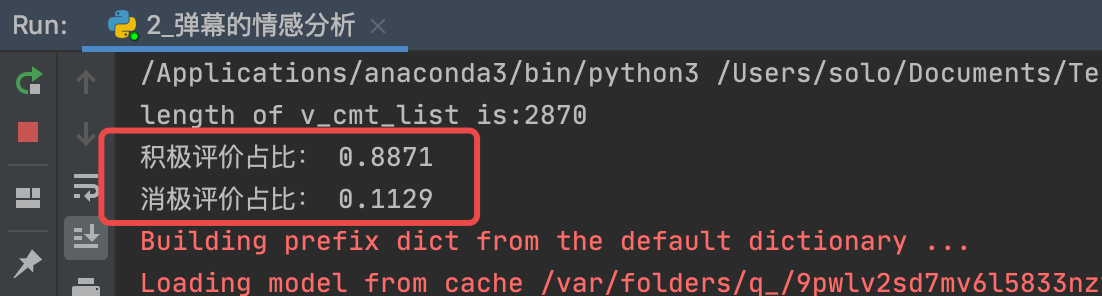
print('积极评价占比:', round(pos_count / (pos_count + neg_count), 4))
print('消极评价占比:', round(neg_count / (pos_count + neg_count), 4))
df['情感得分'] = score_list
df['分析结果'] = tag_list
# 把情感分析结果保存到excel文件
df.to_excel('谷爱凌_情感评分结果.xlsx', index=None)
print('情感分析结果已生成:谷爱凌_情感评分结果.xlsx')
这里,我设定情感得分值小于0.3为消极,否则为积极。(这个分界线,没有统一标准,根据数据分布情况和分析经验自己设定分界线即可)
占比结果:
打标结果:(最后两列,分别是得分值和打标结果)
3.3 统计top10高频词
# 2、用jieba统计弹幕中的top10高频词
keywords_top10 = jieba.analyse.extract_tags(v_cmt_str, withWeight=True, topK=10)
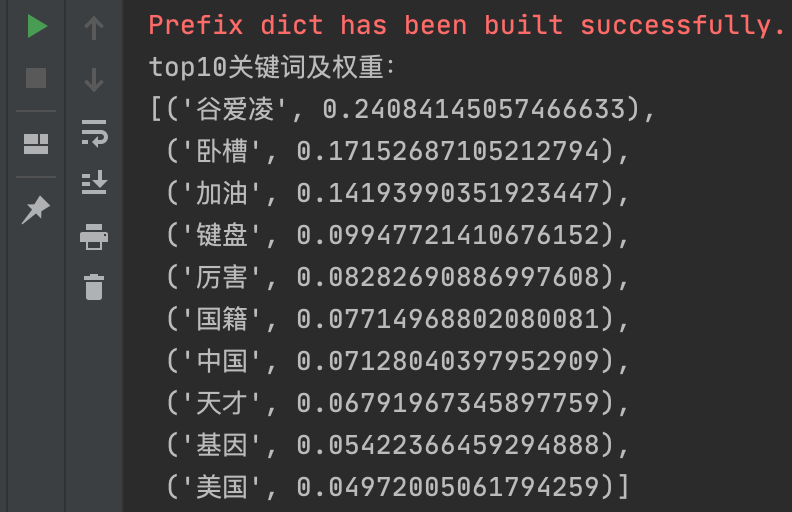
print('top10关键词及权重:')
pprint(keywords_top10)
这里需要注意,在调用jieba.analyse.extract_tags函数时,要导入的是import jieba.analyse 而不是 import jieba
统计结果为:(分为10组关键词及其权重,权重按倒序排序)
3.4 绘制词云图
注意别踩坑:
想要通过原始图片的形状生成词云图,原始图片一定要白色背景(实在没有的话,PS修图修一个吧),否则生成的是满屏词云!!
def make_wordcloud(v_str, v_stopwords, v_outfile):
"""
绘制词云图
:param v_str: 输入字符串
:param v_stopwords: 停用词
:param v_outfile: 输出文件
:return: None
"""
print('开始生成词云图:{}'.format(v_outfile))
try:
stopwords = v_stopwords # 停用词
backgroud_Image = np.array(Image.open('谷爱凌背景图.png')) # 读取背景图片
wc = WordCloud(
background_color="white", # 背景颜色
width=1500, # 图宽
height=1200, # 图高
max_words=1000, # 最多字数
font_path='/System/Library/Fonts/SimHei.ttf', # 字体文件路径,根据实际情况(Mac)替换
# font_path="C:\Windows\Fonts\simhei.ttf", # 字体文件路径,根据实际情况(Windows)替换
stopwords=stopwords, # 停用词
mask=backgroud_Image, # 背景图片
)
jieba_text = " ".join(jieba.lcut(v_str)) # jieba分词
wc.generate_from_text(jieba_text) # 生成词云图
wc.to_file(v_outfile) # 保存图片文件
print('词云文件保存成功:{}'.format(v_outfile))
except Exception as e:
print('make_wordcloud except: {}'.format(str(e)))
得到的词云图:

和原始背景图对比:

3.5 情感分析结论
- 打标结果中,积极评价占0.8871,远远大于消极评价!
- top10关键词统计结果中,"加油"、"厉害"、"天才"等好评词汇占据多数!
- 词云图中,"中国"、"好"、"厉害"、"卧槽"等好评词看上去更大(词频高)!
综上所述,经分析"谷爱凌"相关弹幕,得出结论:
众多网友对谷爱凌的评价都很高,也很喜欢她,毕竟不但年轻、颜值高、有才华,还能为祖国争得宝贵的荣誉!
致敬!!
四、同步讲解视频
上集:(爬虫采集)
https://www.zhihu.com/zvideo/1476299216318857217
下集:(情感分析)
https://www.zhihu.com/zvideo/1476300807759294464
by 马哥python说
【爬虫+情感判定+Top10高频词+词云图】“谷爱凌”热门弹幕python舆情分析的更多相关文章
- 【爬虫+情感判定+Top10高频词+词云图】“刘畊宏“热门弹幕python舆情分析
一.背景介绍 最近一段时间,刘畊宏真是火出了天际,引起一股全民健身的热潮,毕竟锻炼身体,是个好事! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众多网友弹幕的舆论 ...
- 【爬虫+情感判定+Top10高频词+词云图】"王心凌"热门弹幕python舆情分析
目录 一.背景介绍 二.代码讲解-爬虫部分 2.1 分析弹幕接口 2.2 讲解爬虫代码 三.代码讲解-情感分析部分 3.1 整体思路 3.2 情感分析打标 3.3 统计top10高频词 3.4 绘制词 ...
- python爬虫之採集——360联想词W2版本号
http://blog.csdn.net/recsysml/article/details/30541197,我的这个博文介绍了对应的简单的方法做一个联想词的爬虫,并且还承诺了下面优化: 下一版本号的 ...
- python爬虫实践--求职Top10城市
前言 从智联招聘爬取相关信息后,我们关心的是如何对内容进行分析,获取用用的信息.本次以上篇文章“5分钟掌握智联招聘网站爬取并保存到MongoDB数据库”中爬取的数据为基础,分析关键词为“python” ...
- 孤荷凌寒自学python第八十天开始写Python的第一个爬虫10
孤荷凌寒自学python第八十天开始写Python的第一个爬虫10 (完整学习过程屏幕记录视频地址在文末) 原计划今天应当可以解决读取所有页的目录并转而取出所有新闻的功能,不过由于学习时间不够,只是进 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
- 孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6
孤荷凌寒自学python第七十六天开始写Python的第一个爬虫6 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 不过由于对python-docx模 ...
随机推荐
- Redis String Type
Redis字符串的操作命令和对应的api如下: set [key] [value] JedisAPI:public String set(final String key, final String ...
- 什么是 Spring 的依赖注入?
依赖注入,是 IOC 的一个方面,是个通常的概念,它有多种解释.这概念是说你 不用创建对象,而只需要描述它如何被创建.你不在代码里直接组装你的组件和 服务,但是要在配置文件里描述哪些组件需要哪些服务, ...
- ionic3 ion-input进入页面自动获取焦点
在项目需求中,有需要用到输入框在进入这个页面的时候就自动定位获取这个输入框的焦点. 查了许多资料,也问了ionic3的大神,现将知识点记录如下: 1.能不能直接设置ion-input的属性值来达到自动 ...
- python-for循环跳过第一行
代码: for i in data[1:]: 即可跳过第一行
- parseFloat的取值
<script type="text/javascript"> document.write(parseFloat("10")) document. ...
- 小程序滚动事件之头部渐隐渐现demo
效果图: ==> 代码: //test1.wxml <view class='header' style="opacity:{{opacityStyle}}" hid ...
- 记一次使用git报错,解决Unable to negotiate with **** port 22: no matching host key type found. Their offer: ssh-rsa
windows电脑重装系统,去官网下载了最新的git安装,一路next下来,打开bash按老路子设置,生成公钥 git config --global user.name "yourname ...
- 麒麟系统开发笔记(三):从Qt源码编译安装之编译安装Qt5.12
前言 上一篇,是使用Qt提供的安装包安装的,有些场景需要使用到从源码编译的Qt,所以本篇如何在银河麒麟系统V4上编译Qt5.12源码. 银河麒麟V4版本 系统版本: Qt源码下载 ...
- 一个程序的执行时间可以使用time+命令形式来获得
编写程序testtime.c #include <stdio.h> //这个头一定要加 #include<time.h> main() { time_t timep; time ...
- Win下GCC报错 error: ‘for’ loop initial declarations are only allowed in C99 mode
##报错## 用GCC编译for循环会出现以下错误 error: 'for' loop initial declarations are only allowed in C99 mode 如图所示: ...